







Iceberg数据湖探索与实践
概念引入–数据湖
- 数据湖是一种存储数据的方式,用于组织不同数据结构.本质上是一种企业数据架构方法,物理实现上则是基于数据存储平台(例如Hadoop,OSS,S3等存储系统),集中存储企业内海量的、多来源,多种类的数据,并支持对数据进行快速加工和分析.
- 数据湖的主要思想是对企业中的所有数据进行统一存储,从原始数据转换为用于报告、可视化、分析和机器学习等各种任务的目标数据.
- 数据湖中的数据包括结构化数据(关系数据库数据),半结构化数据(CSV、XML、JSON等),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像、音频、视频),从而形成一个容纳所有形式数据的集中式数据存储.
Iceberg简介
Iceberg是一种高性能的TableFormat(表格式),定义了数据、元数据的组织方式,支持在Spark、Trino、Flink、Hive及Impala等计算引擎中使用.
Iceberg特性
- 真正的流批一体: 上游写入数据后下游立即可查,满足实时场景;Iceberg提供了流批读取和流批写入接口,用户可以在同一个流程同时处理流批数据,使得流批处理可以使用相同的存储模型,简化了ETL思路.
- 支持异构计算和存储引擎: 存储上支持常见存储如HDFS以及各种对象存储(不与底层存储强绑定);计算上支持Flink,Spark,Presto,Hive等常见计算引擎.
- Schema Evolution(模式演化): 支持无副作用地增(ADD)删(Drop)改(Update)列,改变列顺序(Reorder)以及重命名列(Rename),且代价很低(只涉及元数据操作,不存在数据重新读写操作)(Iceberg使用唯一ID定位列,新增列会分配新的ID,所以列不会错位)
- Partition Evolution(分区演化): 在已有的表上改变分区策略时,之前的分区数据不会变且依然采用老的分区策略,新数据会采用新的分区策略.在Iceberg元数据里,两个分区策略相互独立.比如以前有个天分区表,现在业务需要小时分区,按Hive数仓的处理方式需要重新建表,但Iceberg表直接在原表上更改分区布局即可.
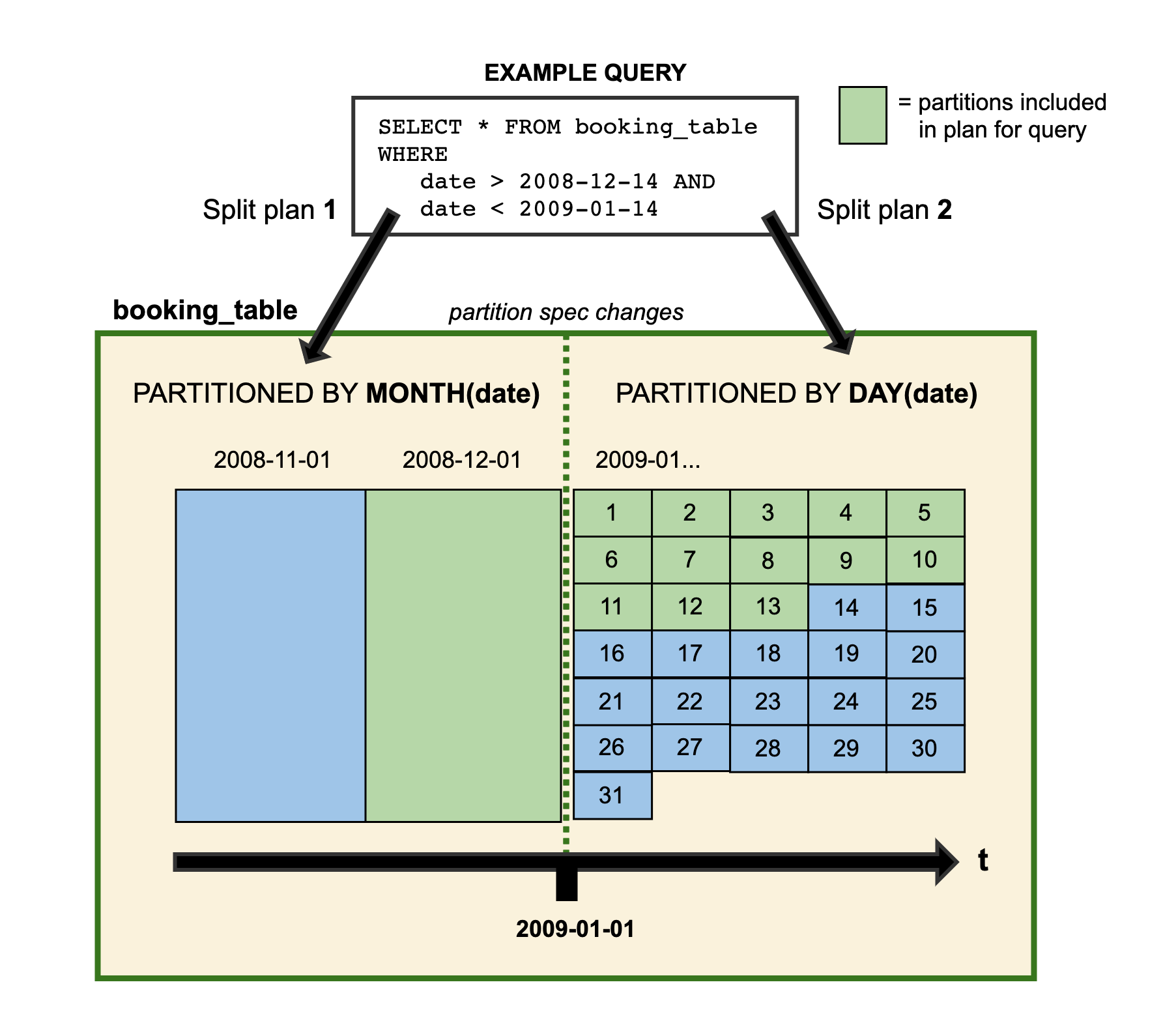
- 支持隐藏分区: Iceberg的分区信息不需要人工维护,可以被隐藏起来.与Hive指定分区字段的方式不同,Iceberg的分区字段(分区策略)支持通过某字段计算出来,在建表或者修改分区策略之后, 新的数据会自动计算所属于的分区,查询时Iceberg会自动过滤不需要扫描的数据,避免了因用户SQL未指定分区过滤条件而导致的性能问题,让用户更专注业务逻辑而无需考虑分区字段过滤问题.(Iceberg分区信息和数据存储目录是相互独立开的,使得Iceberg表分区可以被修改,而且不涉及数据迁移;分区信息不存在HMS,减轻了HMS的压力)
- 分区演化和隐藏分区使得业务可以方便地调整分区策略.
- Time Travel: 可以查询历史某一时间点snapshot的数据,支持回滚到历史snapshot.
- 支持事务(ACID): Iceberg提供了边读边写的能力,上游数据写入即可见,通过事务,保证了下游组件只能消费已经commit的数据,无法读到未提交的数据.支持添加删除更新数据.
- 支持基于乐观锁的并发写: Iceberg基于乐观锁提供了多个程序并发写入的能力并且保证数据线性一致.(乐观创建metadata文件,提交更新会触发metadata原子交换,完成提交)
- 文件级数据剪裁: Iceberg通过元数据来对查询进行高效过滤,Iceberg的元数据里面提供了每个数据文件的一些统计信息, 比如最大值, 最小值, Count计数等等. 因此, 查询SQL的过滤条件除了常规的分区, 列过滤, 甚至可以下推到文件级别, 大大加快了查询效率.
- 支持多种底层存储格式如Parquet、Avro以及ORC等.
- 支持Upsert能力,且更新即可见,但不能过于频繁,若Upsert过于频繁,则需要频繁数据合并
Iceberg原理
Iceberg元数据
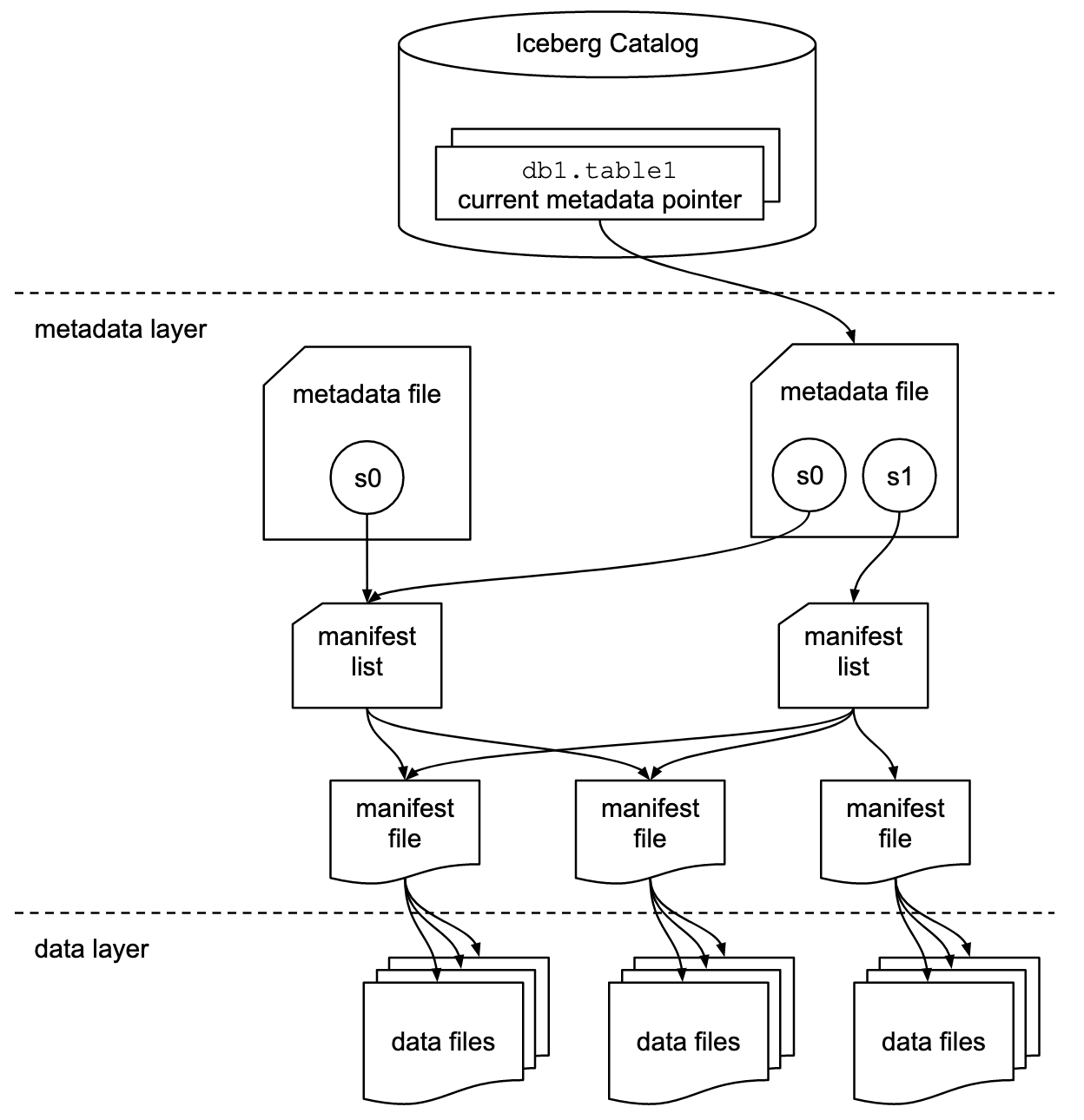
1.DataFiles数据文件 存放真实数据文件,由一个或多个ManifestFile跟踪
2.MetadataFile文件 “*.metadata.json”文件,Iceberg表某时刻的状态,里面记录了表Schema,分区配置,表参数,snapshot记录以及这个时刻涉及到的所有的ManifestList.
3.ManifestList清单列表 “snap-*.avro”文件,存储了构建快照的所有ManifestFile列表,每个ManifestFile在里面占一行,每行存储了ManifestFile路径,分区范围,增删文件信息,来为查询时提供过滤能力,提高性能.一个快照对应一个ManifestList文件.
4.ManifestFile清单文件 非snap开头的avro格式文件,包含了DataFiles列表,每行包含一个数据文件的详细描述(状态,路径,分区信息,列级别的统计信息,最大值最小值空值个数,文件大小,行数等),为查询时提供过滤能力,提高性能.
HadoopCatalog与HiveCatalog表的目录结构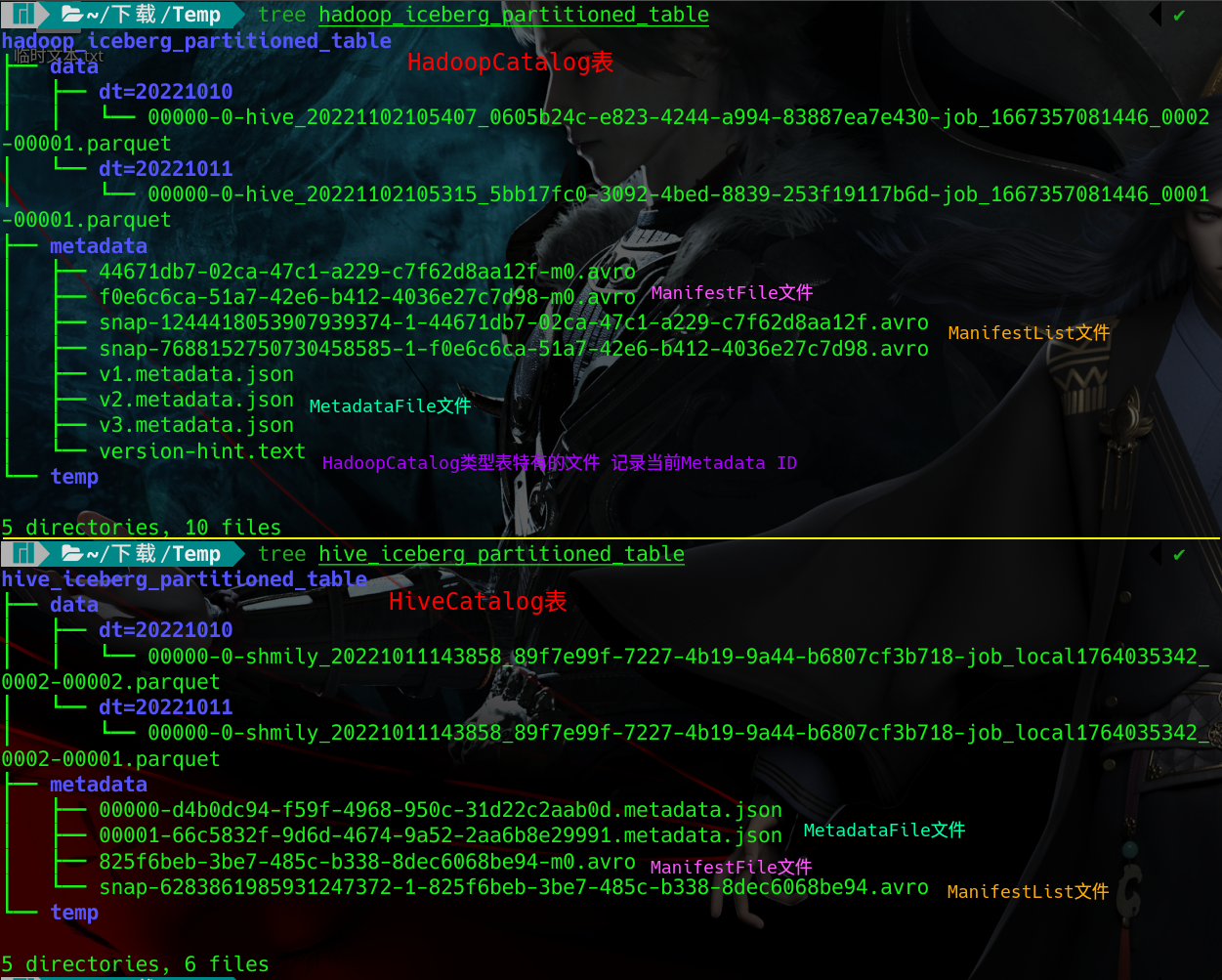
差异:
1.HadoopCatalog表MetadataFile命名为*.metadata.json,与HiveCatalog表ManifestList命名规范不同
2.HadoopCatalog表通过version-hint.text记录最新快照ID,HiveCatalog通过HiveMetaStore记录最新metadata_location.
3.HadoopCatalog与HiveCatalog表元数据不互通,无法互相转换
HadoopCatalog表元数据解析
# 查看avro文件内容
wget https://repo1.maven.org/maven2/org/apache/avro/avro-tools/1.11.1/avro-tools-1.11.1.jar
java -jar avro-tools-1.11.1.jar tojson xxx.avroMetadataFile文件 v3.metadata.json
{
"format-version" : 1,
"table-uuid" : "eeffbc08-9156-4a6f-8380-6138c6b67889",
"location" : "hdfs://shmily:8020/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table",
"last-updated-ms" : 1667357677633,
"last-column-id" : 4,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "name",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "age",
"required" : false,
"type" : "int"
}, {
"id" : 4,
"name" : "dt",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "name",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "age",
"required" : false,
"type" : "int"
}, {
"id" : 4,
"name" : "dt",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ {
"name" : "dt",
"transform" : "identity",
"source-id" : 4,
"field-id" : 1000
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "dt",
"transform" : "identity",
"source-id" : 4,
"field-id" : 1000
} ]
} ],
"last-partition-id" : 1000,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"EXTERNAL" : "TRUE",
"write.metadata.previous-versions-max" : "5",
"bucketing_version" : "2",
"write.metadata.delete-after-commit.enabled" : "true",
"write.distribution-mode" : "hash",
"storage_handler" : "org.apache.iceberg.mr.hive.HiveIcebergStorageHandler"
},
"current-snapshot-id" : 1244418053907939374,
"refs" : {
"main" : {
"snapshot-id" : 1244418053907939374,
"type" : "branch"
}
},
"snapshots" : [ {
"snapshot-id" : 7688152750730458585,
"timestamp-ms" : 1667357628763,
"summary" : {
"operation" : "append",
"added-data-files" : "1",
"added-records" : "2",
"added-files-size" : "1272",
"changed-partition-count" : "1",
"total-records" : "2",
"total-files-size" : "1272",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://shmily:8020/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table/metadata/snap-7688152750730458585-1-f0e6c6ca-51a7-42e6-b412-4036e27c7d98.avro",
"schema-id" : 0
}, {
"snapshot-id" : 1244418053907939374,
"parent-snapshot-id" : 7688152750730458585,
"timestamp-ms" : 1667357677633,
"summary" : {
"operation" : "append",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "1166",
"changed-partition-count" : "1",
"total-records" : "3",
"total-files-size" : "2438",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://shmily:8020/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table/metadata/snap-1244418053907939374-1-44671db7-02ca-47c1-a229-c7f62d8aa12f.avro",
"schema-id" : 0
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1667357628763,
"snapshot-id" : 7688152750730458585
}, {
"timestamp-ms" : 1667357677633,
"snapshot-id" : 1244418053907939374
} ],
"metadata-log" : [ {
"timestamp-ms" : 1667357528190,
"metadata-file" : "hdfs://shmily:8020/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1667357628763,
"metadata-file" : "hdfs://shmily:8020/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table/metadata/v2.metadata.json"
} ]
}ManifestList清单列表文件 snap-7688152750730458585-1-f0e6c6ca-51a7-42e6-b412-4036e27c7d98.avro
{"manifest_path":"hdfs://shmily:8020/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table/metadata/f0e6c6ca-51a7-42e6-b412-4036e27c7d98-m0.avro","manifest_length":6189,"partition_spec_id":0,"added_snapshot_id":{"long":7688152750730458585},"added_data_files_count":{"int":1},"existing_data_files_count":{"int":0},"deleted_data_files_count":{"int":0},"partitions":{"array":[{"contains_null":false,"contains_nan":{"boolean":false},"lower_bound":{"bytes":"20221011"},"upper_bound":{"bytes":"20221011"}}]},"added_rows_count":{"long":2},"existing_rows_count":{"long":0},"deleted_rows_count":{"long":0}}ManifestFile清单文件 f0e6c6ca-51a7-42e6-b412-4036e27c7d98-m0.avro
{"status":1,"snapshot_id":{"long":7688152750730458585},"data_file":{"file_path":"hdfs://shmily:8020/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table/data/dt=20221011/00000-0-hive_20221102105315_5bb17fc0-3092-4bed-8839-253f19117b6d-job_1667357081446_0001-00001.parquet","file_format":"PARQUET","partition":{"dt":{"string":"20221011"}},"record_count":2,"file_size_in_bytes":1272,"block_size_in_bytes":67108864,"column_sizes":{"array":[{"key":1,"value":55},{"key":2,"value":59},{"key":3,"value":93},{"key":4,"value":101}]},"value_counts":{"array":[{"key":1,"value":2},{"key":2,"value":2},{"key":3,"value":2},{"key":4,"value":2}]},"null_value_counts":{"array":[{"key":1,"value":0},{"key":2,"value":0},{"key":3,"value":0},{"key":4,"value":0}]},"nan_value_counts":{"array":[]},"lower_bounds":{"array":[{"key":1,"value":"\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"abc"},{"key":3,"value":"\u0018\u0000\u0000\u0000"},{"key":4,"value":"20221011"}]},"upper_bounds":{"array":[{"key":1,"value":"\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"qjj"},{"key":3,"value":"\u0018\u0000\u0000\u0000"},{"key":4,"value":"20221011"}]},"key_metadata":null,"split_offsets":{"array":[4]},"sort_order_id":{"int":0}}}HiveCatalog表元数据解析
MetadataFile文件 00001-66c5832f-9d6d-4674-9a52-2aa6b8e29991.metadata.json
{
"format-version" : 1,
"table-uuid" : "5397c8ee-2b24-4eea-83ae-55e024ccd2c0",
"location" : "hdfs://shmily:8020/user/hive/warehouse/iceberg_db.db/hive_iceberg_partitioned_table",
"last-updated-ms" : 1665470339331,
"last-column-id" : 4,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "name",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "age",
"required" : false,
"type" : "int"
}, {
"id" : 4,
"name" : "dt",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "name",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "age",
"required" : false,
"type" : "int"
}, {
"id" : 4,
"name" : "dt",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ {
"name" : "dt",
"transform" : "identity",
"source-id" : 4,
"field-id" : 1000
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "dt",
"transform" : "identity",
"source-id" : 4,
"field-id" : 1000
} ]
} ],
"last-partition-id" : 1000,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"engine.hive.enabled" : "true",
"write.metadata.previous-versions-max" : "5",
"bucketing_version" : "2",
"write.metadata.delete-after-commit.enabled" : "true",
"write.distribution-mode" : "hash",
"storage_handler" : "org.apache.iceberg.mr.hive.HiveIcebergStorageHandler"
},
"current-snapshot-id" : 6283861985931247372,
"refs" : {
"main" : {
"snapshot-id" : 6283861985931247372,
"type" : "branch"
}
},
"snapshots" : [ {
"snapshot-id" : 6283861985931247372,
"timestamp-ms" : 1665470339331,
"summary" : {
"operation" : "append",
"added-data-files" : "2",
"added-records" : "3",
"added-files-size" : "2438",
"changed-partition-count" : "2",
"total-records" : "3",
"total-files-size" : "2438",
"total-data-files" : "2",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://shmily:8020/user/hive/warehouse/iceberg_db.db/hive_iceberg_partitioned_table/metadata/snap-6283861985931247372-1-825f6beb-3be7-485c-b338-8dec6068be94.avro",
"schema-id" : 0
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1665470339331,
"snapshot-id" : 6283861985931247372
} ],
"metadata-log" : [ {
"timestamp-ms" : 1665470256700,
"metadata-file" : "hdfs://shmily:8020/user/hive/warehouse/iceberg_db.db/hive_iceberg_partitioned_table/metadata/00000-d4b0dc94-f59f-4968-950c-31d22c2aab0d.metadata.json"
} ]
}ManifestList清单列表文件 snap-6283861985931247372-1-825f6beb-3be7-485c-b338-8dec6068be94.avro
{"manifest_path":"hdfs://shmily:8020/user/hive/warehouse/iceberg_db.db/hive_iceberg_partitioned_table/metadata/825f6beb-3be7-485c-b338-8dec6068be94-m0.avro","manifest_length":6234,"partition_spec_id":0,"added_snapshot_id":{"long":6283861985931247372},"added_data_files_count":{"int":2},"existing_data_files_count":{"int":0},"deleted_data_files_count":{"int":0},"partitions":{"array":[{"contains_null":false,"contains_nan":{"boolean":false},"lower_bound":{"bytes":"20221010"},"upper_bound":{"bytes":"20221011"}}]},"added_rows_count":{"long":3},"existing_rows_count":{"long":0},"deleted_rows_count":{"long":0}}ManifestFile清单文件 825f6beb-3be7-485c-b338-8dec6068be94-m0.avro
{"status":1,"snapshot_id":{"long":6283861985931247372},"data_file":{"file_path":"hdfs://shmily:8020/user/hive/warehouse/iceberg_db.db/hive_iceberg_partitioned_table/data/dt=20221011/00000-0-shmily_20221011143858_89f7e99f-7227-4b19-9a44-b6807cf3b718-job_local1764035342_0002-00001.parquet","file_format":"PARQUET","partition":{"dt":{"string":"20221011"}},"record_count":2,"file_size_in_bytes":1272,"block_size_in_bytes":67108864,"column_sizes":{"array":[{"key":1,"value":55},{"key":2,"value":59},{"key":3,"value":93},{"key":4,"value":101}]},"value_counts":{"array":[{"key":1,"value":2},{"key":2,"value":2},{"key":3,"value":2},{"key":4,"value":2}]},"null_value_counts":{"array":[{"key":1,"value":0},{"key":2,"value":0},{"key":3,"value":0},{"key":4,"value":0}]},"nan_value_counts":{"array":[]},"lower_bounds":{"array":[{"key":1,"value":"\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"abc"},{"key":3,"value":"\u0018\u0000\u0000\u0000"},{"key":4,"value":"20221011"}]},"upper_bounds":{"array":[{"key":1,"value":"\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"qjj"},{"key":3,"value":"\u0018\u0000\u0000\u0000"},{"key":4,"value":"20221011"}]},"key_metadata":null,"split_offsets":{"array":[4]},"sort_order_id":{"int":0}}}
{"status":1,"snapshot_id":{"long":6283861985931247372},"data_file":{"file_path":"hdfs://shmily:8020/user/hive/warehouse/iceberg_db.db/hive_iceberg_partitioned_table/data/dt=20221010/00000-0-shmily_20221011143858_89f7e99f-7227-4b19-9a44-b6807cf3b718-job_local1764035342_0002-00002.parquet","file_format":"PARQUET","partition":{"dt":{"string":"20221010"}},"record_count":1,"file_size_in_bytes":1166,"block_size_in_bytes":67108864,"column_sizes":{"array":[{"key":1,"value":51},{"key":2,"value":53},{"key":3,"value":51},{"key":4,"value":59}]},"value_counts":{"array":[{"key":1,"value":1},{"key":2,"value":1},{"key":3,"value":1},{"key":4,"value":1}]},"null_value_counts":{"array":[{"key":1,"value":0},{"key":2,"value":0},{"key":3,"value":0},{"key":4,"value":0}]},"nan_value_counts":{"array":[]},"lower_bounds":{"array":[{"key":1,"value":"\u0003\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"abc"},{"key":3,"value":"\u0018\u0000\u0000\u0000"},{"key":4,"value":"20221010"}]},"upper_bounds":{"array":[{"key":1,"value":"\u0003\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"abc"},{"key":3,"value":"\u0018\u0000\u0000\u0000"},{"key":4,"value":"20221010"}]},"key_metadata":null,"split_offsets":{"array":[4]},"sort_order_id":{"int":0}}}Iceberg表类型
当Iceberg添加了新特性但该新特性破坏了向前兼容性时,表的version会增加,以保证旧的表版本仍然可以兼容.
Iceberg当前有V1和V2两种表类型,建表时由property-version指定.
Version 1: Analytic Data Tables 🔗 基于不可变文件格式管理的大型分析表
V1表可以按分区删除数据(如在Trino中delete from iceberg_table where ds=’2022120114’;),删除并不会真正删除数据,而是commit新的元数据新的快照,只要旧快照未过期,仍然可以回滚到删除前的状态,但一旦快照过期,数据文件会被删除无法还原;V1表不支持行级删除(会报错failed: Iceberg table updates require at least format version 2)
Version 2: Row-level Deletes 🔗 较Version 1添加了行级更新\删除能力;添加了Delete files以对现有数据文件中删除的行进行编码。Version2可实现删除或替换不可变数据文件中的单个行,而无需重写文件。
Iceberg表数据类型
| 数据类型 | 介绍 | 要求 |
|---|---|---|
| int | 32位有符号整形 | 可转为long |
| long | 64位有符号整形 | |
| float | 单精度浮点型 | 可转为double |
| double | 双精度浮点型 | |
| decimal(P,S) | 固定小数点类型数值 | 精度P,决定总位数;比例S,决定小数位数;P必须小于等于38 |
| date | 日期,不含时间和时区 | |
| time | 时间,不含日期和时区 | 以微妙存储 |
| timestamp | 不含时区的时间戳 | 以微妙存储 |
| timestamptz | 含时区的时间戳 | 以微妙存储 |
| string | 字符串,任意长度 | Encoded with UTF-8 |
| fixed(L) | 固定长度为L的字节数组 | |
| binary | 任意长度字节数组 | |
| struct<…> | 任意数据类型组成的结构体 | |
| list | 任意数据类型组成的List | |
| map<K,V> | 任意数据类型组成的键值对 | 行存储类型,存储和检索时扫描数据量较大 |
Iceberg集成
Iceberg与Hive集成
添加iceberg-hive-runtime-0.14.1.jar,libfb303-0.9.3.jar两个jar到$HIVE_HOME/auxlib下
添加iceberg.engine.hive.enabled=true参数到hive-site.xml
Hive创建Iceberg表
(Hive操作Iceberg支持多种Catalog,支持Hadoop、Hive(默认)、location_based_table、Custom几种管理方式,其中前三种是开箱即用的)
1.HiveCatalog类型(表元数据信息使用HiveMetaStore来管理,依赖Hive):
-- 不设置Catalog类型时默认会使用HiveCatalog类型的Iceberg表
-- 示例1 非分区表
CREATE TABLE iceberg_db.hive_iceberg_table (
id BIGINT,
name STRING
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION '/user/hive/warehouse/iceberg_db.db/hive_iceberg_table'
TBLPROPERTIES (
'write.distribution-mode'='hash', -- 数据写入参数,设置为hash表示按key哈希,每一个Partition数据最多由一个Task来写入,减少小文件
'write.metadata.delete-after-commit.enabled'='true', -- (每次提交后是否删除旧元数据文件) 自动清理旧元数据 metadata.json 不能清理manifest和snapshot的avro文件
'write.metadata.previous-versions-max'='5' -- 保留的metadata.json数量
);
-- 示例2 分区表
CREATE TABLE iceberg_db.hive_iceberg_partitioned_table (
id BIGINT,
name STRING,
age int
) partitioned by (dt string)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES (
'write.distribution-mode'='hash',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5',
'format-version'='2',
'engine.hive.enabled'='true',
'write.target-file-size-bytes'='268435456',
'write.format.default'='parquet',
'write.parquet.compression-codec'='zstd',
'write.parquet.compression-level'='10',
'write.avro.compression-codec'='zstd',
'write.avro.compression-level'='10'
);
-- 示例3 手动指定catalog名称,指定catalog类型为HiveCatalog类型并建表:
set iceberg.catalog.<catalog_name>.type=hive; -- 设置catalog类型
CREATE TABLE iceberg_db.hive_iceberg_partitioned_table (
id BIGINT,
name STRING,
age int
) partitioned by (dt string)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES (
'iceberg.catalog'='<catalog_name>',
'write.distribution-mode'='hash',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5'
);HiveCatalog表在HMS中保存了很多Table Parameters信息,如current-schema,current-snapshot-xx,default-partition-spec,metadata_location,previous_metadata_location,snapshot-count等信息.
HiveCatalog表在Hive下存在的问题: 在Kerberos认证的HMS环境下,Hive客户端可以建表和查询,但无法inssert数据;可以使用beeline+hiveserver2进行Iceberg表的insert操作.
适用场景: HiveCatalog在兼容性方面有天然的优势,几乎大部分常见计算引擎都支持HiveCatalog,而其他类型的Catalog则有不被计算引擎支持的可能.尤其是如果使用Iceberg自定义Catalog,则需要为每个试用Iceberg的引擎做一定的开发工作以兼容自定义Catalog.
2.HadoopCatalog类型(元数据信息使用底层外部存储来管理)
set iceberg.catalog.<catalog_name>.type=hadoop; -- 必须每次设置catalog类型
set iceberg.catalog.<catalog_name>.warehouse=hdfs://nameservice/user/iceberg/warehouse; -- 必须每次设置warehouse存储路径
create external table iceberg_db.hadoop_iceberg_partitioned_table (
id BIGINT,
name STRING,
age int
) partitioned by (dt string)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://nameservice/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_partitioned_table' -- 路径必须是${iceberg.catalog.<catalog_name>.warehous}/${db_name}/${table_name}
tblproperties (
'iceberg.catalog'='<catalog_name>',
'write.distribution-mode'='hash',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5'
);3.LocationBasedTable(外部存储中已经存在HadoopCatalog类型Iceberg表的数据,将其映射到Hive表)
HDFS已经存在了Iceberg格式表的数据,我们可以指定tblproperties(‘iceberg.catalog’=’location_based_table’)和LOCATION,它会去指定的LOCATION路径下加载iceberg表数据.前提LOCATION下已经存在Iceberg格式表数据了.
建表时不需要加PARTITION BY,只需要加字段即可.
create external table iceberg_db.location_iceberg_partitioned_table (
id BIGINT,
name STRING,
age INT,
dt STRING
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://nameservice/user/iceberg/warehouse/iceberg_db/location_iceberg_partitioned_table'
tblproperties ('iceberg.catalog'='location_based_table');
或
create table iceberg_db.location_iceberg_partitioned_table (
id BIGINT,
name STRING,
age INT,
dt STRING
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://nameservice/user/iceberg/warehouse/iceberg_db/location_iceberg_partitioned_table'
tblproperties ('iceberg.catalog'='location_based_table');推荐场景: 外部计算引擎均支持HadoopCatalog类型Iceberg表的情况下,比如Flink、Spark等引擎写入的数据,可以使用这种方式创建Hive表来打通Hive.
不推荐场景: 需要使用Trino分析该表.(因为Trino当前不支持HadoopCatalog类型Iceberg表)
注意: 外部存储上的Iceberg表,Catalog必须是HadoopCatalog类型的,否则无法读取数据。如果是其他Catalog类型,表创建时会报错File does not exist: /table_path…/metadata/version-hint.text,表能创建成功,但查询结果为空。
4.CustomCatalog自定义Catalog,通过Iceberg提供的API定制Catalog,使Iceberg能更加灵活地使用各类元数据管理方案.
适用场景: 需要与Hive Hadoop等解耦的场景,以及需要灵活管理元数据的场景.在元数据管理和兼容计算引擎方面需要一定的开发工作量.
Iceberg与Flink集成
Flink 1.14则下载iceberg-flink-runtime-1.14-0.14.1.jar 放入$FLINK_HOME/lib目录下
Flink DataStreamAPI集成Iceberg
写了几个案例:
Kafka数据通过Flink Datastream API写入Iceberg:
KafkaSinkHadoopCatalogIcebergTable
KafkaSinkHiveCatalogIcebergTable
通过Flink Datastream API读取Iceberg:
HadoopCatalogIcebergTableSource
HiveCatalogIcebergTableSourceFlink SQL集成Iceberg
打通Kafka->Flink SQL->HadoopCatalog类型Iceberg表->Hive
-- 启动flink集群:cd $FLINK_HOME ; bin/start-cluster.sh
-- 启动FlinkSQL Console:bin/sql-client.sh embedded shell
set execution.checkpointing.interval=10sec; -- 必须设置checkpoint 靠checkpoint提交更新数据到Iceberg
SET execution.runtime-mode = streaming; -- 流式写
CREATE TABLE t_kafka_source (
id BIGINT,
name STRING,
age INT,
dt STRING
) WITH (
'connector' = 'kafka',
'topic' = 'flink_topic1',
'scan.startup.mode' = 'latest-offset',
'properties.bootstrap.servers' = 'cdh101:9092,cdh102:9092,cdh103:9092,cdh104:9092',
'properties.group.id' = 'test',
'format' = 'csv'
);
-- 1.写入Iceberg表[HadoopCatalog类型]
CREATE CATALOG hadoop_iceberg_catalog WITH (
'type'='iceberg', -- 创建HadoopCatalog类型Iceberg表在FlinkSQL中的Catalog
'catalog-type'='hadoop',
'warehouse'='hdfs://nameservice/user/iceberg/warehouse',
'property-version'='1'
);
CREATE TABLE if not exists `hadoop_iceberg_catalog`.`iceberg_db`.`hadoop_iceberg_table_flink_sql` (
id BIGINT,
name STRING,
age INT,
dt STRING
) PARTITIONED BY (dt)
WITH('type'='ICEBERG',
'engine.hive.enabled'='true', -- 支持hive查询(实测发现不加也没影响)
'read.split.target-size'='1073741824', -- 减少split数提升查询效率
'write.target-file-size-bytes'='134217728',
'write.format.default'='parquet',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='9',
'write.distribution-mode'='hash');
insert into hadoop_iceberg_catalog.iceberg_db.hadoop_iceberg_table_flink_sql select id,name,age,dt from t_kafka_source;
-- 2.FlinkSQL批式查询
SET execution.runtime-mode = batch;
select id,name,age,dt from `hadoop_iceberg_catalog`.`iceberg_db`.`hadoop_iceberg_table_flink_sql`;
-- 3.FlinkSQL流式查询
---- 注:不指定start-snapshot-id则会逐渐回溯全量数据
---- 指定了start-snapshot-id后,会从该snapshot的数据开始消费
---- 重启Flink应用时,若不指定上次关闭时的checkpoint或savepoint,则每次重启Flink应用都会从start-snapshot-id指定snapshot开始消费,导致重复消费历史数据
---- 重启Flink应用时,若指定了上次关闭时的checkpoint或savepoint,则会从上次消费的位点继续消费
select id,name,age,dt from `hadoop_iceberg_catalog`.`iceberg_db`.`hadoop_iceberg_table_flink_sql` /*+ OPTIONS('streaming'='true', 'monitor-interval'='5s', 'start-snapshot-id'='3821550127947089987')*/ ;
-- 4.在Hive中创建Iceberg映射表[只针对HadoopCatalog类型表]
create external table iceberg_db.hadoop_iceberg_table_flink_sql (
id BIGINT,
name STRING,
age INT,
dt STRING
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://nameservice/user/iceberg/warehouse/iceberg_db/hadoop_iceberg_table_flink_sql'
tblproperties ('iceberg.catalog'='location_based_table');
-- 5.HiveSQL查询(能查到实时最新数据)
select * from iceberg_db.hadoop_iceberg_table_flink_sql;
-- 6.FlinkSQL Upsert更新 基于累积窗口统计逻辑 (注意upsert次数过多会导致查询性能很差,如果频繁upsert,则需要频繁做compact来保证查询性能,可根据需要设置只保留1-3个snapshot)
CREATE TABLE if not exists `hive_iceberg_catalog`.`iceberg_db`.`summary_iceberg_table` (
actionid STRING,
userid STRING,
`success_cnt` bigint,
`failed_cnt` bigint,
window_start TIMESTAMP(3) NOT NULL,
window_end TIMESTAMP(3) NOT NULL,
ds STRING,
PRIMARY KEY(`actionid`,`userid`,`ds`) NOT ENFORCED -- 必须设置主键 根据主键upsert
) PARTITIONED BY (ds)
WITH('type'='ICEBERG',
'format-version'='2', -- 必须是v2表
'write.upsert.enabled'='true', -- 指定该参数 使表可upsert
'engine.hive.enabled'='true',
'read.split.target-size'='536870912',
'write.target-file-size-bytes'='268435456',
'write.format.default'='parquet',
'write.parquet.compression-codec'='zstd',
'write.parquet.compression-level'='10',
'write.avro.compression-codec'='zstd',
'write.avro.compression-level'='10',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5',
'write.distribution-mode'='hash');
INSERT INTO `hive_iceberg_catalog`.`iceberg_db`.`summary_iceberg_table` /*+ OPTIONS('upsert-enabled'='true') */ -- 需要指定'upsert-enabled'='true'
SELECT
actionid,
userid,
sum(cast(if(`error` = 'ok', 1, 0) as BIGINT)) AS success_cnt,
sum(cast(if(`error` <> 'ok', 1, 0) as BIGINT)) AS failed_cnt,
window_start,
window_end,
DATE_FORMAT(window_start, 'yyyyMMdd') AS ds
FROM
TABLE(
CUMULATE(
TABLE kafka_table,
DESCRIPTOR(event_time),
INTERVAL '1' MINUTES,
INTERVAL '1' DAY
)
)
GROUP BY
window_start,
window_end,
actionid,
userid;
-- 7. FlinkSQL Upsert更新 基于累积窗口计算TopN逻辑 (注意upsert次数过多会导致查询性能很差,如果频繁upsert,则需要频繁做compact来保证查询性能,可根据需要设置只保留1-3个snapshot)
CREATE TABLE if not exists `hive_iceberg_catalog`.`iceberg_db`.`top_iceberg_table` (
actionid STRING,
success_cnt bigint,
failed_cnt bigint,
ranking_num bigint,
window_start TIMESTAMP(3) NOT NULL,
window_end TIMESTAMP(3) NOT NULL,
ds STRING,
PRIMARY KEY(`actionid`,`ds`) NOT ENFORCED -- 必须设置主键 根据主键upsert
) PARTITIONED BY (ds)
WITH('type'='ICEBERG',
'format-version'='2', -- 必须是v2表
'write.upsert.enabled'='true', -- 指定该参数 使表可upsert
'engine.hive.enabled'='true',
'read.split.target-size'='536870912',
'write.target-file-size-bytes'='268435456',
'write.format.default'='parquet',
'write.parquet.compression-codec'='zstd',
'write.parquet.compression-level'='10',
'write.avro.compression-codec'='zstd',
'write.avro.compression-level'='10',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5',
'write.distribution-mode'='hash');
INSERT INTO `hive_iceberg_catalog`.`iceberg_db`.`user_experience_topn_action_report` /*+ OPTIONS('upsert-enabled'='true') */ -- 需要指定'upsert-enabled'='true'
SELECT * from (
SELECT
actionid,
success_cnt,
failed_cnt,
ROW_NUMBER() OVER (
PARTITION BY window_start,
window_end
ORDER BY
failed_cnt asc
) AS rn,
window_start,
window_end,
ds
from (
select
actionid,
sum(cast(if(`error` = 'ok', 1, 0) as BIGINT)) AS success_cnt,
sum(cast(if(`error` <> 'ok', 1, 0) as BIGINT)) AS failed_cnt,
window_start,
window_end,
DATE_FORMAT(window_end, 'yyyyMMdd') AS ds
FROM
TABLE(
CUMULATE(
TABLE kafka_shoulei_odl_odl_xlpan_server_log,
DESCRIPTOR(event_time),
INTERVAL '1' MINUTES,
INTERVAL '1' DAY
)
)
GROUP BY
window_start,
window_end,
actionid
) t_inner
) t_outer
where
rn <= 100;打通Kafka->Flink SQL->HiveCatalog类型Iceberg表->Hive/Trino
-- 写入Iceberg表[HiveCatalog类型]
-- 启动flink集群:cd $FLINK_HOME ; bin/start-cluster.sh
-- 启动FlinkSQL Console:bin/sql-client.sh embedded -j iceberg-flink-runtime-1.13-0.14.0.jar -j /opt/cloudera/parcels/CDH/jars/hive-metastore-2.1.1-cdh6.3.1.jar -j /opt/cloudera/parcels/CDH/jars/libthrift-0.9.3.jar -j /opt/cloudera/parcels/CDH/jars/hive-common-2.1.1-cdh6.3.1.jar -j /opt/cloudera/parcels/CDH/jars/hive-serde-2.1.1-cdh6.3.1.jar -j /opt/cloudera/parcels/CDH/jars/libfb303-0.9.3.jar -j /opt/cloudera/parcels/CDH/jars/hive-shims-common-2.1.1-cdh6.3.1.jar shell
set execution.checkpointing.interval=10sec; -- 必须设置checkpoint 靠checkpoint提交更新数据到Iceberg
SET execution.runtime-mode = streaming; -- 流式写
CREATE TABLE t_kafka_source (
id BIGINT,
name STRING,
age INT,
dt STRING
) WITH (
'connector' = 'kafka',
'topic' = 'flink_topic1',
'scan.startup.mode' = 'latest-offset',
'properties.bootstrap.servers' = 'cdh101:9092,cdh102:9092,cdh103:9092,cdh104:9092',
'properties.group.id' = 'test',
'format' = 'csv'
);
CREATE CATALOG hive_iceberg_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://cdh101:9083,thrift://cdh103:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://nameservice/user/iceberg/warehouse',
'hive-conf-dir'='/etc/ecm/hive-conf' -- 如果hive是kerberos认证的,必须要加hive-conf-dir参数,非kerberos集群可忽略
);
CREATE TABLE if not exists `hive_iceberg_catalog`.`iceberg_db`.`hive_iceberg_table_flink_sql` (
id BIGINT,
name STRING,
age INT,
dt STRING
) PARTITIONED BY (dt)
WITH('type'='ICEBERG',
'engine.hive.enabled'='true',
'read.split.target-size'='1073741824',
'write.target-file-size-bytes'='536870912',
'write.format.default'='parquet',
'write.parquet.compression-codec'='zstd',
'write.parquet.compression-level'='10',
'write.avro.compression-codec'='zstd',
'write.avro.compression-level'='10',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='5',
'write.distribution-mode'='none');
insert into hive_iceberg_catalog.iceberg_db.hive_iceberg_table_flink_sql select id,name,age,dt from t_kafka_source;写入HiveCatalogIceberg表后,在Hive可以直接看到并查询表iceberg_db.hive_iceberg_table_flink_sql.
也可以先在hive创建表,再Flink写入,均正常.
Trino中也可以直接看到并查询该表.
3. StreamPark集成Iceberg(基于HiveCatalog)
StreamPark是基于Flink SQL的流式计算平台.在StreamPark上可以很方便地开发实时操作Iceberg的Flink任务.
环境: Hadoop 3.2.1 + Hive 3.1.2 + Iceberg 0.14.1 + Flink 1.14.5 + StreamPark 1.2.4 + OSS
FlinkSQL编写:
CREATE CATALOG hive_iceberg_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://thrift-host:9083',
'clients'='5',
'property-version'='1',
'warehouse'='oss://bucket_name/data/iceberg/warehouse',
'hive-conf-dir'='/etc/ecm/hive-conf'
);
-- Kafka source table
CREATE TABLE t_kafka_source (
id BIGINT,
name STRING,
age INT,
dt STRING
) WITH (
'connector' = 'kafka',
'topic' = 't_qjj_flink_test',
'scan.startup.mode' = 'latest-offset',
'properties.bootstrap.servers' = 'broker1:9092,broker2:9092,broker3:9092',
'properties.group.id' = 'test',
'format' = 'csv'
);
-- Iceberg target table
CREATE TABLE IF NOT EXISTS `hive_iceberg_catalog`.`iceberg_db`.`hive_krb_iceberg_table_flink_sql` (
id BIGINT,
name STRING,
age INT,
dt STRING
) PARTITIONED BY (dt)
WITH('type'='ICEBERG',
'engine.hive.enabled'='true',
'read.split.target-size'='1073741824',
'write.target-file-size-bytes'='536870912',
'write.format.default'='parquet',
'write.parquet.compression-codec'='zstd',
'write.parquet.compression-level'='10',
'write.avro.compression-codec'='zstd',
'write.avro.compression-level'='10',
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'='10',
'write.distribution-mode'='none');
-- Insert data
insert into hive_iceberg_catalog.iceberg_db.hive_krb_iceberg_table_flink_sql select id,name,age,dt from t_kafka_source;依赖jar:
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-flink-runtime-1.14</artifactId>
<version>0.14.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-metastore</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libthrift</artifactId>
<version>0.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-common</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-serde</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hive.shims</groupId>
<artifactId>hive-shims-common</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.5</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.3.1</version>
</dependency>可能出现的异常:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.commons.cli.Option.builder(Ljava/lang/String;)Lorg/apache/commons/cli/Option$Builder;
at org.apache.flink.runtime.entrypoint.parser.CommandLineOptions.<clinit>(CommandLineOptions.java:27)原因: streamx在下载hive依赖时,下载了它的子依赖,且hive使用的commons-cli与streamx使用的commons-cli版本不一致,导致jar冲突.
解决: 每次build后手动删除hdfs dfs -rm -f hdfs://ns/streamx/workspace/项目ID/lib/commons-cli-1.2.jar
Iceberg与Trino集成
Trino整合Iceberg需要配置$TRINO_HOME/etc/catalog/iceberg.properties内容如下:
connector.name=iceberg
iceberg.file-format=PARQUET
hive.metastore.service.principal=hive/metastore-server-ip@realm-name
hive.metastore.authentication.type=KERBEROS
hive.metastore.uri=thrift://metastore-server-ip:9083,metastore-server-ip-bk:9083
hive.metastore.client.principal=principal-in-hive-keytab
hive.metastore.client.keytab=/path/to/hive.keytab
hive.config.resources=/etc/ecm/hadoop-conf/core-site.xml, /etc/ecm/hadoop-conf/hdfs-site.xml
iceberg.compression-codec=SNAPPY若需要其支持外部存储例如oss,则需要将jindo-core-4.3.0.jar和jindo-sdk-4.3.0.jar两个jar拷贝到$TRINO_HOME/plugin/iceberg/和$TRINO_HOME/plugin/hive/以兼容外部存储.
Trino当前仅支持HiveCatalog类型的Iceberg表,不支持HadoopCatalog类型Iceberg表.如果查询的是HadoopCatalog,location_based_table,Custome类型的Iceberg表会报错:Table is missing [metadata_location] property: iceberg_db.iceberg_table
Trino操作Iceberg表常用操作:
1.查看有哪些分区
select * from "iceberg_table$partitions";
2.查看有哪些快照
select * from "iceberg_table$snapshots";
SELECT snapshot_id,committed_at FROM "iceberg_table$snapshots" ORDER BY committed_at;
3.表优化 之 快照过期
ALTER TABLE iceberg_table EXECUTE expire_snapshots(retention_threshold => '7d')
4.表优化 之 文件合并
ALTER TABLE iceberg_table EXECUTE optimize [默认合并小于file_size_threshold的数据文件,file_size_threshold默认100MB]
ALTER TABLE iceberg_table EXECUTE optimize(file_size_threshold => '256MB')
ALTER TABLE iceberg_table EXECUTE optimize WHERE partition_key = 1 [按分区优化]
5.表优化 之 清理孤立无效的文件
ALTER TABLE iceberg_table EXECUTE remove_orphan_files(retention_threshold => '7d')
6.升级表的版本如V1升级到V2
ALTER TABLE iceberg_table SET PROPERTIES format_version = 2;
7.V2表根据条件进行行级删除操作 (V1表不支持行级删除,只支持分区条件删除)
delete from iceberg_table where ds='2022120102' and eventid = 'event_1';
8.修改分区之添加一个分区字段
ALTER TABLE iceberg_table SET PROPERTIES partitioning = ARRAY[<existing partition columns>, 'my_new_partition_column'];
9.修改表和字段注释 在Trino修改后同样会在Hive生效
COMMENT ON TABLE iceberg_table IS 'Table comment';
COMMENT ON COLUMN iceberg_table.name IS 'Column comment';
10.TimeTravel查询 临时查询历史某个快照的数据
SELECT * FROM iceberg.iceberg_db.iceberg_table FOR VERSION AS OF 8954597067493422955;
SELECT * FROM iceberg.iceberg_db.iceberg_table FOR TIMESTAMP AS OF TIMESTAMP '2022-12-02 09:59:29.803 Europe/Vienna';
11.回滚当前表状态到某个历史快照的状态
CALL iceberg.system.rollback_to_snapshot('iceberg_db', 'iceberg_table', 8954597067493422955);
12.查看表的文件和文件修改时间
select "$path", "$file_modified_time" from iceberg_table;
13.查询数据
select * from iceberg_table limit 10;
select * from "iceberg_table$data" limit 10; [等价于上面的SQL]
14.查看表配置参数
select * from "iceberg_table$properties";
15.查看表元数据更改历史记录
select * from "iceberg_table$history";
16.列出表涉及到的manifest file列表
select * from "iceberg_table$manifests";
17.列出表在当前快照(当前状态)下引用的所有数据文件
select * from "iceberg_table$files";
18.创建Trino物化视图 只支持Trino中查询
CREATE OR REPLACE MATERIALIZED VIEW iceberg_view COMMENT 'materializedView' WITH ( format = 'ORC', partitioning = ARRAY['ds'] ) as select appid,ds from iceberg_table;
CREATE MATERIALIZED VIEW IF NOT EXISTS iceberg_view COMMENT 'materializedView' WITH ( format = 'ORC', partitioning = ARRAY['ds'] ) as select appid,ds from iceberg_table;
REFRESH MATERIALIZED VIEW iceberg_view; [底层表数据变化导致物化视图与底层表数据不一致时,使用该命令更新物化视图]
19.如果查询很复杂并且包括连接大型数据集,则在表上运行ANALYZE可以通过收集有关数据的统计信息来提高查询性能
SET SESSION iceberg.experimental_extended_statistics_enabled = true;
ANALYZE iceberg_table;
ANALYZE iceberg_table WITH (columns = ARRAY['col_1', 'col_2']);
ALTER TABLE iceberg_table EXECUTE drop_extended_stats; [如果需要重新分析表统计信息,则再重新分析前先清除之前统计的信息]
20.创建表(本质也是创建HiveCatalog表,不建议在Trino建Iceberg表,因为Hive引擎无法支持)
CREATE TABLE iceberg_oss_table (
c1 integer,
c2 date,
c3 double
)
WITH (
format = 'PARQUET',
partitioning = ARRAY['c1', 'c2'],
location = 'oss://bucket-name/user/iceberg/warehouse/iceberg_oss_table'
);Iceberg与Spark集成
下载iceberg-spark-runtime-3.3_2.12-1.0.0.jar到$SPARK_HOME/jars路径
编辑$SPARK_HOME/conf/spark-defaults.conf添加如下内容
spark.sql.catalog.spark_catalog org.apache.iceberg.spark.SparkSessionCatalog
spark.sql.catalog.spark_catalog.type hiveSpark创建的Iceberg表打通Hive
-- Spark创建Iceberg表
CREATE TABLE spark_catalog.default.qjj_iceberg_test (
id bigint COMMENT 'unique id',
data string
) USING iceberg
LOCATION 'oss://bucket-name/user/hive/warehouse/qjj_iceberg_test';
-- Hive中兼容Spark创建的Iceberg表需要做的操作
ALTER TABLE qjj_iceberg_test SET FILEFORMAT INPUTFORMAT "org.apache.iceberg.mr.hive.HiveIcebergInputFormat" OUTPUTFORMAT "org.apache.iceberg.mr.hive.HiveIcebergOutputFormat" SERDE "org.apache.iceberg.mr.hive.HiveIcebergSerDe";
alter table qjj_iceberg_test set TBLPROPERTIES ('storage_handler'='org.apache.iceberg.mr.hive.HiveIcebergStorageHandler');注: Hive创建的Iceberg表可以直接被Spark读取
Iceberg表管理维护
数据实时写入Iceberg表会频繁发生Commit操作,产生大量元数据文件和数据文件,文件数膨胀和小文件问题会使其性能下降,甚至影响底层存储系统稳定性.目前Iceberg表并不能像Hudi一样自动处理小文件问题,需要一定的手动维护工作.
以下是发生31次commit后,Iceberg表目录树形结构.
hadoop_iceberg_partitioned_table
├── data
│ ├── dt=20221010
│ │ └── 00000-0-hive_20221102105407_0605b24c-e823-4244-a994-83887ea7e430-job_1667357081446_0002-00001.parquet
│ ├── dt=20221011
│ │ └── 00000-0-hive_20221102105315_5bb17fc0-3092-4bed-8839-253f19117b6d-job_1667357081446_0001-00001.parquet
│ └── dt=20221104
│ ├── 00000-0-shmily_20221104104344_a66cc954-b33c-48df-812c-cc59d609ec59-job_1667529535736_0001-00001.parquet
│ ├── 00000-0-shmily_20221104104714_7bc45bcf-b8dc-4730-b9b5-d0c92ae46d5d-job_1667529535736_0002-00001.parquet
│ ├── 00000-0-shmily_20221104104805_4a490286-3499-43fb-affb-4317e07128d1-job_1667529535736_0003-00001.parquet
│ ├── 00000-0-shmily_20221104104851_71127db1-1170-4a38-a3d4-83e296fd3330-job_1667529535736_0004-00001.parquet
│ ├── 00000-0-shmily_20221104105901_1d66566e-af6c-4311-b123-86cfd18e0102-job_1667529535736_0005-00001.parquet
│ ├── 00000-0-shmily_20221104110033_e6e579d7-b08f-48b1-9277-b51b318dec7c-job_1667529535736_0006-00001.parquet
│ ├── 00000-0-shmily_20221104110100_345a4caa-bb75-4ea4-be5c-51a2420c428d-job_1667529535736_0007-00001.parquet
│ ├── 00000-0-shmily_20221104110124_bbb8626e-3d06-48a4-be6a-3ef061be4122-job_1667529535736_0008-00001.parquet
│ ├── 00000-0-shmily_20221104110152_13d0e1a5-6630-4dc2-ae24-ee104cbca3b5-job_1667529535736_0009-00001.parquet
│ ├── 00000-0-shmily_20221104110158_4283a83a-2662-4a89-8311-e8f89fe64603-job_1667529535736_0010-00001.parquet
│ ├── 00000-0-shmily_20221104110218_66253aad-58ca-4121-b454-8383e1ae7aae-job_1667529535736_0011-00001.parquet
│ ├── 00000-0-shmily_20221104110245_c041e352-dacd-4f5e-9fb4-ca321b4b3468-job_1667529535736_0012-00001.parquet
│ ├── 00000-0-shmily_20221104110311_29653ebe-6426-4163-8ace-7b1d305c9253-job_1667529535736_0013-00001.parquet
│ ├── 00000-0-shmily_20221104110336_35708806-e3a6-4746-851a-e8d306812810-job_1667529535736_0014-00001.parquet
│ ├── 00000-0-shmily_20221104110400_d1949e60-6123-49ff-8a85-0281651cf0b2-job_1667529535736_0015-00001.parquet
│ ├── 00000-0-shmily_20221104110425_e0cdc030-7d88-4b5f-8956-c95ffd71e698-job_1667529535736_0016-00001.parquet
│ ├── 00000-0-shmily_20221104110448_e144f00c-60b7-4935-a749-d3d88eba828a-job_1667529535736_0017-00001.parquet
│ ├── 00000-0-shmily_20221104110513_01b3285c-a3c8-490c-bc3c-5dbd696824e8-job_1667529535736_0018-00001.parquet
│ ├── 00000-0-shmily_20221104110538_bbe889dd-8615-4019-b6cc-636d1503dc8c-job_1667529535736_0019-00001.parquet
│ ├── 00000-0-shmily_20221104110602_09da4a19-c2ac-46af-af6c-5d97a3fbdcd9-job_1667529535736_0020-00001.parquet
│ ├── 00000-0-shmily_20221104110627_b1544cff-a0c2-4310-a06a-cd6103e40e9d-job_1667529535736_0021-00001.parquet
│ ├── 00000-0-shmily_20221104110651_a7e21f79-764d-4e62-8174-109dc4f1e7e2-job_1667529535736_0022-00001.parquet
│ ├── 00000-0-shmily_20221104110716_a657cb8b-45be-4484-9a21-bc2814e0c6b1-job_1667529535736_0023-00001.parquet
│ ├── 00000-0-shmily_20221104110742_f0e29e2e-4225-4e42-9699-524a19dacf44-job_1667529535736_0024-00001.parquet
│ ├── 00000-0-shmily_20221104110805_1827ea66-b863-4ecb-adc2-285470309490-job_1667529535736_0025-00001.parquet
│ ├── 00000-0-shmily_20221104110831_1019e38e-4845-4792-83fb-39822e497983-job_1667529535736_0026-00001.parquet
│ ├── 00000-0-shmily_20221104110919_4f1e3e96-1d37-40f3-aa2e-2a0139170381-job_1667529535736_0027-00001.parquet
│ ├── 00000-0-shmily_20221104110943_9ff35be2-cec0-4389-843e-395c7c6ec428-job_1667529535736_0028-00001.parquet
│ └── 00000-0-shmily_20221104111008_7a8ca8e3-d4c6-4aa1-81b6-c79d6ba7dd4f-job_1667529535736_0029-00001.parquet
├── metadata
│ ├── 03710058-d552-4dc1-b9cb-9340729e8f5e-m0.avro
│ ├── 09fd33b8-c9ce-4f7c-b871-ca31f096e3b1-m0.avro
│ ├── 12169e7b-13cb-4393-8158-1c9effe14e8f-m0.avro
│ ├── 2e834cae-756b-4498-a82a-2418db4b1092-m0.avro
│ ├── 3486a62e-1d74-49bd-bad3-c61187fac97f-m0.avro
│ ├── 3a9351b4-388b-44d9-8243-4a11189d81b2-m0.avro
│ ├── 3d0a560f-06f4-4402-a388-0b3cc7e25598-m0.avro
│ ├── 40862af2-6d95-40b8-a979-2360ea3b7175-m0.avro
│ ├── 44671db7-02ca-47c1-a229-c7f62d8aa12f-m0.avro
│ ├── 551c586b-9c4d-4ca4-a0ef-d46c30fb01f8-m0.avro
│ ├── 5baf0fec-3247-48f3-84f6-2f6402e866c7-m0.avro
│ ├── 639416fc-47c0-452e-a1d9-f17864cf008f-m0.avro
│ ├── 63ab2797-6a07-4886-9c27-43765bc31851-m0.avro
│ ├── 74ca6f5e-4eab-45d9-b0b1-04ba48e53971-m0.avro
│ ├── 8a4ce917-5986-4a95-9573-62103a116559-m0.avro
│ ├── 90bcc77d-5516-4c3e-96c8-242713920b1b-m0.avro
│ ├── 9f87073d-4cbc-46e9-b4dd-42fc28c86726-m0.avro
│ ├── a4c74672-5ace-4a79-aca9-677926532794-m0.avro
│ ├── b0e01ba5-bbe9-4ce4-ad9e-f07ab774a041-m0.avro
│ ├── b1a2cd1f-e30a-4c45-9119-9ba0e185cc58-m0.avro
│ ├── b209efb3-aab3-4bc2-a821-0557a0cda8d3-m0.avro
│ ├── b7c5b752-49d4-4840-8990-fb4a84e0f71d-m0.avro
│ ├── b9ba125d-bd76-483d-94f7-f6a9b664f633-m0.avro
│ ├── bcc5bf7b-7f01-4969-9f4c-cc9c1c920029-m0.avro
│ ├── d5b51efd-32b4-4948-9cc8-f2422919f1d7-m0.avro
│ ├── d6492cb2-7012-4668-9af9-c25cbe4df95a-m0.avro
│ ├── e511d02d-ecd8-4a3f-b8b7-45ad864026dc-m0.avro
│ ├── e652600f-4167-4f59-92cc-45faf15b03b1-m0.avro
│ ├── f0e6c6ca-51a7-42e6-b412-4036e27c7d98-m0.avro
│ ├── f3646fc2-7e64-4395-8adc-cd6a75413d37-m0.avro
│ ├── f91de7e0-2bf3-4804-bb28-64b61ebc588f-m0.avro
│ ├── snap-1244418053907939374-1-44671db7-02ca-47c1-a229-c7f62d8aa12f.avro
│ ├── snap-1477308230043616149-1-f91de7e0-2bf3-4804-bb28-64b61ebc588f.avro
│ ├── snap-1490572932134542813-1-5baf0fec-3247-48f3-84f6-2f6402e866c7.avro
│ ├── snap-1778869542790618047-1-12169e7b-13cb-4393-8158-1c9effe14e8f.avro
│ ├── snap-2054318792294634903-1-f3646fc2-7e64-4395-8adc-cd6a75413d37.avro
│ ├── snap-2520326235035414997-1-b7c5b752-49d4-4840-8990-fb4a84e0f71d.avro
│ ├── snap-3185789235788477057-1-e652600f-4167-4f59-92cc-45faf15b03b1.avro
│ ├── snap-3406584701390941146-1-b209efb3-aab3-4bc2-a821-0557a0cda8d3.avro
│ ├── snap-3684994728472824032-1-9f87073d-4cbc-46e9-b4dd-42fc28c86726.avro
│ ├── snap-3706799770416474623-1-a4c74672-5ace-4a79-aca9-677926532794.avro
│ ├── snap-3951591399252751391-1-3a9351b4-388b-44d9-8243-4a11189d81b2.avro
│ ├── snap-4081427338556096982-1-d5b51efd-32b4-4948-9cc8-f2422919f1d7.avro
│ ├── snap-4367759472594176887-1-b0e01ba5-bbe9-4ce4-ad9e-f07ab774a041.avro
│ ├── snap-4477640749996566080-1-63ab2797-6a07-4886-9c27-43765bc31851.avro
│ ├── snap-4792262885242972970-1-551c586b-9c4d-4ca4-a0ef-d46c30fb01f8.avro
│ ├── snap-501818490576080743-1-3486a62e-1d74-49bd-bad3-c61187fac97f.avro
│ ├── snap-558299450529529123-1-bcc5bf7b-7f01-4969-9f4c-cc9c1c920029.avro
│ ├── snap-6000755959745218957-1-09fd33b8-c9ce-4f7c-b871-ca31f096e3b1.avro
│ ├── snap-6590633258547705279-1-639416fc-47c0-452e-a1d9-f17864cf008f.avro
│ ├── snap-70006429373167712-1-d6492cb2-7012-4668-9af9-c25cbe4df95a.avro
│ ├── snap-7258286604987289050-1-03710058-d552-4dc1-b9cb-9340729e8f5e.avro
│ ├── snap-7353150060042609479-1-e511d02d-ecd8-4a3f-b8b7-45ad864026dc.avro
│ ├── snap-7512257803790292671-1-b9ba125d-bd76-483d-94f7-f6a9b664f633.avro
│ ├── snap-7520911403174383355-1-90bcc77d-5516-4c3e-96c8-242713920b1b.avro
│ ├── snap-7612339408675772086-1-40862af2-6d95-40b8-a979-2360ea3b7175.avro
│ ├── snap-7688152750730458585-1-f0e6c6ca-51a7-42e6-b412-4036e27c7d98.avro
│ ├── snap-8654338094020315416-1-8a4ce917-5986-4a95-9573-62103a116559.avro
│ ├── snap-8685114841540976719-1-b1a2cd1f-e30a-4c45-9119-9ba0e185cc58.avro
│ ├── snap-8693851636236625016-1-2e834cae-756b-4498-a82a-2418db4b1092.avro
│ ├── snap-8855760427151465849-1-3d0a560f-06f4-4402-a388-0b3cc7e25598.avro
│ ├── snap-9102081850556452524-1-74ca6f5e-4eab-45d9-b0b1-04ba48e53971.avro
│ ├── v1.metadata.json
│ ├── v2.metadata.json
│ ├── v3.metadata.json
│ ├── v4.metadata.json
│ ├── v5.metadata.json
│ ├── v6.metadata.json
│ ├── v7.metadata.json
│ ├── v8.metadata.json
│ ├── v9.metadata.json
│ ├── v10.metadata.json
│ ├── v11.metadata.json
│ ├── v12.metadata.json
│ ├── v13.metadata.json
│ ├── v14.metadata.json
│ ├── v15.metadata.json
│ ├── v16.metadata.json
│ ├── v17.metadata.json
│ ├── v18.metadata.json
│ ├── v19.metadata.json
│ ├── v20.metadata.json
│ ├── v21.metadata.json
│ ├── v22.metadata.json
│ ├── v23.metadata.json
│ ├── v24.metadata.json
│ ├── v25.metadata.json
│ ├── v26.metadata.json
│ ├── v27.metadata.json
│ ├── v28.metadata.json
│ ├── v29.metadata.json
│ ├── v30.metadata.json
│ ├── v31.metadata.json
│ ├── v32.metadata.json
│ └── version-hint.text
└── temp其中有32个MetadataFile文件(metadata.json),31个ManifestList文件(snap-*.avro),31个ManifestFile文件(xx-m0.avro)以及31个DataFile(xx.parquet)文件.
n次commit会带来3n+1个文件落盘.
执行清理(合并数据文件->清理过期快照->重写ManifestFile->清理孤立文件)后,小文件数量多的问题会有明显改善,结果如下:
hadoop_iceberg_partitioned_table_after
├── data
│ ├── dt=20221010
│ │ ├── 00000-0-hive_20221102105407_0605b24c-e823-4244-a994-83887ea7e430-job_1667357081446_0002-00001.parquet
│ │ ├── 00000-1-5ea18300-180b-465d-8310-bbbf422e15b8-00001.parquet
│ │ ├── 00000-1-78fcc067-f967-465f-be58-f5beff8561dd-00001.parquet
│ │ ├── 00000-2-be5c1e4a-254f-4503-9ff5-f8817a9e92f7-00001.parquet
│ │ └── 00000-613-8bdfbded-0300-425a-8201-031920536100-00001.parquet
│ ├── dt=20221011
│ │ ├── 00000-0-d75b9b2f-4794-42e2-94fe-f6ae22ccd7d9-00001.parquet
│ │ ├── 00000-0-hive_20221102105315_5bb17fc0-3092-4bed-8839-253f19117b6d-job_1667357081446_0001-00001.parquet
│ │ ├── 00000-2-1402730f-cc62-4daf-a47e-a8aecaa545c8-00001.parquet
│ │ ├── 00000-2-73f4cb74-1ab1-494d-ba4d-242b070bb82d-00001.parquet
│ │ └── 00000-611-6edbc04e-0919-4ae4-be30-89a8b91478e6-00001.parquet
│ └── dt=20221104
│ ├── 00000-0-11b9e51d-1ebd-496c-ae07-9e480c92c35e-00001.parquet
│ ├── 00000-0-274072c6-cefa-4395-ab31-016eacd19f08-00001.parquet
│ ├── 00000-0-ad26a63a-9b36-4c7d-9cb9-109aafae96fc-00001.parquet
│ ├── 00000-1-bd95039f-65c4-4b19-938e-185d615e3e0d-00001.parquet
│ └── 00000-612-73dd262d-7377-42f7-87e8-024447dc6fd6-00001.parquet
├── metadata
│ ├── 6d24ddd9-be10-42f3-a5d6-4551ee5a8bf0-m0.avro
│ ├── 79077b45-29e8-4d19-89a0-aef243b6a4ca-m0.avro
│ ├── 79077b45-29e8-4d19-89a0-aef243b6a4ca-m1.avro
│ ├── 7f9cc85d-0de4-4c4c-bde7-54d4f4f78447-m0.avro
│ ├── ae99e2ab-fcc5-44b0-bd94-f2d73eab22f3-m0.avro
│ ├── ae99e2ab-fcc5-44b0-bd94-f2d73eab22f3-m1.avro
│ ├── d2eeb7b2-9607-4c5b-bdc5-6cfe2c81ed94-m0.avro
│ ├── e52f34b0-ff45-4207-87a0-95b1897da11a-m0.avro
│ ├── e52f34b0-ff45-4207-87a0-95b1897da11a-m1.avro
│ ├── e715d26c-152c-4ff3-9533-7860d920503d-m0.avro
│ ├── e715d26c-152c-4ff3-9533-7860d920503d-m1.avro
│ ├── snap-2296367325872747730-1-e715d26c-152c-4ff3-9533-7860d920503d.avro
│ ├── snap-3114464783889165727-1-6d24ddd9-be10-42f3-a5d6-4551ee5a8bf0.avro
│ ├── snap-4397206702551297792-1-ae99e2ab-fcc5-44b0-bd94-f2d73eab22f3.avro
│ ├── snap-5015314203544980905-1-7f9cc85d-0de4-4c4c-bde7-54d4f4f78447.avro
│ ├── snap-761586103173871579-1-79077b45-29e8-4d19-89a0-aef243b6a4ca.avro
│ ├── snap-8390029841836840556-1-d2eeb7b2-9607-4c5b-bdc5-6cfe2c81ed94.avro
│ ├── snap-8895954507409072148-1-e52f34b0-ff45-4207-87a0-95b1897da11a.avro
│ ├── v38.metadata.json
│ ├── v39.metadata.json
│ ├── v40.metadata.json
│ ├── v41.metadata.json
│ ├── v42.metadata.json
│ ├── v43.metadata.json
│ └── version-hint.text
└── tempmetadata数控制
在Iceberg中,每次触发事务提交都会生成一个metadata.json,应当避免metadata文件无限增长,可以在建表时指定如下参数:
'write.metadata.delete-after-commit.enabled'='true' # 发生commit后,是否删除比较旧的metadata文件
'write.metadata.previous-versions-max'='9' # 保留的最大历史metadata文件数量,超过该历史版本数量的老的metadata文件会被删除这样可以自动控制MetadataFile文件数为9个.
清理过期snapshot
清理Iceberg表过期快照的Demo
Flink实现:
ClearExpiredSnapshots
Spark实现:
SparkIcebergTableMaintenance$expireSnapshots
数据文件重写
流式数据写入可能会产生大量小的数据文件,Iceberg提供了rewriteDataFiles(Compaction)操作,可以定期合并小文件,提高查询性能.
SparkIcebergTableMaintenance$compactDataFiles
元数据文件重写
每次Commit都会产生一个metadata文件,随着时间的推移,实时任务写入的MetadataFile数越来越多,做合并可以降低文件数,提升查询效率.
SparkIcebergTableMaintenance$rewriteManifests
清理孤立文件
SparkIcebergTableMaintenance$removeOrphanFiles
异常处理
ManifestFile文件丢失
2023-01-30 09:36:57,558 WARN org.apache.flink.runtime.taskmanager.Task [] - IcebergFilesCommitter -> Sink: IcebergSink (1
/1)#0 (2125b52f518a53194e79e9f5d86dbb78) switched from RUNNING to FAILED with failure cause: org.apache.iceberg.exceptions.NotFoundException:
Failed to open input stream for file: oss://xxxxx/user/hive/warehouse/iceberg_db/xxxxx/metadata/f86794c3-750d-4def-ad2d-b726c4c210ad-m0.avro
at org.apache.iceberg.hadoop.HadoopInputFile.newStream(HadoopInputFile.java:183)
at org.apache.iceberg.avro.AvroIterable.newFileReader(AvroIterable.java:100)
at org.apache.iceberg.avro.AvroIterable.getMetadata(AvroIterable.java:65)
at org.apache.iceberg.ManifestReader.<init>(ManifestReader.java:115)
at org.apache.iceberg.ManifestFiles.read(ManifestFiles.java:91)
at org.apache.iceberg.SnapshotProducer.newManifestReader(SnapshotProducer.java:448)
at org.apache.iceberg.MergingSnapshotProducer$DataFileMergeManager.newManifestReader(MergingSnapshotProducer.java:1005)
at org.apache.iceberg.ManifestMergeManager.createManifest(ManifestMergeManager.java:175)
at org.apache.iceberg.ManifestMergeManager.lambda$mergeGroup$1(ManifestMergeManager.java:156)
at org.apache.iceberg.util.Tasks$Builder.runTaskWithRetry(Tasks.java:402)
at org.apache.iceberg.util.Tasks$Builder.access$300(Tasks.java:68)
at org.apache.iceberg.util.Tasks$Builder$1.run(Tasks.java:308)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.FileNotFoundException: ErrorCode : 25002 , ErrorMsg: File not found. [RequestId]: ...原因: 可能合并任务异常导致
解决:
// 将丢失ManifestFile文件从元数据中移除,以解决表不可用的问题
String lostManifestFilePath = "xxxxx"
Table table = getTable(dbName, tabName);
Snapshot snapshot = table.currentSnapshot();
List<ManifestFile> manifestFiles = snapshot.allManifests(table.io());
List<ManifestFile> manifestFileDeletes = new ArrayList<>();
for (ManifestFile manifestFile : manifestFiles) {
String path = manifestFile.path();
if (path.equals(lostManifestFilePath)) {
manifestFileDeletes.add(manifestFile);
break;
}
}
if (manifestFileDeletes.isEmpty()) {
throw new Exception(StringUtils.format("Manifest File:%s not in metadata",lostManifestFilePath));
}
RewriteManifests rewriteManifests = table.rewriteManifests();
for (ManifestFile manifestFile : manifestFileDeletes) {
rewriteManifests.deleteManifest(manifestFile);
}
rewriteManifests.commit();
// 代码执行过程中可能抛出org.apache.iceberg.exceptions.ValidationException:Replaced and created manifests must have the same number of active files: 0 (new), 5567 (old)
// 修改iceberg-core位于core/src/main/java/org/apache/iceberg/BaseRewriteManifests.java activeFilesCount方法注释掉如下两行
// activeFilesCount += manifest.addedFilesCount();
// activeFilesCount += manifest.existingFilesCount();Flink写入Iceberg无法找到avro文件,导致任务报错无法写入
org.apache.iceberg.exceptions.NotFoundException: Failed to open input stream for file: oss://bucket_name/user/hive/warehouse/iceberg_db/user_experience_report/metadata/32759abff25a1366837ed3d146e27d51-55f7b63bf1c8c02b88d8659b98477e64-00000-2-71-00037.avro
at org.apache.iceberg.hadoop.HadoopInputFile.newStream(HadoopInputFile.java:183)
at org.apache.iceberg.avro.AvroIterable.newFileReader(AvroIterable.java:100)
at org.apache.iceberg.avro.AvroIterable.getMetadata(AvroIterable.java:65)
at org.apache.iceberg.ManifestReader.<init>(ManifestReader.java:115)
at org.apache.iceberg.ManifestFiles.read(ManifestFiles.java:91)
at org.apache.iceberg.ManifestFiles.read(ManifestFiles.java:72)
at org.apache.iceberg.flink.sink.FlinkManifestUtil.readDataFiles(FlinkManifestUtil.java:58)
at org.apache.iceberg.flink.sink.FlinkManifestUtil.readCompletedFiles(FlinkManifestUtil.java:113)
at org.apache.iceberg.flink.sink.IcebergFilesCommitter.commitUpToCheckpoint(IcebergFilesCommitter.java:244)
at org.apache.iceberg.flink.sink.IcebergFilesCommitter.initializeState(IcebergFilesCommitter.java:184)
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.initializeOperatorState(StreamOperatorStateHandler.java:119)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:286)
at org.apache.flink.streaming.runtime.tasks.RegularOperatorChain.initializeStateAndOpenOperators(RegularOperatorChain.java:109)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreGates(StreamTask.java:711)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.call(StreamTaskActionExecutor.java:55)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restoreInternal(StreamTask.java:687)
at org.apache.flink.streaming.runtime.tasks.StreamTask.restore(StreamTask.java:654)
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:958)
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:766)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:575)
at java.lang.Thread.run(Thread.java:748)
......可能原因: 此文件不是MainfestList文件也不是ManifestFile文件,而是Flink写入Iceberg时一种中间状态的文件,可能原因是checkpoint超时或时间过长,但该异常与合并和清理任务无关
解决:
hdfs dfs -ls -r -t oss://bucket_name/user/hive/warehouse/iceberg_db/user_experience_report/metadata/ | grep avro | grep -v snap | grep -v m0 | grep -v m1 | grep -v m2 | grep -v m3
找到最新avro 拷贝并重命名为缺失的avro 同时优化checkpoint稳定性HiveCatalog下锁表造成提交commit失败
23/05/14 03:32:34 INFO ApplicationMaster: Final app status: FAILED, exitCode: 15, (reason: User class threw exception: org.apache.iceberg.exceptions.CommitFailedException: Timed out after 183898 ms waiting for lock on iceberg_db.user_experience_report_user_details解决:到Hive元数据库select * from metastore.hive_locks; DELETE FROM metastore.hive_locks WHERE HL_DB=’iceberg_db’ AND HL_TABLE=’user_experience_report_user_details’;再重跑iceberg任务即可
对比Hudi和DeltaLake
| 对比维度\技术 | Iceberg | Hudi | DeltaLake |
|---|---|---|---|
| 数据管理 | 通过metadata文件管理 | 通过metadata文件管理 | 通过metadata文件管理 |
| 使用场景 | 流批一体,高性能分析与可靠数据管理 | 流批一体,Upsert场景 | 流批一体,融合Spark生态 |
| ACID | 支持 | 支持 | 支持 |
| ACID隔离级别 | Write Serialization(写串行执行) | Snapshot Isolation(写数据若无交集则并发写,否则串行) | Serialization(读写都必须串行)/Write Serialization/Snapshot Isolation |
| Schema演化 | 支持 | 支持 | 支持 |
| 数据操作 | 支持Update/Delete | 支持Upsert/Delete | 支持Update/Delete/Merge |
| 流式读 | 支持 | 支持 | 支持 |
| 流式写 | 支持 | 支持 | 支持 |
| 并发控制 | 乐观 | 乐观 | 乐观 |
| 文件清理 | 手动 | 自动 | 手动 |
| Compaction | 手动 | 自动 | 手动 |
| 外部依赖 | 完全解耦 | 依赖Spark | 依赖Spark |
| CopyOnWrite | 支持 | 支持 | 支持 |
| MergeOnRead | v2表支持,v1表不支持 | 支持 | 不支持 |
| 字段加密 | v3表计划支持 | 不支持 | 不支持 |



