







QCon全球软件开发大会

全球软件开发大会是为团队领导者、架构师、项目经理和高级软件开发人员量身打造的企业软件开发大会,其所覆盖的主题内容与InfoQ网站相同,关注架构与设计、真实案例分析等等。秉承”促进软件开发领域知识与创新的传播”原则,QCon各项议题专为中高端技术人员设计,内容源于实践并面向社区。演讲嘉宾依据各重点和热点话题,分享技术趋势和最佳实践。
**了解更多请戳👉 QCon官网 **
犹豫去不去
QCon是为团队领导者、架构师、项目经理和高级软件开发人员量身打造的企业软件开发大会,如果你们公司买了票给机会参加,那就要珍惜呀!看看还是很有好处的,选自己感兴趣的方向场次参加,可以扩宽思路,你会发现我们要解决的问题其实还有更多解决方案!哪怕有听不懂的地方,记下来回去查都很受益!
分享我所听
因为我只参加了18号下午场的QCon,所以也只听了不到四个分享会,但我会把我觉得很有用的技术或者思路分享出来!
Splash Shuffle Manager

关于Spark的Shuffle
Shuffle简而言之:下一个Stage向上一个Stage要数据这个过程,就称之为 Shuffle.
学过Spark的童鞋都知道大多数Spark作业的运行时间主要浪费在Shuflle过程中,因为该过程包含了大量的本地磁盘IO,网络IO和序列化过程.而看过Spark源码的童鞋应该都知道Spark的ShuffleManager,虽然Spark2.x已经摒弃了HashShuffleManager,但是如果过大的表遇到”去重”,”聚合”,”排序”,”重分区”或”集合”操作等shuffle算子时还是会有大量文件落盘,而本地磁盘的性能会严重拖慢Spark计算的整体速度. 而且Shuffle发生的机器如果发生故障还会导致Stage重算,性能和稳定性都大大降低
有些大规模的计算是Shuffle调优不能解决的
Splash介绍
关于以上问题,我们可以通过更改Shuffle Manager的源码来实现自定义Shuffle的溢写文件存储位置,但是,改源码辣么难……咋办……
Splash-支持指定Shuffle过程溢写文件的存储位置
- 可以指定Shuffle文件存储到高可靠的分布式存储中
- ShuffleFile接口代替本地文件访问
- 可以使用不同的网络传输和后端存储协议来实现随机读取和写入
Splash Shuffle Manager优点
- 使Executor变为无状态
- 使添加删除节点更有灵活性,宕机无需重复计算整个shuffle文件
- Shuffle文件提交符合原子性,未提交的文件可以轻松清理
- 随机存储和计算的分离,提供Shuffle存储介质的更多选择
- Splash Shuffle Manager位于Executor上,降低部署难度
- Shuffle Performance Tool可以检验存储介质性能
Splash结构和原理
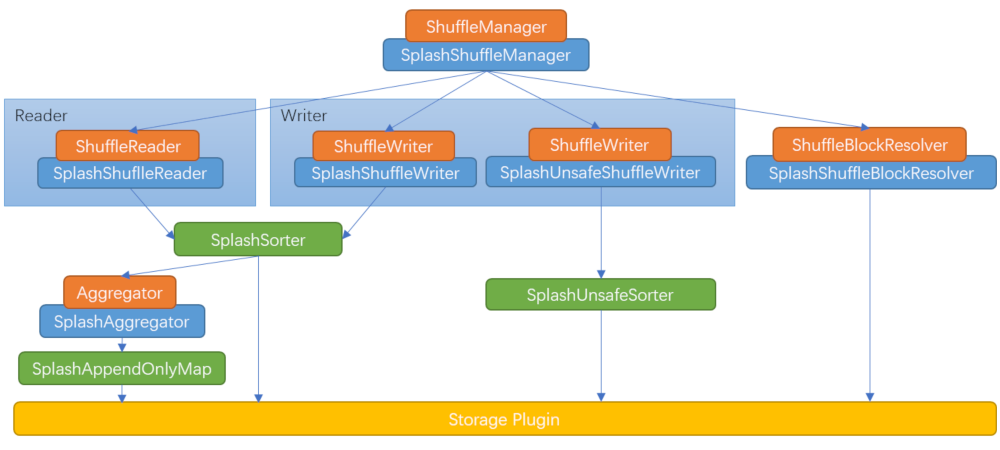
如图蓝色框为Splash实现类,橙色框是Spark定义的接口,绿色框是基本数据结构
使用Splash后的Shuffle过程:
ShuffleManager是入口,ShuffleWriter在map stage写shuffle数据,用SplashSorter或SplashUnsafeSorter将数据保存在内存中,内存不足时则会将数据溢写到TmpShuffleFile,等所有数据计算完成,SplashSorter或SplashUnsafeSorter,合并内存文件和溢写文件,SplashAggregator负责数据聚合,使用SplashAppendOnlyMap数据结构,内存不够时持久化到shuffle数据存储系统;ShuffleReader从shuffle数据存储系统收集reduce stage需要的数据,SplashShuffleBlockResolver用来查找随即数据,是无状态的.
我认为
我认为Splash的设计比较符合Spark计算与存储分离的理念,所以Splash的思路是好的,但展望Spark3.0的新特性,也发现了其实Spark3.0也有一个新特性叫”Remote Shuffle Service”,Remote Shuffle Service的基本想法是,如果Map Task能将Shuffle数据写到独立的Shuffle服务,然后Reduce Task从这个Shuffle服务读Shuffle数据,这样计算节点就不再需要为Shuffle任务保留本地磁盘空间了。这个理念与Splash这个项目的理念很相近,所以我们可以尝试和部署Splash也可以期待Spark3.0的新特性!
最后附上:
Splash项目的Git地址
英特尔持久内存

Intel Optane DC Persistent Memory,专为数据中心使用而设计的新的内存和存储技术
特性就是有媲美DRAM的性能(较DRAM略差)和有SSD一般的容量大小(目前单条512GB),一定程度消除吞吐量瓶颈
对大数据计算还是有一定加成的,这里我就不做广告啦,毕竟没有广告费哈哈!
其他
什么DBDK?
这是我听到的名词,搜了一下觉得还挺厉害…不能怪我孤陋寡闻.DBDK出的时候我连HelloWorld都还不会…
数据平面开发套件,可以极大提高数据处理性能和吞吐量,提高数据平面应用程序的工作效率。DPDK使用了轮询(polling)而不是中断来处理数据包。在收到数据包时,经DPDK重载的网卡驱动不会通过中断通知CPU,而是直接将数据包存入内存,交付应用层软件通过DPDK提供的接口来直接处理,这样节省了大量的CPU中断时间和内存拷贝时间。什么推荐中台?
推荐中台是个很新的名词吧…
我没怎么接触推荐这块,听的要睡着了…
嗯,这场分享就是爱奇艺推荐中台…
上链接吧:爱奇艺推荐中台:从搭建到上线仅10天,效率提升超30%什么数据中台?
分三部分:数据仓库,大数据中间件,数据资产管理
主要元素:累计接入应用数,服务调用,数仓核心表…
主要作用:解决数据管控问题,知道谁用.用在哪
数据中台能力: 数据资产管理,数据质量管理,数据模型管理,构建标签体系,数据应用规划及实现
上链接吧:什么是数据中台,关于数据中台最好的解读
写在最后
QCon让我学到了很多东西,扩展了思路,鼓励我在学习新技术的道路上奋勇向前!感觉对新技术更加感兴趣了,如果下次还有机会参加那该多好呀!话说是不是我下次再去就能听懂那些大佬说的东西了吧…
做个简单的总结吧
- 对新技术要仔细调研,琢磨存在的问题
- 对于陌生的技术要先明白它是做什么的,对扩宽思路有很大帮助
- 编程不仅是写代码,更要考虑性能,安全性和稳定性
- 一个新架构的出现必然有其优势,仔细思考它带来的影响
我顺便在会场周边玩了一圈,贴几张自认为不是直男拍的照片:
 |
 |
 |
 |
 |
 |
 |
 |



