







Apache Zeppelin
什么是Zeppelin
Apache Zeppelin是一个高性能,高可用,高可靠的分布式Key-Value存储与可视化平台,它是集数据摄取,数据分析,数据可视化与协作于一身的notebook形式的基于Web的工具,支持多种解释器(Interpreter),能广泛支持多种大数据查询引擎和计算引擎(如Spark,Flink,Presto,Kylin…),多种存储系统(如JDBC数据源,HBase,Elasticsearch,Hive,Neo4j,Alluxio,Ignite…),以及多种脚本语言(如python,scala,R,shell…)和markdown。
Apache Zeppelin支持的部分组件:
Zeppelin优势
- 为数据分析与可视化提供便利:在Zeppelin中以笔记本(notebook)的形式组织和管理交互式数据探索任务,一个笔记本(note)可以包括多个段(paragraph)。段是进行数据分析的最小单位,即在段中可以完成数据分析代码的编写以及结果的可视化查看
- 为多人协作提供便利:可以共享你的notebook,使他人也能看到你的数据分析笔记和结果
- 提供权限管理:可以管理notebook的权限以及执行者是否对已有数据有修改权限
- 支持多种查询计算引擎:兼容多种主流大数据查询,计算引擎,使得数据分析更加方便,数据分析人员可以对底层无感知
- 为临时获取某些数据提供便利:有需要临时获取一些数据的需求,通过配置Interpreter即可
- 配置与部署简单:已完全支持的组件只需简单填写解释器参数即可使用,支持安装第三方解释器
- 支持简单任务调度:Linux Crontab调度器功能
Zeppelin适用场景
- 多个部门需要在大数据平台取数据做分析的场景
- 需要多种查询引擎做数据分析的场景
- 需要对多种数据源进行数据可视化的场景
- 需要多人协作的场景
- 数据平台与数据分析分离,对数据分析人员无感知的场景
Zeppelin详细
解释器Interpreters(重要)
Zeppelin Interpreter是一个插件,允许将支持的语言/数据处理后端插入Zeppelin。
通过简单的配置即可将语言/数据处理查询后端接入Zeppelin。
Zeppelin解释器
Zeppelin-Spark解释器
Notebook
Zeppelin的工作簿(Notebook)支持分为多个段,每段支持绑定多个不同的解释器,支持做单独处理和执行不同的操作,结果会一直被保留,可以选择让其他人浏览或者修改。
Notebook提供给数据分析人员的前端工作环境,方便数据分析和数据可视化。
Interpreter Group
解释器组:默认情况下,每个解释器属于一个解释器组,一个解释器组可能包含多个解释器
同一InterpreterGroup中的Interpreter可以相互引用
例如Spark解释器组包括Spark支持,PSpark,SparkSql和其他依赖项
同一解释器组中的Zeppelin程序在同一JVM运行
解释器组是开启、停止解释器运行的基本单位。(同时开启,停止)
Interpreter binding mode
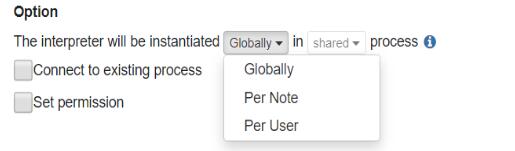
解释器绑定模式:可选’shared’, ‘scoped’, ‘isolated’ 其一
shared:共享模式,绑定解释器的每个Notebook共享单个解释器实例(方便不同Notebook间共享变量,但资源利用率低)
scoped:作用域模式,在相同解释器程序中创建新的解释器实例(每个Notebook拥有自己的回话,资源利用率略高,不能直接共享变量)
isolated:隔离模式,每个Notebook创建新的解释器程序(笔记本之间互不影响,不能直接共享变量)
比如shared模式下,每个Notebook都可以使用SparkInterpreter但是只有一个SparkContext
如果isolated模式,每个Notebook都可以使用SparkInterpreter但每个Notebook有单独的SparkContext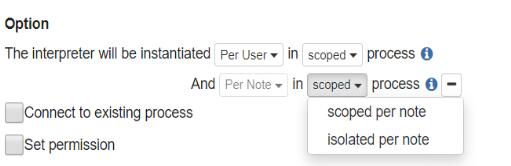
Interpreter生命周期
Zeppelin 0.8.0以后支持LifecycleManager来控制解释器生命周期(之前是关闭UI界面后生命周期结束)
NullLifecycleManager不做操作,要像以前一样自行控制生命周期
TimeoutLifecycleManager(默认生命周期管理)默认超过1小时关闭解释器,可以更改
Generic ConfInterpreter
Zeppelin解释器配置由所有用户和Notebook共享,如果想使用其他的设置,需要创建新的解释器,能实现但不方便,ConfInterpreter可以提供对解释器设置的更细粒度的控制和更大的灵活性。
ConfInterpreter是可以被任何解释器使用的通用解释器,输入格式应为属性文件格式。它用于为任何解释器进行自定义设置。
用户需要将ConfInterpreter放在Notebook的第一段
如上图%spark.conf独立设置了该Notebook中的Spark解释器
Interpreter进程恢复
0.8.0版本前,关闭Zeppelin会同时关闭所有正在运行的解释器程序,但是我们可能只是想维护Zeppelin服务器而不想关闭解释器程序,Interpreter进程恢复就派上用场了。
0.8.0版本后,设置zeppelin.recovery.storage.class属性的值默认org.apache.zeppelin.interpreter.recovery.NullRecoveryStorage不开启进程恢复
设置为org.apache.zeppelin.interpreter.recovery.FileSystemRecoveryStorage开启进程恢复,关闭Zeppelin不会关闭解释器程序
如果开启了进程恢复,关闭了Zeppelin,又想再关闭解释器程序,则执行bin/stop-interpreter.sh
官方文档
常见问题及错误排除
- *Interpreter ** is not found**:检查是否已经配置了该解释器,如果配置了,检查该解释器是否已被点亮(右上角设置图标点为蓝色并保存)
详细深入了解: Apache Zeppelin官网



