







什么是Sqoop
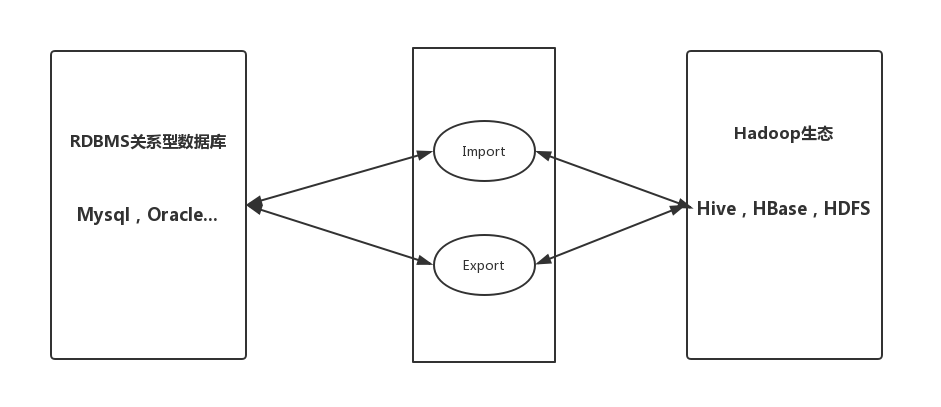
Sqoop是一款开源工具,用于Hadoop(Hive)与mysql等传统数据库间进行数据传递,可以将关系型数据库mysql,Oracle等中的数据导入HDFS中,也可以把HDFS中的数据导入到关系型数据库中。
Sqoop2与Sqoop1完全不兼容,一般生产环境使用Sqoop1,这里主要说Sqoop1
Sqoop原理
Sqoop原理很简单,就是将导入导出的命令翻译成MapReduce程序,Sqoop的操作主要目的(工作)是对MR程序的inputformat和outputformat进行定制.
下图是Sqoop原理架构图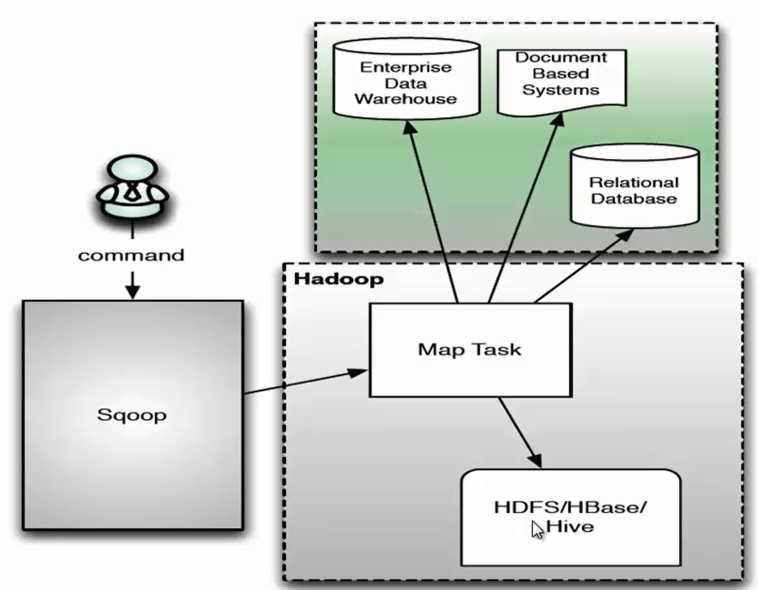
图上意思很明确,这里不多赘述。
戳**官方文档**了解更多
Sqoop安装部署
去官网下载Sqoop的二进制包
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/module/
cd /opt/module/
mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
vim /etc/profile
export SQOOP_HOME=/opt/module/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
cd sqoop/conf
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
文件末尾加入如下配置:
#Set the path for where zookeper config dir is
#export ZOOCFGDIR=
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.7.2
export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.7.2
export HIVE_HOME=/opt/module/hive
export HBASE_HOME=/opt/module/hbase
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.13
export ZOOCFGDIR=/opt/module/zookeeper-3.4.13/conf
# SQOOP写哪个集群,用哪个Yarn,用以下Hive、Hadoop客户端配置指定到sqoop-env.sh
export HADOOP_CONF_DIR=/etc/hadoop/cluster_client_conf/hadoop-conf/
export HIVE_CONF_DIR=/etc/hadoop/cluster_client_conf/hive-conf/
拷贝mysql驱动到Sqoop的lib目录下
cp mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop/lib/
运行sqoop help命令
部署完成,测试:
查看Mysql表
sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username root --password 000000
如果一切正常 - 则安装没问题了Sqoop操作
Sqoop的导入和导出
导入:数据从RDBMS到HDFS的过程,数据源是RDBMS,目标是HDFS
导出:数据从HDFS到RDBMS的过程,数据源是HDFS,目标是RDBMS
导数据到HDFS
准备数据:
创建数据库和表
create database test;
create table sqoop_test(id int primary key not null auto_increment,name varchar(255),sex varchar(255));
insert into test.sqoop_test(name,sex) values('qjj','male');
insert into test.sqoop_test(name,sex) values('abc','female');
use test;
select * from sqoop_test;导入HDFS方式分为全部导入/查询导入/导入指定列/筛选导入/增量更新
- 全部导入
–num-mappers 1 设置一个map,输出文件个数也为1
–null-string 指定字段为空时用什么代替
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 000000 \
--table sqoop_test \
--null-string "-" \
--target-dir /user/sqoop/out \
--num-mappers 1 \
--fields-terminated-by "\t"- 查询导入
不通过**- -table来指定,而是通过写- -query**来指定
$CONDITIONS是必须加的,为了在多个Map的情况下,可以传递参数,以保证导出数据的顺序不变。 __where $CONDITIONS__必备
``` shell
sqoop import \
–connect jdbc:mysql://localhost:3306/test
–username root
–password 000000
–target-dir /user/sqoop/out
–num-mappers 1
–fields-terminated-by “\t”
–query ‘select name,sex from sqoop_test where id <= 1 and $CONDITIONS;’ (这里如果用双引号,则$CONDITIONS需要转义)
3. 导入指定列
--delete-target-dir -> 如果HDFS目录已经存在则删除
--columns指定多个列
``` shell
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 000000 \
--table sqoop_test \
--columns id,sex \
--target-dir /user/sqoop/out \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" - 筛选导入
关键字筛选/字段筛选
–where “条件”
而且–where与–columns可以同时使用,但不能与–query同时使用
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 000000 \
--table sqoop_test \
--where "id=1" \
--target-dir /user/sqoop/out \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" - 增量更新
表更新时重新导入浪费时间和资源
增量更新三个重要参数
–incremental append 指定增量导入
–check-column col_name 以一个列作为增量导入的标准,这个列变化才会触发增量导入
–last-value 指定上次导入的参考列的最后一个值(比如check-column为id,上次导入的id值为4,则增量导入要指定last-value为4)
Sqoop官方用户文档: Sqoop User Guide
导数据到Hive
mysql数据导入Hive过程分两步:
- Mysql先导入到HDFS
- 已被导出到HDFS的数据移动到hive仓库
hive-import指定target为hive
target hive表会自动创建
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 000000 \
--table sqoop_test \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table sqoop_hiveSqoop官方参考: Importing Data Into Hive
导数据到HBase
–columns指定source表中哪几列
–column-family指定列族名称
–split-by按指定列名字段做切分
注意:需要手动创建HBase目标表(以前1.0老版本HBase自动创建)
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 000000 \
--table sqoop_test \
--num-mappers 1 \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_company" \
--split-by idSqoop官方参考: Importing Data Into HBase
Sqoop数据导出
Hive/HDFS导出数据到RDBMS
过程是将表数据每行都编程字符串,然后插入mysql,所以必须指定–input-fields-terminated-by来把字段切割开
注意,RDBMS作为target表,需要手动创建target表
–export-dir指定了数据仓库中表数据位置
sqoop export \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 000000 \
--table sqoop_test \
--num-mappers 1 \
--export-dir /user/hive/warehouse/sqoop_hive \
--input-fields-terminated-by "\t"脚本操作Sqoop
公司一般会使用调度工具定期执行脚本,比如获取前一天的数据要在凌晨一两点进行抽取数据,这就需要定时任务,所以为了方便定时任务,Sqoop参数也要写在脚本里,类似于hive -f hql_file
touch hdfs_to_mysql_job
vim hdfs_to_mysql_job
内容如下:
export
--connect
jdbc:mysql://localhost:3306/test
--username
root
--password
000000
--table
sqoop_test
--num-mappers
1
--export-dir
/user/hive/warehouse/sqoop_hive
--input-fields-terminated-by
"\t"
执行该任务:
sqoop --options-file hdfs_to_mysql_jobSqoop参数中文参考文档
Sqoop参数中文文档,里面还包括了参数的实现类类名,供参考和深入学习,点击链接下载:
Sqoop参数-PDF版
总结
- 强行结束MR任务后,不急着再启MR任务,MRAppMaster任务需要kill掉再运行新任务
- 多看官方文档,里面很详细
- 要根据实际使用场景学习官方文档中重要的常用的部分
- Sqoop毕竟是基于MapReduce的,而MR的运算速度已经不能满足我们的需求,所以导数据和抽取数据的流程完全可以用Spark来代替Sqoop,Spark2.4版本后稳定性和效率都有提升,且能兼容多种数据源,能完成99%的Sqoop任务,当然有一些追求稳定而非速度的抽取数据的任务仍然可以使用Sqoop



