







Impala-基于内存的高效SQL交互查询引擎
Impala简介
Impala是Cloudera提供的一款高效率的SQL实时查询工具,官方测试性能比Hive快10到100倍,SQL查询性能甚至比SparkSQL还更加高效。Impala是基于Hive的大数据分析查询引擎,直接使用Hive的元数据库,意味着Impala元数据都存储在Hive的元数据库当中。Impala兼容绝大多数HiveQL语法。
Impala基于MPP(Massively Parallel Processing)[大规模并行处理]理念的查询引擎,什么是MPP?
MPP是一种海量数据实时分析架构,MPP理念是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果
特点:
● Shared Nothing架构(每一个节点都是独立的,自给的,在系统中不存在单点竞争,没有共享数据),私有资源
● 任务分布式并行执行(数据无共享,无IO冲突,无锁资源竞争,计算速度快)
● 数据分布式存储(本地化)
● 横向扩展(易扩容);
● 单个节点查询效率慢会影响整个查询(倾斜)
附:
Shared Everthing:完全透明共享 CPU/Memory/IO,并行处理能力是最差的
Shared Storage:各个处理单元使用自己的私有CPU//Memory,但共享磁盘系统
Shared Nothing:各个处理单元都有自己私有的CPU/Memory/IO基于SQL的计算引擎对比
| 引擎 | 开发语言 | 执行机制 | 资源调度 | 内存分配 | 容错 | 场景 |
|---|---|---|---|---|---|---|
| Hive(MR) | Java | SQL->MR->Yarn->HDFS | Yarn调度 | 内存不够则用磁盘 | Hadoop容错机制包括重试和推测执行 | 离线分析和跑批任务 |
| Spark | Scala | SQL->计划->Yarn->HDFS | 支持多种调度 | 优先使用内存不够则用磁盘,可手动 | Lineage+Checkpoint+失败重试 | 兼容多种场景 |
| Presto | Java | SQL->计划->Workers->HDFS | 自身 | 纯内存计算 | 无容错设计 | 交互式分析查询 |
| ClickHouse | C++ | SQL->计划->读存储引擎数据向量化执行 | 自身 | 内存+连续IO | 多主机跨数据中心异步复制,不怕节点宕机 | 存储数据库+OLAP分析的场景 |
| Impala | C++ | SQL->计划->HDFS | 自身 | 纯内存计算 | 无容错设计 | 交互式分析查询 |
Impala优缺点
优点:
- 基于内存计算,低延迟,高吞吐,查询速度快,适用于秒级响应的OLAP交互式分析查询
- 提供窗口函数(聚合 OVER PARTITION, RANK, LEAD, LAG, NTILE等等)以支持高级分析功能
- 支持PB级数据量的实时分析
- 支持map、struct、array类型上的复杂嵌套查询,支持UDF和UDAF
- 可以使用Impala插入或更新HBase(类似Phoenix)
- 支持Parquet、Avro、Text、RCFile、SequenceFile、HFile等多种文件格式,支持Snappy(有效平衡压缩率和解压缩速度)、Gzip(最高压缩率的归档数据压缩)、Deflate(不支持文本文件)、Bzip2、LZO(只支持文本文件)等多种压缩编码格式
- 支持存储在HDFS、HBase、S3、Kudu上的数据操作
- 与CDH深度整合,支持查看查询任务的各项指标
- 支持Sentry和Kerberos
局限性:
- 不适用于跑批
- 查询时占用大量内存
- 不支持ORC
- “AnalysisException: Impala does not support modifying a non-Kudu table” 不支持非Kudu表的Update、delete操作
- 不支持Date数据类型
Impala原理
Impala架构图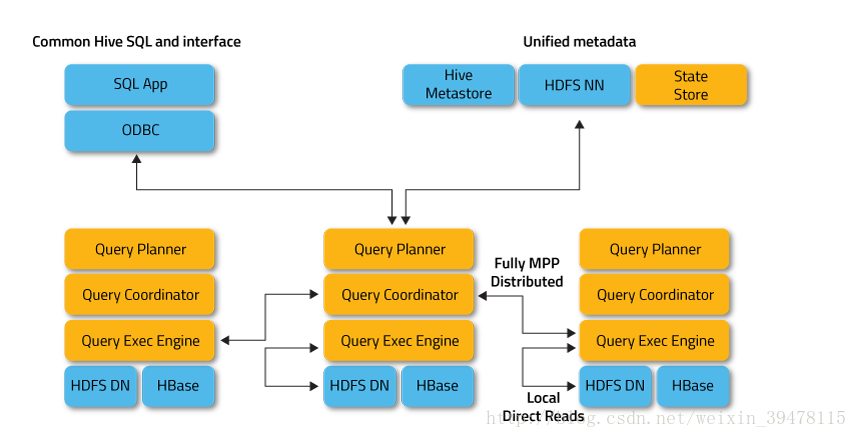
Impala Daemon
Impala的核心进程Impalad,部署在所有的数据节点上,接收客户端的查询请求,读写数据,并行执行来自集群中其他节点的查询请求,将中间结果返回给调度节点。调用节点将结果返回给客户端。Impalad进程通过持续与StateStore通信来确认自己所在的节点是否健康以及是否可以接受新的任务请求。
Impalad包含三种角色:
- Query Coordinator:用户在Impala集群上的某个节点提交数据处理请求(例如impala-shell提交SQL),则该Impalad节点称为Coordinator Node(协调节点),负责定位数据位置,拆分请求(Fragment),将任务分解为多个可并行执行的小请求,发送这些请求到多个Query Executor,接收Query Executor处理后返回的数据并构建最终结果返回给用户。
- Query Planner:Java编写的,解析SQL生成QueryPlanTree执行计划树。
- Query Executor:执行数据计算,比如scan,Aggregation,Merge等,返回数据。
Impala StateStore
Statestored进程,状态管理进程(类似ZK),定时检查Impala Daemon的健康状况,协调各个运行Impalad进程之间的信息,Impala通过这些信息去定位查询请求所要的数据,如果Impala节点下线,StateStore会通知其他节点,避免查询任务分发到不可用的节点上。(定位Impala卡住以及各种异常状况,可以先从ImpalaStateStore下手,查看StateStore日志方便定位问题)
Impala Catalog Service
Catalogd进程,元数据管理服务,收集Hive等系统的元数据,将数据表变化的信息分发给各个进程。接收来自StateStore的所有请求,每个Impala节点在本地缓存所有元数据。当表创建、数据更新或Schema发生变化时,其他Impala后台进程必须更新元数据缓存,才能查询。
- Schema变化时(Hive操作create table/drop table/alter table add columns)使用:
invalidate metadata //重新加载所有库中的所有表(不推荐,还不如重启Catalogd进程)
invalidate metadata [table] //重新加载指定的某个表 - 数据变化时(Hive操作insert into、load data、alter table add partition、Alter table drop partition或HDFS增删重命名文件)使用:
refresh [table] //刷新某个表
refresh [table] partition [partition] //刷新某个表的某个分区 - 注意:invalidate会清除表的缓存并从MetaStore重新同步元数据,代价较大;refresh会重用之前的元数据,仅仅执行文件刷新操作,它能够检测到表中分区的增加和减少,代价相对小些
Impala join算法
1.HashJoin,等值Join采用Hash算法进行Join,具体分为Broadcast Hash Join和Shuffle Hash Join。Boradcast Join适合右表是小表的情景,Impala会广播小表到各个节点,再关联。Shuffle Join适合大表与大表Join的情景,Impala会将大表划分成多块,然后分别进行Hash Join。
2.Nested Loop Join,非等值Join使用,非等值Join效率低,不支持Hint。
Impala Query Hint
语法:
SELECT STRAIGHT_JOIN select_list FROM
join_left_hand_table
JOIN [{ /* +BROADCAST */ | /* +SHUFFLE */ }]
join_right_hand_table
remainder_of_query;
-- --------------------------------------
INSERT insert_clauses
[{ /* +SHUFFLE */ | /* +NOSHUFFLE */ }]
[/* +CLUSTERED */]
SELECT remainder_of_query;
-- --------------------------------------
SELECT select_list FROM
table_ref
/* +{SCHEDULE_CACHE_LOCAL | SCHEDULE_DISK_LOCAL | SCHEDULE_REMOTE}
[,RANDOM_REPLICA] */
remainder_of_query;Hint会改变SQL的执行计划,使用Hint注意事项:
- 有两个地方需要加上hint关键字,select后面加上STRAIGHT_JOIN;join后面加上[shuffle]或者/* +shuffle */
- 如果是多层嵌套的join方式,也需要在每一层加上STRAIGHT_JOIN和[shuffle]或者/* +shuffle */
- 外层的hint对于内层的join子语句是不起作用的
- 如果select后面跟distinct之类的关键字,STRAIGHT_JOIN需要跟在关键字后面
不同Hint标签的具体含义和场景见文档:impala_hints
在CDH使用Impala
Impala相关进程: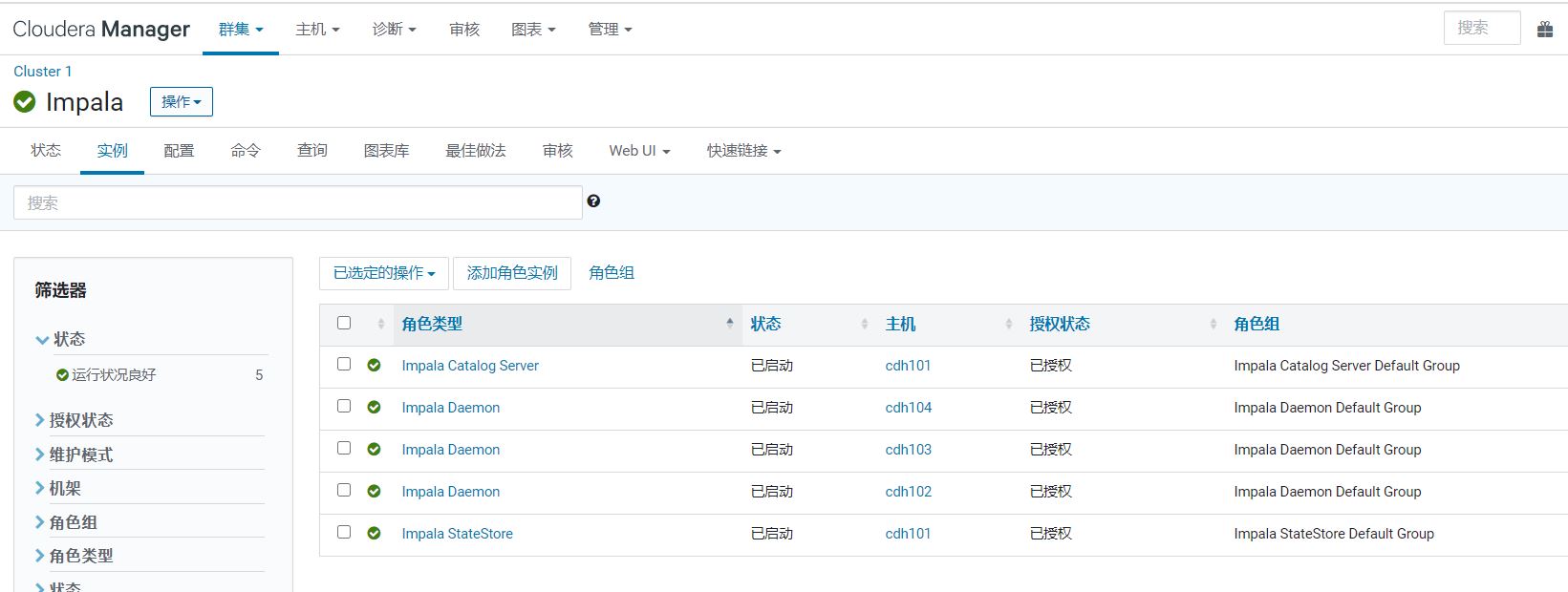
注意:考虑集群性能,一般将StateStore与CatalogService放在同一节点上,因之间要做通信
在StateStore的WEBUI http://cdh101:25010/ 可以查看Impala集群监控状态和配置信息: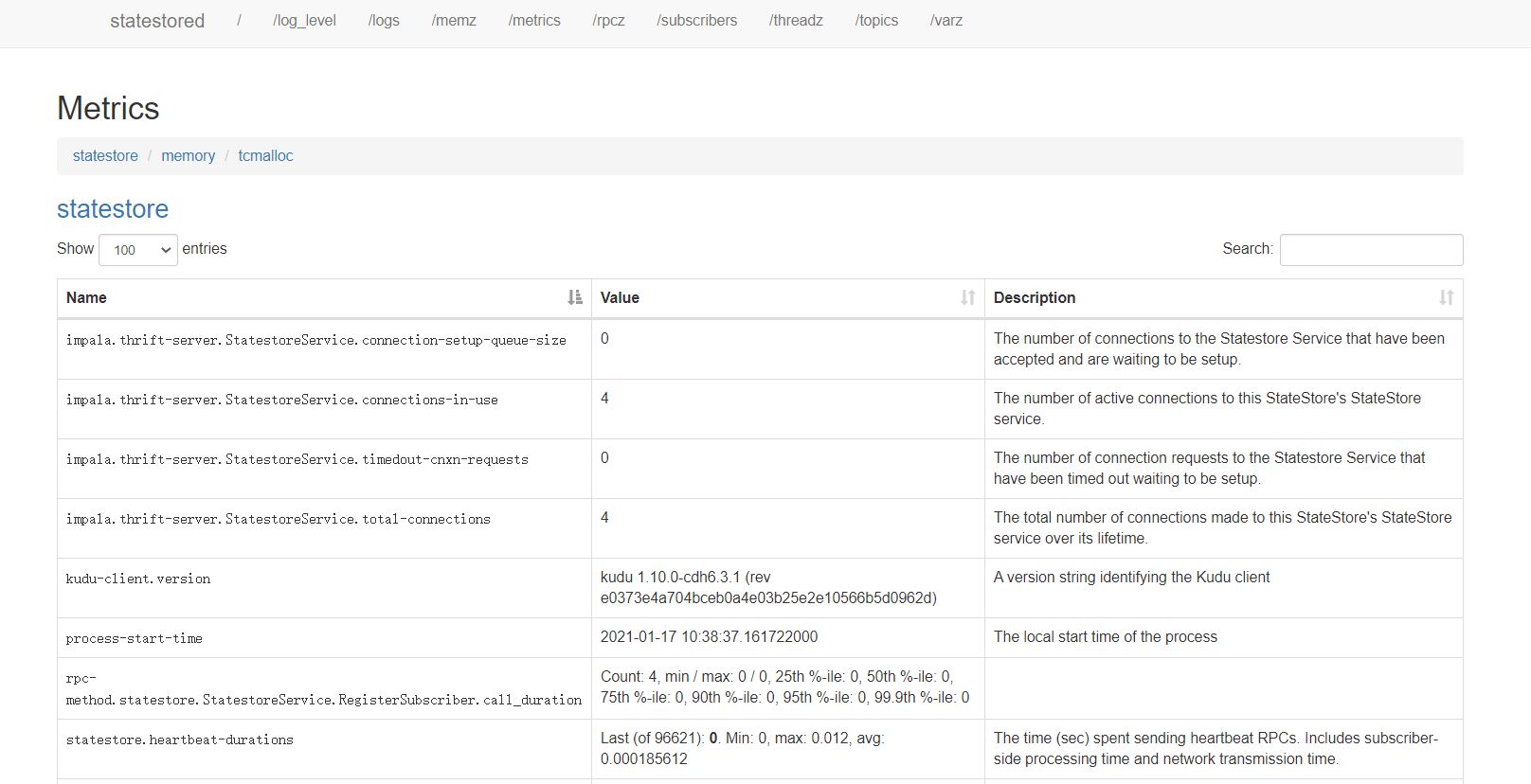
在Catalog的WEBUI http://cdh101:25020/ 可以看到各个库表元数据信息、Schema及占用内存大小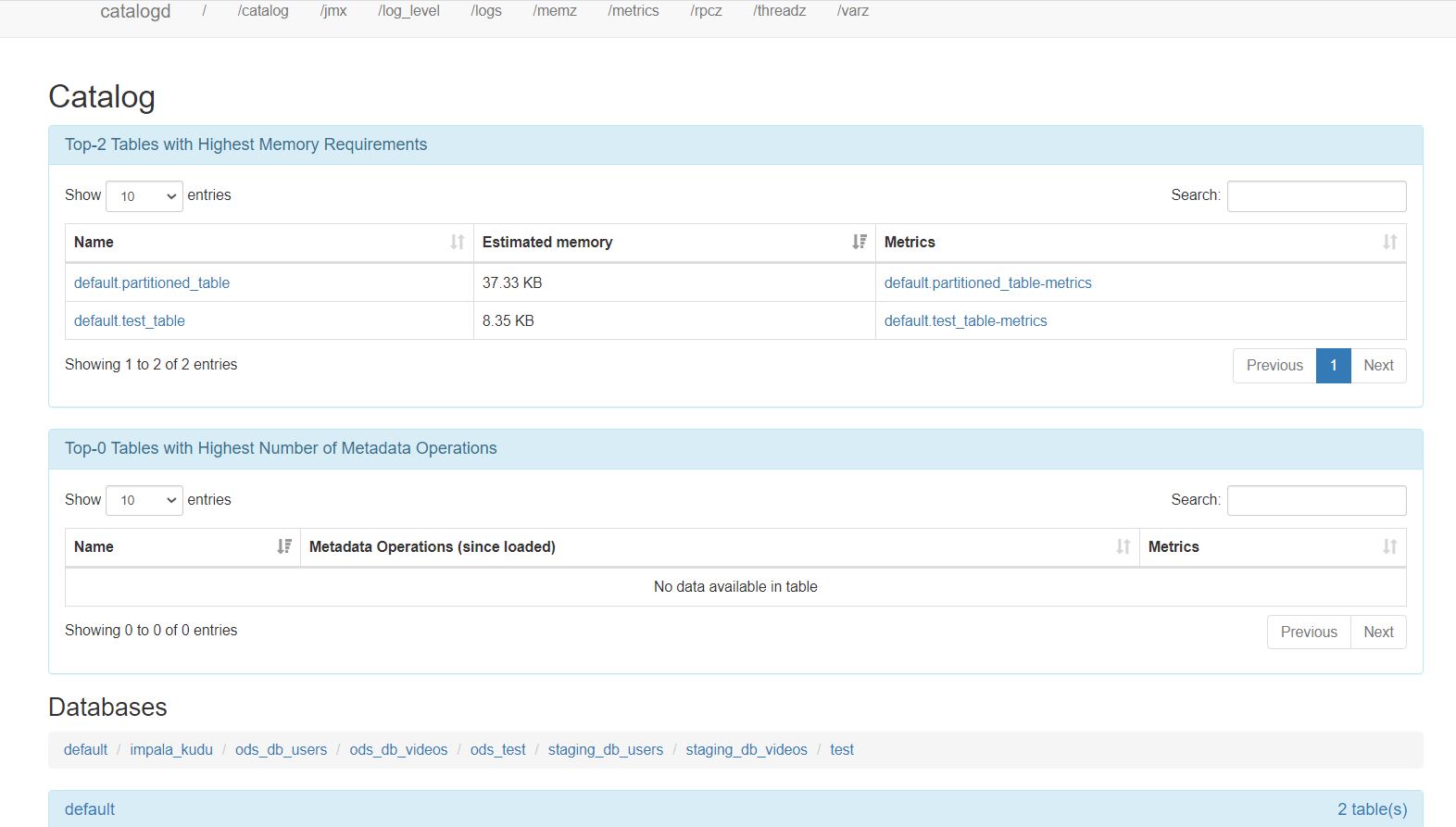
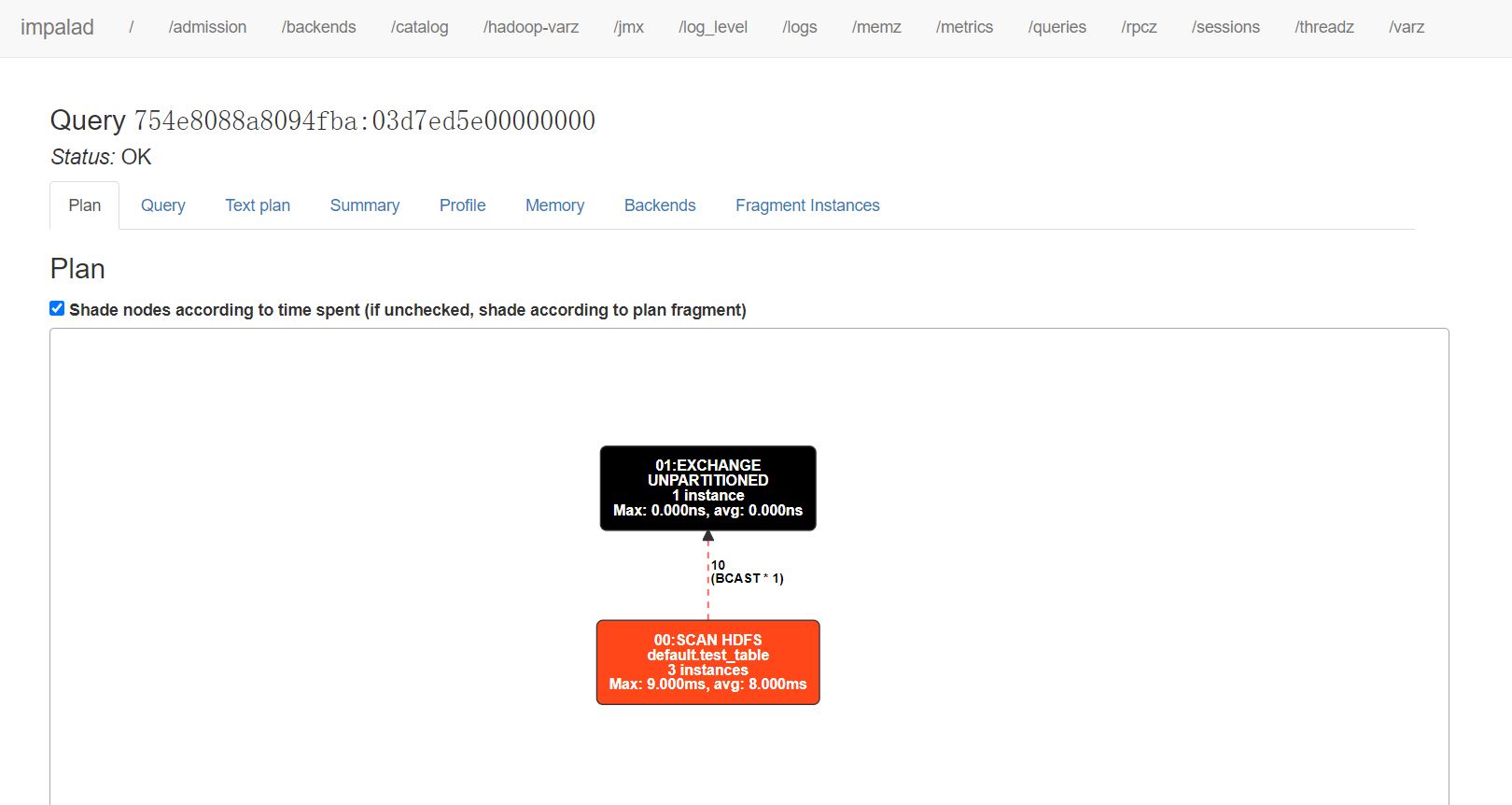
在Impala Daemon的WEBUI http://cdh102:25000/ 可以看到该进程信息 在http://cdh102:25000/queries 可以查看该节点执行SQL的详情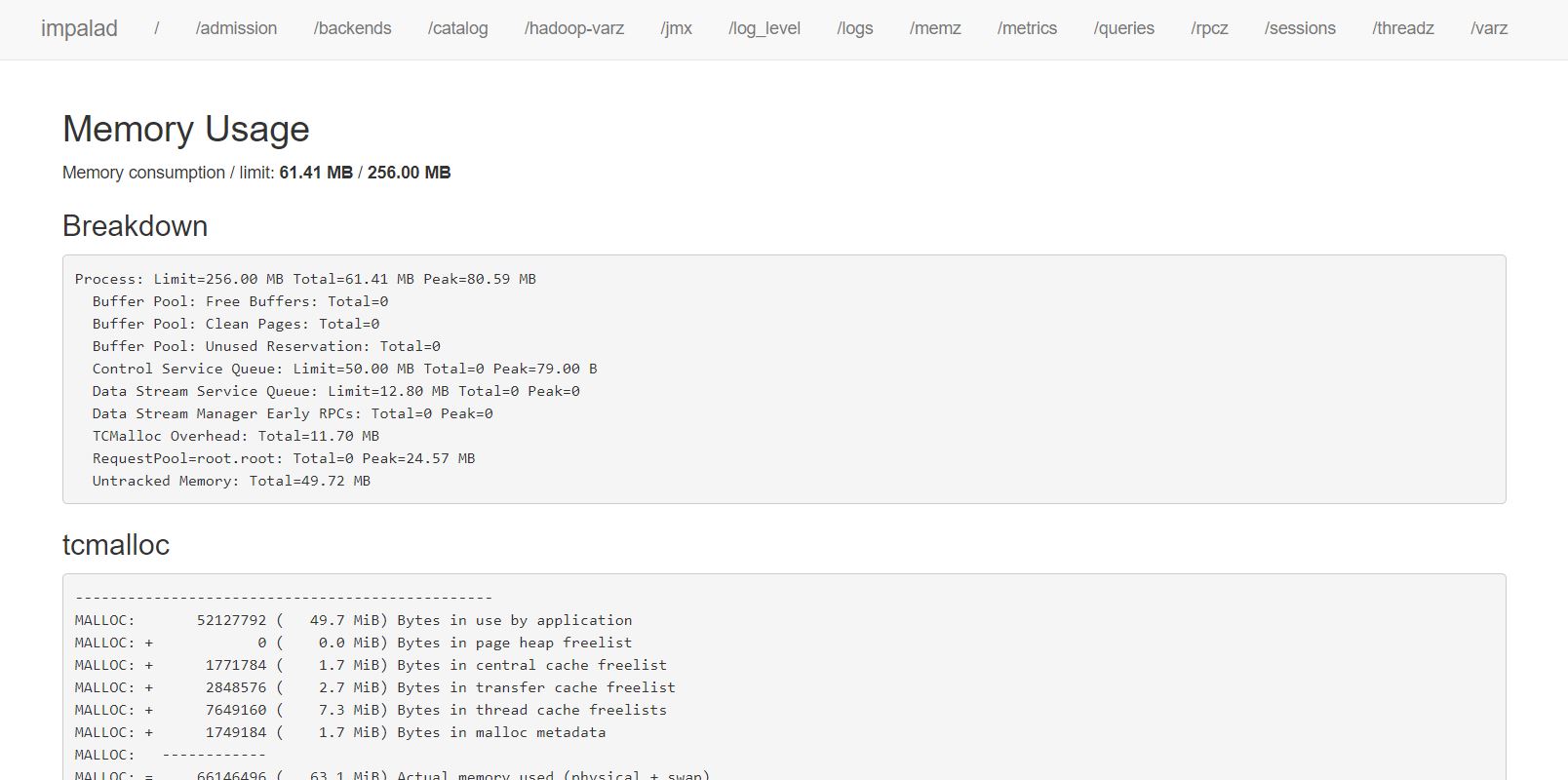
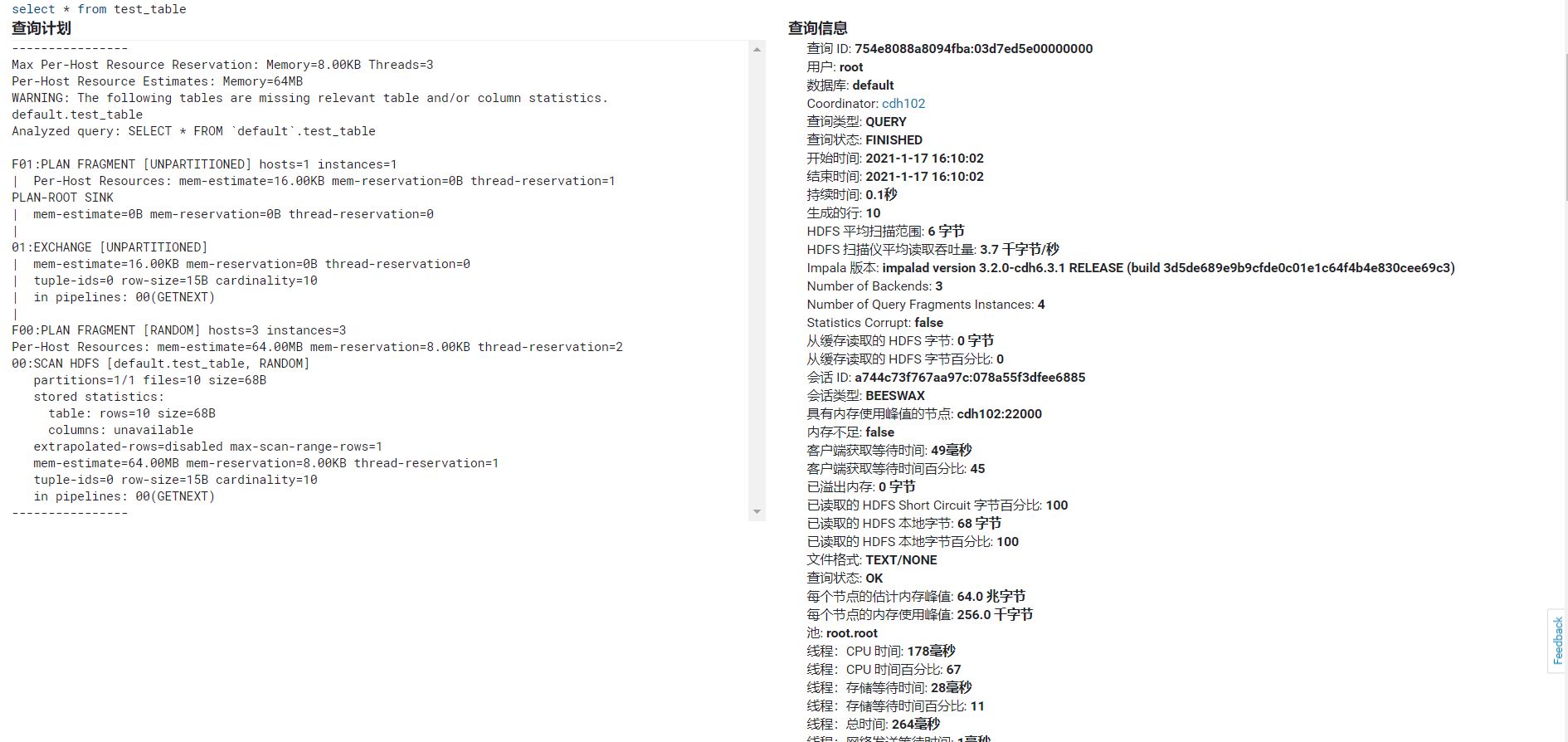
在CDH Impala组件中可以查看执行SQL任务的详细信息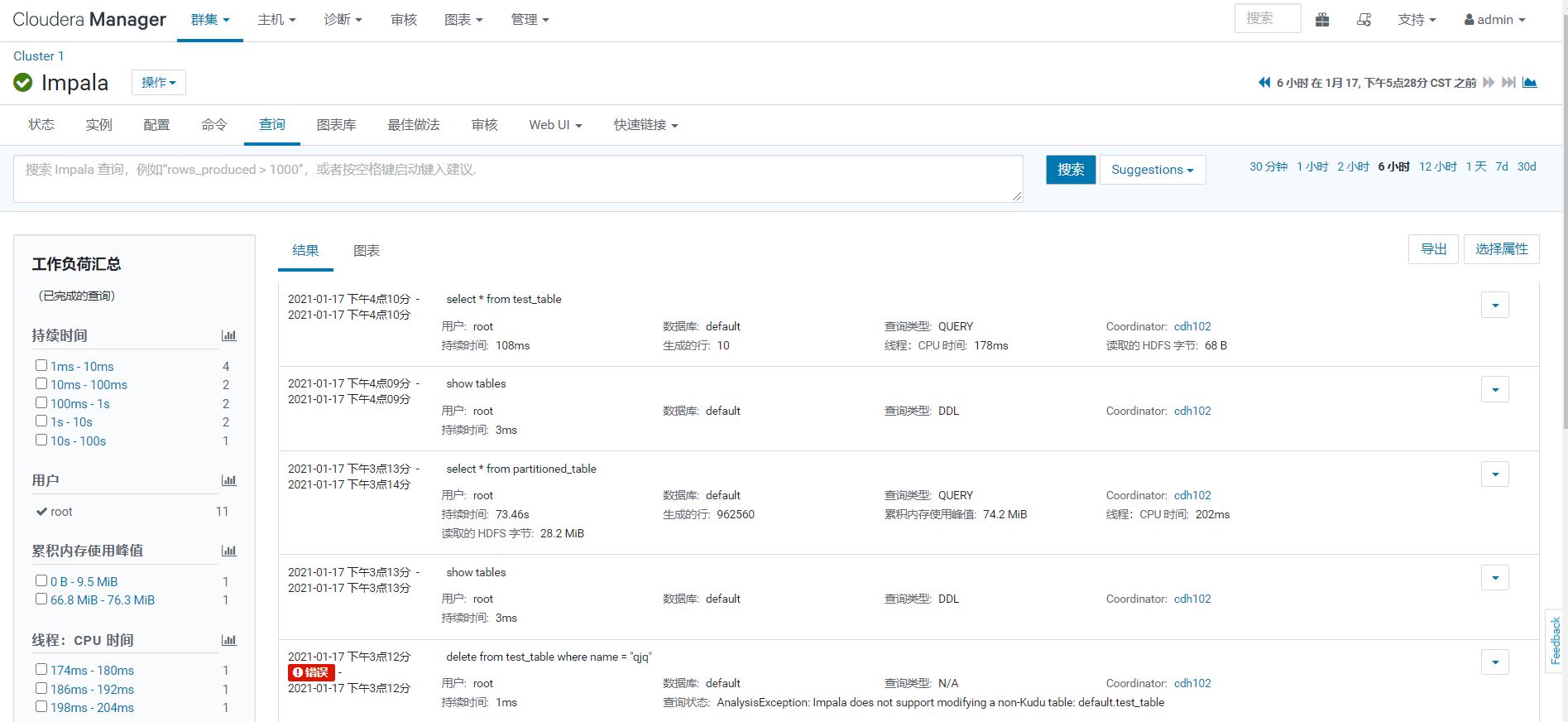
一些重要的常用的impala-shell使用命令
impala-shell -i host指定Coordinator
-d 指定连接到哪个库
-q "select ..." 不进入impala-shell直接查询某语句返回结果到命令行
-f file 执行文件中的sql
-p 获取执行计划
-o 保存执行结果到文件
-h 帮助
-r (--refresh_after_connect) 建立连接后刷新 Impala 元数据
-c 查询执行失败时继续执行
-B(--delimited) 去格式化输出
--output_delimiter=character 指定分隔符
--print_header 打印列名
输出建表语句:impala-shell -i impalad:21000 -q "show create table db.table" -B --output_delimiter="\t"
进入Impala-shell后:
explain <sql> 显示执行计划
shell <shell> 不退出impala-shell执行系统命令
profile 分析上一条Query执行,以便于性能调优(比-p更多的信息)
refresh <tablename> 增量刷新元数据库
invalidate metadata 全量刷新元数据库(慎用)(同于 impala-shell -r)
history 历史命令
-------------------------------------------------------------
示例1:获取一张表的完整建表语句
impala-shell -i 192.168.1.101:21000 -q "show create table default.xxxxx" -B --output_delimiter="\t"
示例2:执行多条SQL
impala-shell -i 192.168.1.101:21000 -q "drop table if exists default.xxxxx;set PARQUET_FILE_SIZE=128m;create table default.xxxxx_new stored as parquet as select * from default.xxxxx where time > '2021-12-01 00:00:00.000000000' and time <= '2021-12-02 00:00:00.000000000';select count(1) from default.xxxxx_new"
示例3:后台执行sql文件中的所有sql
nohup impala-shell -i 192.168.1.101:21000 -f /tmp/export.sql &最佳实践
文件格式推荐parquet,查询效率高
避免碎片文件,注意文件的大小
根据实际的文件大小和个数选择分区的粒度
分区key选择最小的整数类型代替字符串类型,降低元数据占用内存大小
使用COMPUTE STATS命令进行表、分区的性能分析(收集统计信息),提高表的查询效率
COMPUTE STATS [db_name.]table_name COMPUTE INCREMENTAL STATS [db_name.]table_name [PARTITION (partition_spec)]最小化返回Client端的数据量
使用explain+SQL命令确认执行计划是否高效
执行查询后使用summary命令确认硬件消耗(物理性能特性),输出的信息包括哪个阶段耗时最多,以及每一阶段估算的内存消耗、行数与实际的差异
执行查询后使用profile命令显示详细性能信息,输出的信息包括内存、CPU、I/O以及网络消耗的详细信息,可根据该信息进行调优
使用profile查看是否有hdfs块倾斜,合理分配block大小
充分利用Impala Query Hint优化查询效率
Join时大表放在最左面;效率最高的Join放在最前面;定期对表收集统计信息, 或者在大量DML操作后主动收集统计信息;单条SQL的Join数尽量不超过4否则效率低下
impalad无法启动EERROR是WebServer: Could not start on address 0.0.0.0:25000 解决: lsof -i :25000 拿到PID并kill这个PID
节点访问负载均衡–之前提到每个Impalad都是Coordinator,所有任务都提交到一台Coordinator会存在单点性能及单点故障问题,所以为提高任务提交吞吐量避免单点问题,可配置负载均衡的地址访问impalaDaemon,参考Using Impala through a Proxy for High Availability官方文档或Configuring Impala Load Balancer博客,配置如下:
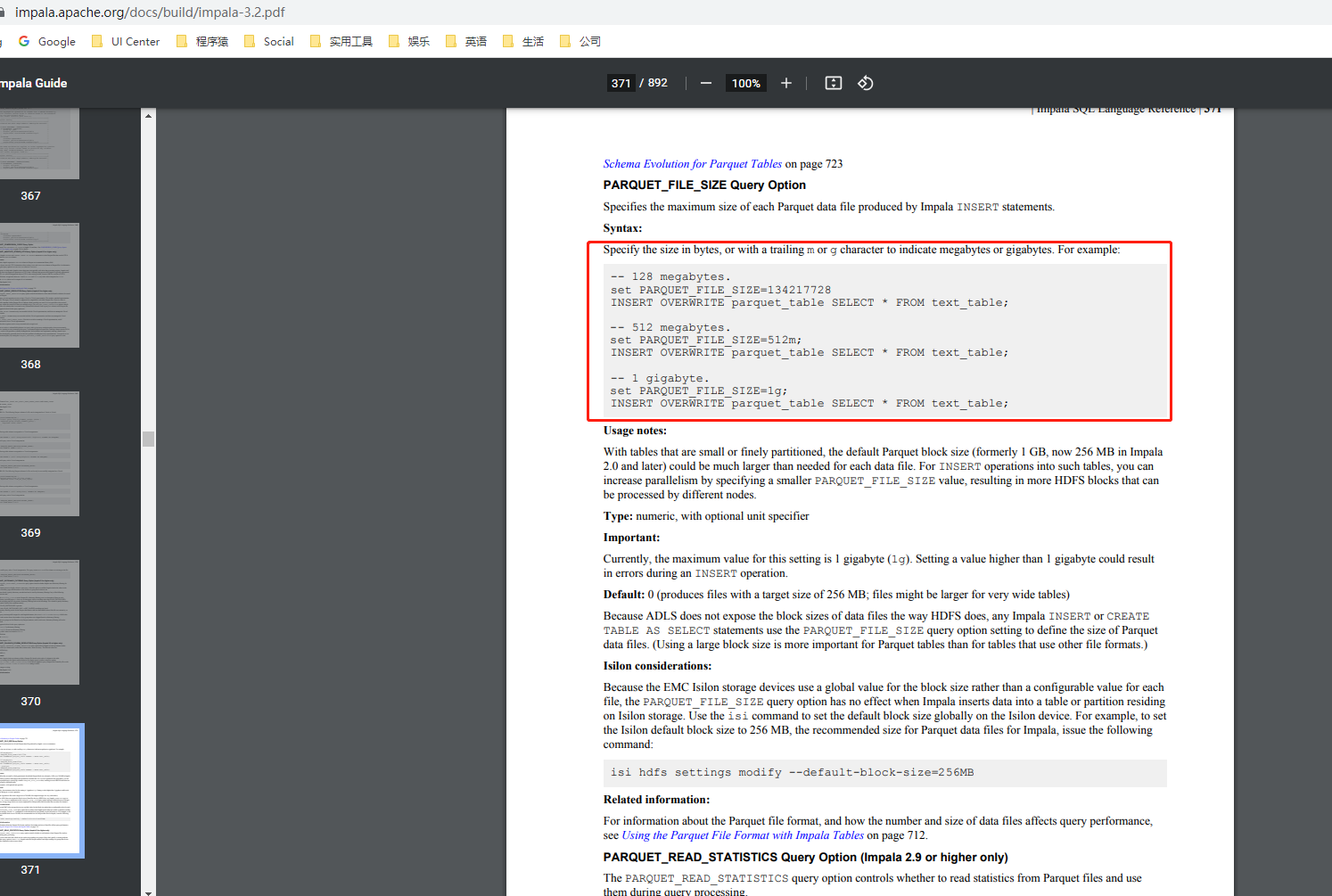
yum -y install haproxy cp /etc/haproxy/haproxy.cfg /etc/haproxy/impala_haproxy.cfg vim /etc/haproxy/impala_haproxy.cfg 注释掉main frontend which proxys to the backends后面的所有内容 注释掉如下行: timeout http-requests 10s timeout queue 1m timeout http-keep-alive 10s timeout check 10s 修改如下行: timeout connect 5000 timeout client 3600s timeout server 3600s 增加如下行: listen stats :25002 balance mode http stats enable stats auth username:password listen impala :21001 mode tcp option tcplog balance leastconn server impalad_1 impalad1_ip:21000 check server impalad_2 impalad2_ip:21000 check server impalad_3 impalad3_ip:21000 check server impalad_4 impalad4_ip:21000 check server impalad_5 impalad5_ip:21000 check # server alias_name impaladIP:21000 check listen impalajdbc :21051 mode tcp option tcplog balance source server impalad_jdbc_01 impalad1_ip:21050 check server impalad_jdbc_02 impalad2_ip:21050 check server impalad_jdbc_03 impalad3_ip:21050 check server impalad_jdbc_04 impalad4_ip:21050 check server impalad_jdbc_05 impalad5_ip:21050 check # server alias_name impaladIP:21050 check 保存退出wq 运行haproxy –f /etc/haproxy/impala_haproxy.cfg 让代理生效 impala-shell -i haproxy_running_ip:21001 可连接代理 jdbc程序原来连接21050改为连接21051,地址改为haproxy_running_ip 保证haproxy运行稳定要做的灾备工作 1.将代理程序加入开机自动运行:root用户下chmod +x /etc/rc.d/rc.local并向该文件添加/sbin/haproxy –f /etc/haproxy/impala_haproxy.cfg 2.代理程序若因极端情况挂掉,写个自动拉起脚本以保证服务(root@cdh01 crontab */1 * * * * sh /app/impala/auto_impala_haproxy.sh)限制Impala生成Parquet文件大小
总结:
- Impala是典型的MPP架构实时查询分析引擎,类似的引擎还有ClickHouse
- Impala非常适合即时报表展示的场景
- 使用Impala一定要注意元数据缓存问题以及所查询的表文件个数、倾斜问题,否则会严重拖慢效率
- 多参考以上最佳实践部分
相关链接
Impala-3.4 PDF Document
Impala介绍以及优劣
Cloudera Impala Wiki
Impala Github repository
Impala架构



