








什么是Alluxio
Alluxio 是世界上第一个虚拟的分布式存储系统,它为计算框架和存储系统构建了桥梁,使计算框架能够通过一个公共接口连接到多个独立的存储系统,使计算与存储隔离。 Alluxio 是内存为中心的架构,以内存速度统一了数据访问速度,使得数据的访问速度能比现有方案快几个数量级,为大数据软件栈带来了显著的性能提升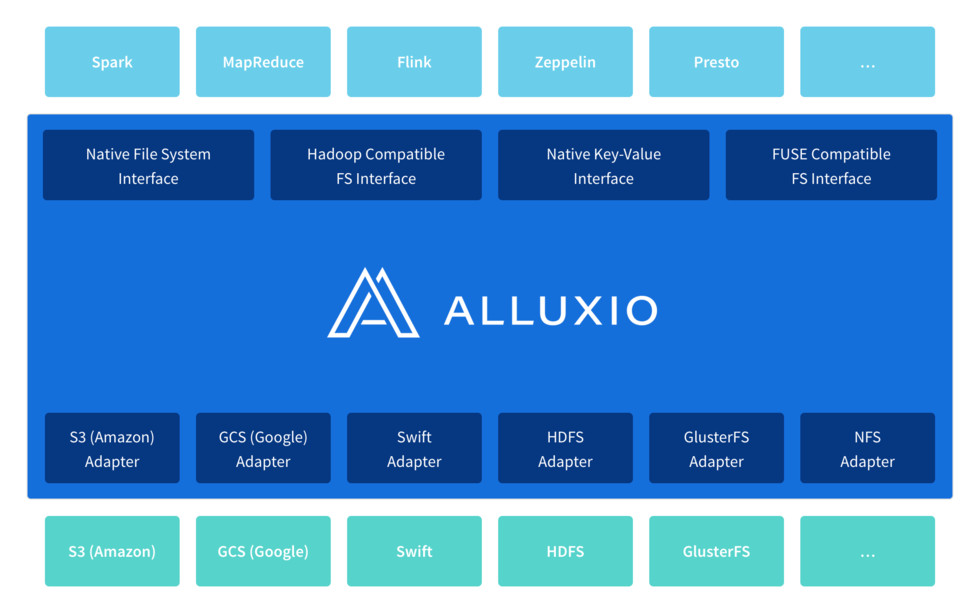
在大数据生态系统中,Alluxio 位于数据驱动框架或应用(如 Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache Flink)和各种持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack Swift、GlusterFS、HDFS、IBM Cleversafe、EMC ECS、Ceph、NFS 和 Alibaba OSS)之间,Alluxio 统一了存储在这些不同存储系统中的数据,为其上层数据框架提供统一的客户端API和全局命名空间
Alluxio最新动态:
为了方便大家可以持续跟进Alluxio发展动态,这里给出两条跟进Alluxio最新发展和动态的途径:
Alluxio官方文档
Alluxio知乎专栏
Alluxio优势
- 内存速度 I/O:Alluxio 能够用于分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供近似于内存级 I/O 吞吐率,同时提升稳定性。
- 简化云存储和对象存储接入:与传统文件系统相比,云存储系统和对象存储系统使用不同的语义,这些语义对性能的影响也不同于传统文件系统。常见的文件系统操作(如列出目录和重命名)通常会导致显著的性能开销。当访问云存储中的数据时,应用程序没有节点级数据本地性或跨应用程序缓存。将 Alluxio 与云存储或对象存储一起部署可以缓解这些问题,因为这样将从Alluxio中检索读取数据,而不是从底层云存储或对象存储中检索读取。
- 简化数据管理:Alluxio 提供对多数据源的单点访问,便捷地管理远程的存储系统,并向上层提供统一的命名空间。除了连接不同类型的数据源之外,Alluxio 还允许用户同时连接到不同版本的同一存储系统,如多个版本的HDFS,并且无需复杂的系统配置和管理,提高了数据访问灵活性。
- 应用程序部署简易:Alluxio 管理应用程序和文件或对象存储之间的通信,将应用程序的数据访问请求转换为底层存储接口的请求。Alluxio 与 Hadoop 兼容,现有的数据分析应用程序,如Spark和MapReduce程序,无需更改任何代码就能在Alluxio上运行。
- 分层存储特性:综合使用了内存、SSD和磁盘多种存储资源。通过Alluxio提供的LRU、LFU等缓存策略可以保证热数据一直保留在内存中,冷数据则被持久化到level 2甚至level 3的存储设备上
- 方便迁移可插拔:Alluxio提供多种易用的API方便将整个系统迁移到Alluxio
Alluxio的特征:
对Alluxio的优势和特征进行了概括 点击可进入官网介绍
超大规模工作负载:支持超大规模工作负载并具有HA高可用性
灵活的API :计算框架可使用HDFS、S3、Java、RESTful或POSIX为基础的API来访问Alluxio
智能数据缓存和分层 : 使用包括内存在内的本地存储,来充当分布式缓存,很大程度上改善I/O性能,且缓存对用户透明
存储系统接口 : 通过一系列接口集成HDFS,S3,Azure Blob Store,Google Cloud Store等存储系统
统一全局命名空间 : 多个存储系统安装到一个统一的名称空间中,不需要创建永久数据副本,方便管理多数据源
安全性 : 通过内置审核、基于角色的访问控制、LDAP、活动目录和加密通信,提供数据保护
监控和管理 : 提供了用户友好的Web界面和命令行工具,允许用户监控和管理集群
分层次的本地性 : 将更多的读写安排在本地,实现成本和性能的优化
Alluxio的应用场景
Alluxio 的落地非常依赖场景,否则优化效果并不明显(无法发挥内存读取的优势)
1.计算应用需要反复访问远程云端或机房的数据(存储计算分离)
2.混合云,计算与存储分离,异构的数据存储带来的系统耦合(Alluxio提供统一命名空间,统一访问接口)
3.多个独立的大数据应用(比如不同的Spark Job)需要高速有效的共享数据(数据并发访问)
4.计算框架所在机器内存占用较高,GC频繁,或者任务失败率较高,Alluxio通过数据的OffHeap来减少GC开销
5.有明显热表/热数据,相同数据被单应用多次访问
6.需要加速人工智能云上分析(如TensorFlow本地训练,可通过FUSE挂载Alluxio FS到本地)
我也做了很多Allxuio的性能测试工作,效果都不是很理想,有幸与Alluxio PMC范斌和李浩源交流了测试结果不如人意的原因,大佬是这么说的:”如果HDFS本身已经和Spark和Hive共置了,那么这个场景并不算Alluxio的目标场景。计算和存储分离的情况下才会有明显效果,否则通常是HDFS已经成为瓶颈时才会有帮助。“
还有,如果HDFS部署在计算框架本地,作业的输入数据可能会存在于系统的高速缓存区,则Alluxio对数据加速也并不明显。
所以:应用场景很关键,新技术产生时,一定要了解其应用场景和原理并经过考虑之后再做一些性能测试之类的后续工作!
官方介绍的Alluxio应用场景
Alluxio原理
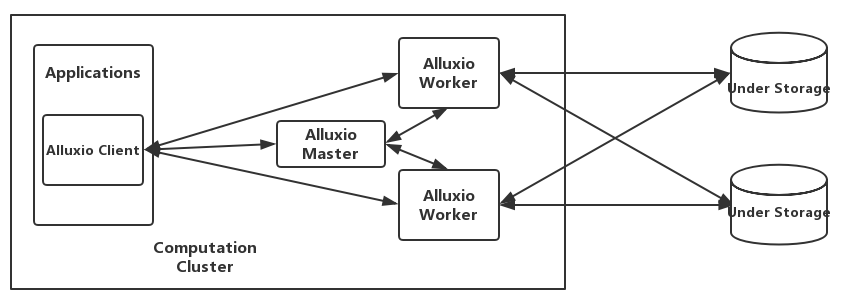
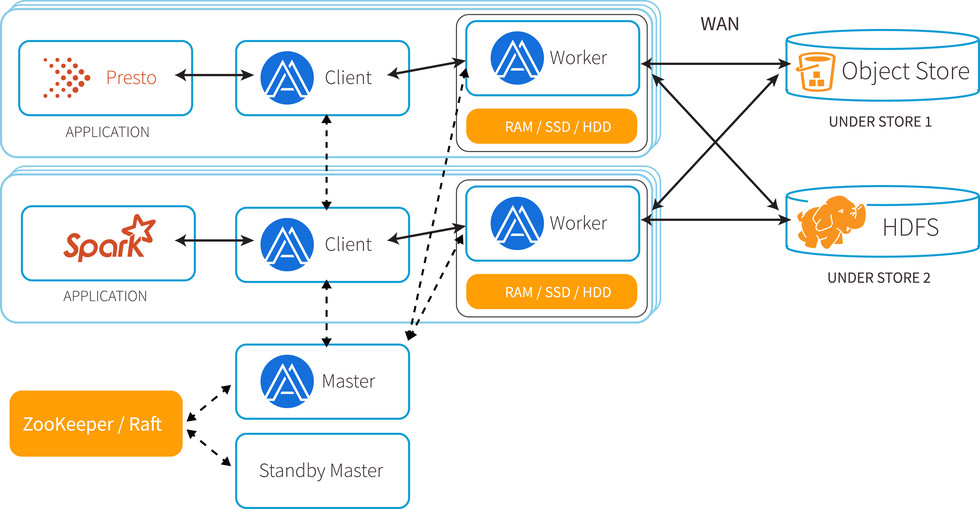
如图,一个完整的Alluxio集群部署在逻辑上包括master、worker、client及底层存储(UFS)。master和worker进程通常由集群管理员维护和管理,它们通过RPC通信相互协作,从而构成了Alluxio服务端。而应用程序则通过Alluxio Client来和Alluxio服务交互,读写数据或操作文件、目录。
Alluxio核心组件
Alluxio使用了单Master和多Worker的架构,Master和Worker一起组成了Alluxio的服务端,它们是系统管理员维护和管理的组件,Client通常是应用程序,如Spark或MapReduce作业,或者Alluxio的命令行用户。Alluxio用户一般只与Alluxio的Client组件进行交互。
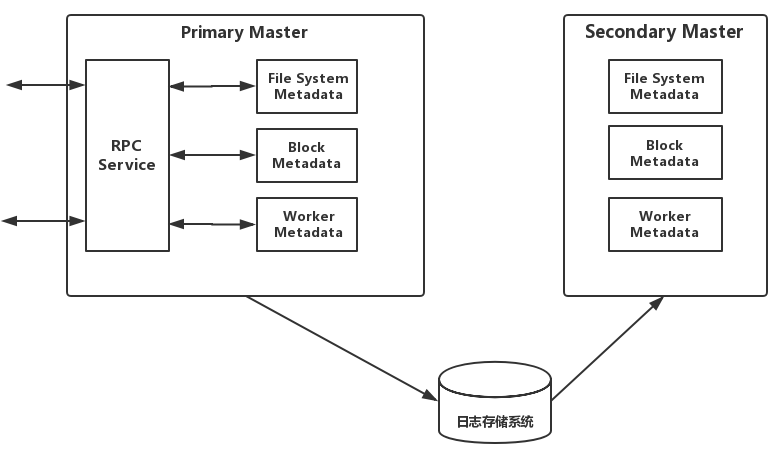
Master: 负责管理整个集群的全局元数据并响应Client对文件系统的请求。在Alluxio文件系统内部,每一个文件被划分为一个或多个数据块(block),并以数据块为单位存储在Worker中。Master节点负责管理文件系统的元数据(如文件系统的inode树、文件到数据块的映射)、数据块的元数据(如block到Worker的位置映射),以及Worker元数据(如集群当中每个Worker的状态)。所有Worker定期向Master发送心跳消息汇报自己状态,以维持参与服务的资格。Master通常不主动与其他组件通信,只通过RPC服务被动响应请求,同时Master还负责实时记录文件系统的日志(Journal),以保证集群重启之后可以准确恢复文件系统的状态。Master分为Primary Master和Secondary Master,Secondary Master需要将文件系统日志写入持久化存储,从而实现在多Master(HA模式下)间共享日志,实现Master主从切换时可以恢复Master的状态信息。Alluxio集群中可以有多个Secondary Master,每个Secondary Master定期压缩文件系统日志并生成Checkpoint以便快速恢复,并在切换成Primary Master时读取之前Primary Master写入的日志。Secondary Master不处理任何Alluxio组件的任何请求。

Worker: Alluxio Master只负责响应Client对文件系统元数据的操作,而具体文件数据传输的任务由Worker负责,如图,每个Worker负责管理分配给Alluxio的本地存储资源(如RAM,SSD,HDD),记录所有被管理的数据块的元数据,并根据Client对数据块的读写请求做出响应。Worker会把新的数据存储在本地存储,并响应未来的Client读请求,Client未命中本地资源时也可能从底层持久化存储系统中读数据并缓存至Worker本地。
Worker代替Client在持久化存储上操作数据有两个好处:1.底层读取的数据可直接存储在Worker中,可立即供其他Client使用 2.Alluxio Worker的存在让Client不依赖底层存储的连接器,更加轻量化。
Alluxio采取可配置的缓存策略,Worker空间满了的时候添加新数据块需要替换已有数据块,缓存策略来决定保留哪些数据块。
Client: 允许分析和AI/ML应用程序与Alluxio连接和交互,它发起与Master的通信,执行元数据操作,并从Worker读取和写入存储在Alluxio中的数据。它提供了Java的本机文件系统API,支持多种客户端语言包括REST,Go,Python等,而且还兼容HDFS和Amazon S3的API。
可以把Client理解为一个库,它实现了文件系统的接口,根据用户请求调用Alluxio服务,客户端被编译为alluxio-2.0.1-client.jar文件,它应当位于JVM类路径上,才能正常运行。
当Client和Worker在同一节点时,客户端对本地缓存数据的读写请求可以绕过RPC接口,使本地文件系统可以直接访问Worker所管理的数据,这种情况被称为短路写,速度比较快,如果该节点没有Worker在运行,则Client的读写需要通过网络访问其他节点上的Worker,速度受网络宽带的限制。
Alluxio读写场景与参数
- Alluxio读场景与性能分析:
- 命中本地Worker
- Client向Master检索存储该数据的Worker位置
- 如果本地存有该数据,则”短路读”,避免网络传输
- 短路读提供内存级别访问速度,是Alluxio最高读性能的方式
- 命中远程Worker
- Client请求的数据不在本地Worker则Client将从远程Worker读取数据
- 远程Worker将数据返回本地Worker并写一个本地副本,请求频繁的数据会有更多副本,从而实现热度优化计算的本地性,也可选NO_CACHE读取方式禁用本地副本写入
- 远程缓存命中,读取速度受网络速度限制
- 未命中Worker
- Alluxio任何一个Worker没有缓存所需数据,则Client把请求委托给本地Worker从底层存储系统(UFS)读取,缓存未命中的情况下延迟较高
- Alluxio 1.7前Worker从底层读取完整数据块缓存下来并返回给Client,1.7版本后支持异步缓存,Client读取,Worker缓存,不需要等待缓存完成即可返回结果
- 指定NO_CACHE读取方式则禁用本地缓存
- 命中本地Worker
- Alluxio写场景与性能分析:
- 仅写缓存
- 写入类型通过alluxio.user.file.writetype.default来设置,MUST_CACHE仅写本地缓存而不写入UFS
- 如果”短路写”可用,则直接写本地Worker避免网络传输,性能最高
- 如果无本地Worker,即”短路写”不可用,数据写入远端Worker,写速度受限于网络IO
- 数据没有持久化,机器崩溃或需要释放数据用于较新的写入时,数据可能丢失
- 同步写缓存和持久化存储
- alluxio.user.file.writetype.default=CACHE_THROUGH,同步写入Worker和UFS
- 速度比仅写缓存的方式慢很多,需要数据持久化时使用
- 仅写持久化存储
- alluxio.user.file.writetype.default=THROUGH,只将数据写入UFS,不会创建Alluxio缓存中的副本
- 输入数据重要但不立刻使用的情况下使用该方式
- 异步写持久化存储(目前2.0.1为实验性)
- alluxio.user.file.writetype.default=ASYNC_THROUGH
- 可以以内存的速度写入Alluxio Worker,并异步完成持久化
- 实验性功能-如果异步持久化到底层存储前机器崩溃,数据丢失,异步写机制要求文件所有块都在同一个Worker中
- 仅写缓存
- Alluxio读写参数总结
- 写参数: alluxio.user.file.writetype.default
- CACHE_THROUGH:数据被同步写入AlluxioWorker和底层存储
- MUST_CACHE:数据被同步写入AlluxioWorker,不写底层存储
- THROUGH:数据只写底层存储,不写入AlluxioWorker
- ASYNC_THROUGH:数据同步写入AlluxioWorker并异步写底层存储(速度快)
- 读参数: alluxio.user.file.readtype.default
- CACHE_PROMOTE:数据在Worker上,则被移动到Worker的最高层,否则创建副本到本地Worker
- CACHE:数据不在本地Worker中时直接创建副本到本地Worker
- NO_CACHE:仅读数据,不写副本到Worker
- 是否缓存全部数据块: alluxio.user.file.cache.partially.read.block (v1.7以前,V1.7以后采取异步缓存策略)
- false读多少缓存多少,一个数据块只有完全被读取时,才能被缓存
- true读部分缓存全部,没有完全读取的数据块也会被全部存到Alluxio内
- Worker写文件数据块的数据分布策略: alluxio.user.block.write.location.policy.class
- LocalFirstPolicy (alluxio.client.block.policy.LocalFirstPolicy) 默认值,首先返回本地主机,如果本地worker没有足够的块容量,它从活动worker列表中随机选择一名worker。
- MostAvailableFirstPolicy (alluxio.client.block.policy.MostAvailableFirstPolicy) 返回具有最多可用字节的worker。
- RoundRobinPolicy (alluxio.client.block.policy.RoundRobinPolicy) 以循环方式选择下一个worker,跳过没有足够容量的worker。
- SpecificHostPolicy (alluxio.client.block.policy.SpecificHostPolicy) 返回具有指定主机名的worker。此策略不能设置为默认策略。
- 目前有六种策略,详见配置项列表
Alluxio的分层存储
概念: Alluxio workers节点使用包括内存在内的本地存储来充当分布式缓冲缓存区,可以很大程度上改善I/O性能。每个Alluxio节点管理的存储数量和类型由用户配置,Alluxio还支持层次化存储,让数据存储获得类似于L1/L2 cpu缓存的优化。
单层存储设置(推荐):- 默认使用两个参数alluxio.worker.memory.size=16GB + alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk来设置Alluxio Worker的缓存大小
- 也可以单层多个存储介质并指定每个介质可用空间大小alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk,/mnt/ssd + alluxio.worker.tieredstore.level0.dirs.quota=16GB,100GB
- alluxio.worker.memory.size和alluxio.worker.tieredstore.level0.dirs.quota的区别->ramdisk的大小默认由前者决定,后者可以决定除内存外的其他介质如ssd和hdd的大小
- 写参数: alluxio.user.file.writetype.default
多层存储设置:
- 多层存储的配置-使用两层存储MEM和HDD
alluxio.worker.tieredstore.levels=2 # 最大存储级数 在Alluxio中配置了两级存储 alluxio.worker.tieredstore.level0.alias=MEM # alluxio.worker.tieredstore.level0.alias=MEM 配置了首层(顶层)是内存存储层 alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk # 设置了ramdisk的配额是100GB alluxio.worker.tieredstore.level0.dirs.quota=100GB alluxio.worker.tieredstore.level0.watermark.high.ratio=0.9 # 回收策略的高水位 alluxio.worker.tieredstore.level0.watermark.low.ratio=0.7 alluxio.worker.tieredstore.level1.alias=HDD # 配置了第二层是硬盘层 alluxio.worker.tieredstore.level1.dirs.path=/mnt/hdd1,/mnt/hdd2,/mnt/hdd3 # 定义了第二层3个文件路径各自的配额 alluxio.worker.tieredstore.level1.dirs.quota=2TB,5TB,500GB alluxio.worker.tieredstore.level1.watermark.high.ratio=0.9 alluxio.worker.tieredstore.level1.watermark.low.ratio=0.7 - 写数据默认写入顶层存储,也可以指定写数据的默认层级 alluxio.user.file.write.tier.default 默认0最顶层,1表示第二层,-1倒数第一层
- Alluxio收到写请求,直接把数据写入有足够缓存的层,如果缓存全满,则置换掉底层的一个Block.
Alluxio缓存回收策略
缓存回收: Alluxio中的数据是动态变化的,存储空间不足时会为新数据腾出空间
- 异步缓存回收与同步缓存回收
alluxio.worker.tieredstore.reserver.enabled=true (默认异步回收) 在读写缓存工作负载较高的情况下异步回收可以提升性能
alluxio.worker.tieredstore.reserver.enabled=false (同步回收) 请求所用空间比Worker上请求空间更多时,同步回收可以最大化Alluxio空间利用率,同步回收建议使用小数据块配置(64-128MB)来降低回收延迟 - 缓存回收中空间预留器的水位(阈值)
Worker存储利用率达到高水位时,基于回收策略回收Worker缓存直到达到配置的低水位
高水位: alluxio.worker.tieredstore.level0.watermark.high.ratio=0.95 (默认95%)
低水位: alluxio.worker.tieredstore.level0.watermark.low.ratio=0.7 (默认70%)
比如配置了32GB(MEM)+100GB(SSD)=132GB的Worker内存,当内存达到高水位132x0.95=125.4GB时开始回收缓存,直到到达低水位132x0.7=92.4GB时停止回收缓存 - 自定义回收策略
alluxio.worker.allocator.class=alluxio.worker.block.allocator.MaxFreeAllocator (Alluxio中新数据块分配策略的类名)
alluxio.worker.evictor.class=alluxio.worker.block.evictor.LRUEvictor (当存储层空间用尽时块回收策略的类名)
贪心回收策略: 回收任意数据块直到释放出所需空间
LRU回收策略: 回收最近最少使用数据块直到释放出所需空间
部分LRU回收策略: 在最大剩余空间的目录回收最近最少使用数据块
LRFU回收策略: 基于权重分配的最近最少使用和最不经常使用策略回收数据块,如果权重完全偏向最近最少使用,则LRFU变为LRU
Alluxio异步缓存策略
- Alluxio v1.7以后支持异步缓存
异步缓存是将Alluxio的缓存开销由客户端转移到Worker上,第一次读数据时,在不设置读属性为NO_CACHE的情况下Client只负责从底层存储读数据,然后缓存任务由Worker来执行,对Client读性能没有影响,也不需要像V1.7版本前那样设置alluxio.user.file.cache.partially.read.block来决定缓存部分或全部数据,而且Worker内部也在Client读取底层存储系统的数据方面做了优化,设置读属性为CACHE的情况下:
Client顺序读完整数据块时Worker顺便缓存完整数据块
Client只读部分数据或非顺序读数据时Worker不会读取时顺便缓存,等客户端读取完以后再向Worker系欸点发送异步缓存命令,Worker节点再从底层存储中获取完整的块
异步缓存使得第一次从Alluxio读取和直接从底层存储读取花费相同时间,且数据异步缓存到Alluxio中,提高集群整体性能 - 异步缓存参数调整
Worker在异步缓存的同时也响应Client读取请求,可通过设置Worker端的线程池大小来加快异步缓存的速度
alluxio.worker.network.netty.async.cache.manager.threads.max 指定Worker线程池大小,该属性默认为8,表示最多同时用八核从其他Worker或底层存储读数据并缓存,提高此值可以加快后台异步缓存的速度,但会增加CPU使用率
Alluxio元数据
Alluxio元数据的存储
在Alluxio新的2.x版本中,对元数据存储做了优化,使其能应对数以亿级的元数据存储。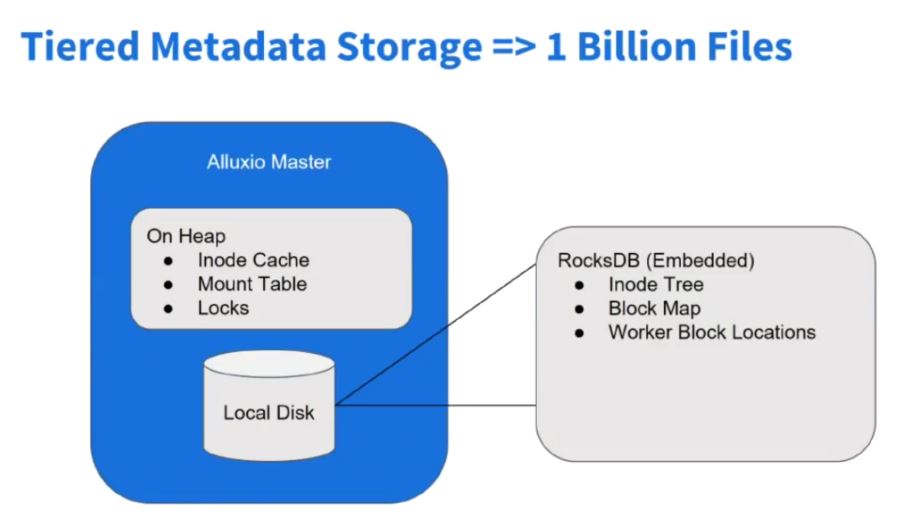
首先,文件系统是INode-Tree组成的,即文件目录树,Alluxio Master管理多个底层存储系统的元数据,每个文件目录都是INode-Tree的节点,在Java对象中,可能一个目录信息本身占用空间不大,但映射在JavaHeap内存中,算上附加信息,每个文件大概要有1KB左右的元数据,如果有十亿个文件和路径,则要有约1TB的堆内存来存储元数据,完全是不现实的。
所以,为了方便管理元数据,减小因为元数据过多对Master性能造成的影响,Alluxio的元数据通过RocksDB键值数据库来管理元数据,Master会Cache常用数据的元数据,而大部分元数据则存在RocksDB中,这样大大减小了Master Heap的压力,降低OOM可能性,使Alluxio可以同时管理多个存储系统的元数据。
通过RocksDB的行锁,也可以方便高并发的操作Alluxio元数据。
高可用过程中,INode-Tree是进程中的资源,不共享,如果ActiveMaster挂掉,StandByMaster节点可以从Journal持久日志(位于持久化存储中如HDFS)恢复状态。
这样会依赖持久存储(如HDFS)的健康状况,如果持久存储服务宕机,Journal日志也不能写,Alluxio高可用服务就会受到影响。
所以,Alluxio通过Raft算法保证元数据的完整性,即使宕机,也不会丢失已经提交的元数据。Alluxio元数据一致性
- Alluxio读取磁层存储系统的元数据,包括文件名,文件大小,创建者,组别,目录结构等
- 如果绕过Alluxio修改底层存储系统的目录结构,Alluxio会同步更新
alluxio.user.file.metadata.sync.interval=-1 Alluxio不主动同步底层存储元数据
alluxio.user.file.metadata.sync.interval=正整数 正整数指定了时间窗口,该时间窗口内不触发元数据同步
alluxio.user.file.metadata.sync.interval=0 时间窗口为0,每次读取都触发元数据同步
时间窗口越大,同步元数据频率越低,Alluxio Master性能受影响越小 - Alluxio不加载具体数据,只加载元数据,若要加载文件数据,可以通过load命令或FileStream API
- 在Alluxio中创建文件或文件夹时可以指定是否持久化
alluxio fs -Dalluxio.user.file.writetype.default=CACHE_THROUGH mkdir /xxx
alluxio fs -Dalluxio.user.file.writetype.default=CACHE_THROUGH touch /xxx/xx
Alluxio RPC
Alluxio 1.x中
Master RPC using Thrift(元数据操作)
Workers RPC using Netty(数据操作)
而新的Alluxio 2.x中
使用gRPC保证高吞吐,方便代码维护
Alluxio的Metrics
度量指标信息可以让用户深入了解集群上运行的任务,是监控和调试的宝贵资源。
Alluxio的度量指标信息被分配到各种相关Alluxio组件的实例中。每个实例中,用户可以配置一组度量指标槽,来决定报告哪些度量指标信息。现支持Master进程,Worker进程和Client进程的度量指标 。
度量指标的sink
参数为alluxio.metrics.sink.xxx
ConsoleSink: 输出控制台的度量值。
CsvSink: 每隔一段时间将度量指标信息导出到CSV文件中。
JmxSink: 查看JMX控制台中注册的度量信息。
GraphiteSink: 给Graphite服务器发送度量信息。
MetricsServlet: 添加Web UI中的servlet,作为JSON数据来为度量指标数据服务。可选度量的配置
Master的Metrics 配置方法 master.* 例如:master.CapacityTotal
常规信息
CapacityTotal: 文件系统总容量(以字节为单位)。
CapacityUsed: 文件系统中已使用的容量(以字节为单位)。
CapacityFree: 文件系统中未使用的容量(以字节为单位)。
PathsTotal: 文件系统中文件和目录的数目。
UnderFsCapacityTotal: 底层文件系统总容量(以字节为单位)。
UnderFsCapacityUsed: 底层文件系统中已使用的容量(以字节为单位)。
UnderFsCapacityFree: 底层文件系统中未使用的容量(以字节为单位)。
Workers: Worker的数目。
逻辑操作
DirectoriesCreated: 创建的目录数目。
FileBlockInfosGot: 被检索的文件块数目。
FileInfosGot: 被检索的文件数目。
FilesCompleted: 完成的文件数目。
FilesCreated: 创建的文件数目。
FilesFreed: 释放掉的文件数目。
FilesPersisted: 持久化的文件数目。
FilesPinned: 被固定的文件数目。
NewBlocksGot: 获得的新数据块数目。
PathsDeleted: 删除的文件和目录数目。
PathsMounted: 挂载的路径数目。
PathsRenamed: 重命名的文件和目录数目。
PathsUnmounted: 未被挂载的路径数目。
RPC调用
CompleteFileOps: CompleteFile操作的数目。
CreateDirectoryOps: CreateDirectory操作的数目。
CreateFileOps: CreateFile操作的数目。
DeletePathOps: DeletePath操作的数目。
FreeFileOps: FreeFile操作的数目。
GetFileBlockInfoOps: GetFileBlockInfo操作的数目。
GetFileInfoOps: GetFileInfo操作的数目。
GetNewBlockOps: GetNewBlock操作的数目。
MountOps: Mount操作的数目。
RenamePathOps: RenamePath操作的数目。
SetStateOps: SetState操作的数目。
UnmountOps: Unmount操作的数目。Worker的Metrics 配置方法 192_168_1_1.* 例如:192_168_1_1.CapacityTotal
常规信息
CapacityTotal: 该Worker的总容量(以字节为单位)。
CapacityUsed: 该Worker已使用的容量(以字节为单位)。
CapacityFree: 该Worker未使用的容量(以字节为单位)。
逻辑操作
BlocksAccessed: 访问的数据块数目。
BlocksCached: 被缓存的数据块数目。
BlocksCanceled: 被取消的数据块数目。
BlocksDeleted: 被删除的数据块数目。
BlocksEvicted: 被替换的数据块数目。
BlocksPromoted: 被提升到内存的数据块数目。
BytesReadAlluxio: 通过该worker从Alluxio存储读取的数据量,单位为byte。其中不包括UFS读。
BytesWrittenAlluxio: 通过该worker写到Alluxio存储的数据量,单位为byte。其中不包括UTF写。
BytesReadUfs-UFS:${UFS}: 通过该worker从指定UFS读取的数据量,单位为byte。
BytesWrittenUfs-UFS:${UFS}: 通过该worker写到指定UFS的数据量,单位为byte。Client的Metrics 配置方法 client.* 例如:clien.BytesReadRemote
常规信息
NettyConnectionOpen: 当前Netty网络连接的数目。
逻辑操作
BytesReadRemote: 远程读取的字节数目。
BytesWrittenRemote: 远程写入的字节数目。
BytesReadUfs: 从ufs中读取的字节数目。
BytesWrittenUfs: 写入ufs的字节数目。
配置示例
vim metrics.properties # List of available sinks and their properties. alluxio.metrics.sink.ConsoleSink alluxio.metrics.sink.CsvSink alluxio.metrics.sink.JmxSink alluxio.metrics.sink.MetricsServlet alluxio.metrics.sink.PrometheusMetricsServlet alluxio.metrics.sink.GraphiteSink master.GetFileBlockInfoOps master.GetNewBlockOps master.FreeFileOps 192_168_1_101.BytesReadAlluxio 192_168_1_101.BytesWrittenAlluxio 192_168_1_101.BlocksAccessed 192_168_1_101.BlocksCached 192_168_1_101.BlocksCanceled 192_168_1_101.BlocksDeleted 192_168_1_101.BlocksEvicted 192_168_1_101.BlocksPromoted 192_168_1_102.BytesReadAlluxio 192_168_1_102.BytesWrittenAlluxio 192_168_1_102.BlocksAccessed 192_168_1_102.BlocksCached 192_168_1_102.BlocksCanceled 192_168_1_102.BlocksDeleted 192_168_1_102.BlocksEvicted 192_168_1_102.BlocksPromoted 192_168_1_103.BytesReadAlluxio 192_168_1_103.BytesWrittenAlluxio 192_168_1_103.BlocksAccessed 192_168_1_103.BlocksCached 192_168_1_103.BlocksCanceled 192_168_1_103.BlocksDeleted 192_168_1_103.BlocksEvicted 192_168_1_103.BlocksPromoted然后访问 http://192.168.1.101:19999/metrics/json/ 可得到监控信息
喜欢看源码的小伙伴可以戳这里哟->Alluxio源码入口
Alluixo审计日志
Alluxio提供审计日志来方便管理员可以追踪用户对元数据的访问操作。
开启审计日志: 讲JVM参数alluxio.master.audit.logging.enabled设为true
审计日志包含如下条目:
| key | desc |
|---|---|
| succeeded | 如果命令成功运行,值为true。在命令成功运行前,该命令必须是被允许的。 |
| allowed | 如果命令是被允许的,值为true。即使一条命令是被允许的它也可能运行失败。 |
| ugi | 用户组信息,包括用户名,主要组,认证类型。 |
| ip | 客户端IP地址。 |
| cmd | 用户运行的命令。 |
| src | 源文件或目录地址。 |
| dst | 目标文件或目录的地址。如果不适用,值为空。 |
| perm | user:group:mask,如果不适用值为空。 |
Alluxio安装和部署
准备工作
1.下载Alluxio压缩包并上传到NN所在集群
2.解压并进入安装目录
tar -zxvf alluxio-2.0.1-bin.tar.gz -C /opt/module/
mv /opt/module/alluxio-2.0.1 /opt/module/alluxio
cd /opt/module/alluxio
cp conf/alluxio-site.properties.template conf/alluxio-site.properties
cp conf/alluxio-env.sh.template conf/alluxio-env.sh常规集群参数配置
常规非高可用集群配置,针对1.x和2.x版本通用
conf/alluxio-env.sh
vim conf/alluxio-env.sh
ALLUXIO_HOME=/opt/module/alluxio-2.0.1
ALLUXIO_LOGS_DIR=/opt/module/alluxio-2.1.0/logs
ALLUXIO_MASTER_HOSTNAME=hadoop101
ALLUXIO_RAM_FOLDER=/mnt/ramdisk
ALLUXIO_UNDERFS_ADDRESS=hdfs://hadoop101:9000/alluxio
ALLUXIO_WORKER_MEMORY_SIZE=512MB
JAVA_HOME=/opt/module/jdk1.8.0_161
# 设置ALLUXIO_MASTER_JAVA_OPTS作用于master JVM
# 设置ALLUXIO_WORKER_JAVA_OPTS作用于worker JVM
# 以及ALLUXIO_JAVA_OPTS同时作用于master以及worker JVM
# 增加worker JVM GC事件的logging, 输出写至worker节点的logs/worker.out文件中
ALLUXIO_WORKER_JAVA_OPTS=" -XX:+PrintGCDetails -XX:+PrintTenuringDistribution -XX:+PrintGCTimestamps"
# 设置master JVM的的heap size
ALLUXIO_MASTER_JAVA_OPTS=" -Xms2048M -Xmx4096M"conf/alluxio-site.properties
vim conf/alluxio-site.properties
# Common properties
alluxio.master.hostname=hadoop101
alluxio.master.mount.table.root.ufs=hdfs://192.168.1.101:9000/alluxio
alluxio.underfs.hdfs.configuration=/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml:/opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
# Worker properties
alluxio.worker.memory.size=512MB
alluxio.worker.tieredstore.levels=1
alluxio.worker.tieredstore.level0.alias=MEM
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
vim conf/masters
hadoop101
vim conf/workers
hadoop102
hadoop103
scp -r /opt/module/alluxio/ root@hadoop102:/opt/module/
scp -r /opt/module/alluxio/ root@hadoop103:/opt/module/
# 打开Alluxio服务
alluxio format
alluxio-start.sh master
alluxio-start.sh workers NoMount
或直接 alluxio-start.sh all
访问Master节点的WEB UI: hadoop101:19999
访问Worker节点的WEB UI: hadoop102:30000
#测试部署是否成功
bin/alluxio runTests # 如果出现Passed the test则说明部署成功
bin/alluxio-stop.sh all # 关闭集群出现类似以下界面即为部署成功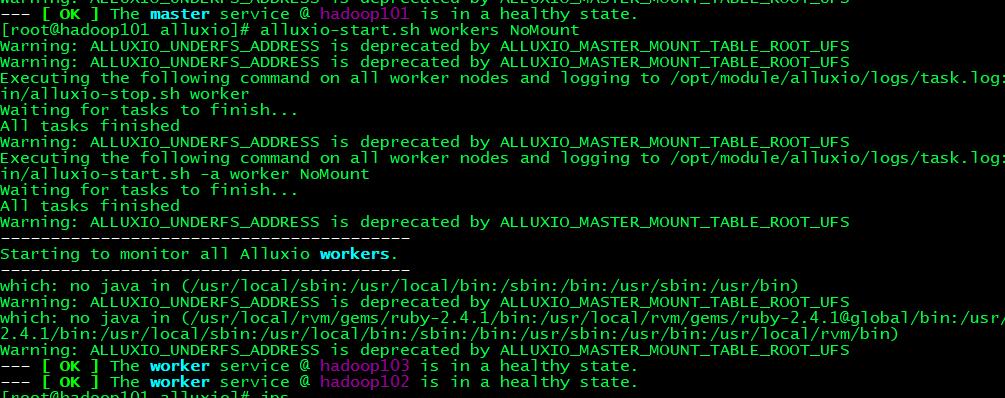
此时可以通过命令alluxio fsdamin report来查看集群状态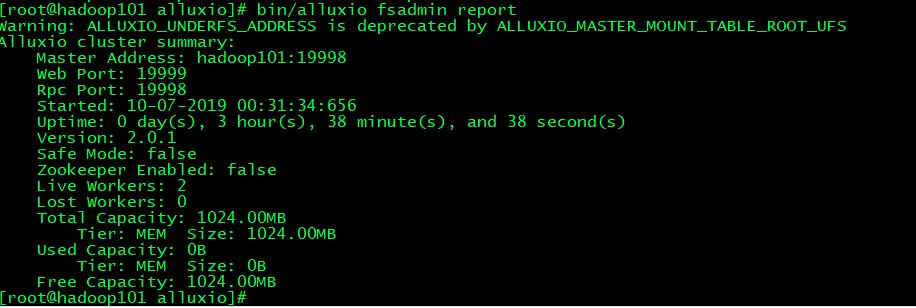
高可用集群参数配置
高可用(HA)通过支持同时运行多个master来保证服务的高可用性,多个master中有一个master被选为primary master作为所有worker和client的通信首选,其余master为备选状态(StandBy),它们通过和primary master共享日志来维护同样的文件系统元数据,并在primary master失效时迅速接替其工作(master主从切换过程中,客户端可能会出现短暂的延迟或瞬态错误)
搭建高可用集群前的准备:
①确保Zookeeper服务已经运行
②一个单独安装的可靠的共享日志存储系统(可用HDFS或S3等系统)
③这个配置针对Alluxio 2.x版本,不适用于1.x版本
④需要事先创建好ramdisk挂载目录
注意去掉中文注释 否则会报错
在所有机器上配置env.sh
vim alluxio-env.sh
ALLUXIO_HOME=/opt/alluxio
ALLUXIO_LOGS_DIR=/opt/alluxio/logs
ALLUXIO_RAM_FOLDER=/mnt/ramdisk
JAVA_HOME=/opt/module/jdk1.8.0_161
# 设置ALLUXIO_MASTER_JAVA_OPTS作用于master JVM
# 设置ALLUXIO_WORKER_JAVA_OPTS作用于worker JVM
# 以及ALLUXIO_JAVA_OPTS同时作用于master以及worker JVM
# 增加worker JVM GC事件的logging, 输出写至worker节点的logs/worker.out文件中
ALLUXIO_WORKER_JAVA_OPTS=" -XX:+PrintGCDetails -XX:+PrintTenuringDistribution -XX:+PrintGCTimestamps"
# 设置master JVM的的heap size
ALLUXIO_MASTER_JAVA_OPTS=" -Xms2048M -Xmx4096M"
在101机器上配置Master和Worker
vim alluxio-site.properties
# 192.168.1.101 Master Worker
# Common properties
alluxio.master.hostname=192.168.1.101 # 要写其他机器能识别的地址而非localhost等
alluxio.underfs.hdfs.configuration=/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml:/opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml # 如果底层HDFS存储为高可用,则要写hdfs配置文件地址
alluxio.master.mount.table.root.ufs=hdfs://hadoop101:9000/ # 指向高可用或非高可用的HDFS地址(可以是根目录,也可以是某个文件夹)
# Worker properties
alluxio.worker.memory.size=512MB
alluxio.worker.tieredstore.levels=1
alluxio.worker.tieredstore.level0.alias=MEM
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
# HA properties
alluxio.zookeeper.enabled=true
alluxio.zookeeper.address=192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181 # Zookeeper地址中间逗号隔开
alluxio.master.journal.type=UFS
alluxio.master.journal.folder=hdfs://192.168.1.101:9000/alluxio/journal # 回滚日志的地址,写入可靠的分布式HDFS
alluxio.worker.block.heartbeat.timeout.ms=300000
alluxio.zookeeper.session.timeout=120s
# User properties
alluxio.user.file.readtype.default=CACHE_PROMOTE
alluxio.user.file.writetype.default=ASYNC_THROUGH
alluxio.user.metrics.collection.enable=true
alluxio.master.metrics.time.series.interval=1000
# Security properties
alluxio.security.authorization.permission.enabled=true
alluxio.security.authentication.type=SIMPLE
alluxio.master.security.impersonation.hive.users=* # 可以模拟很多用户来实现权限控制
alluxio.master.security.impersonation.hive.groups=*
alluxio.master.security.impersonation.yarn.users=*
alluxio.master.security.impersonation.yarn.groups=*
alluxio.master.security.impersonation.hdfs.users=*
alluxio.master.security.impersonation.hdfs.groups=*
在102机器上配置Master和Worker
vim alluxio-site.properties
# 192.168.1.102 Master Worker
# Common properties
alluxio.master.hostname=192.168.1.102 # 要写其他机器能识别的地址而非localhost等
alluxio.underfs.hdfs.configuration=/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml:/opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
alluxio.master.mount.table.root.ufs=hdfs://hadoop101:9000/
# Worker properties
alluxio.worker.memory.size=512MB
alluxio.worker.tieredstore.levels=1
alluxio.worker.tieredstore.level0.alias=MEM
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
# HA properties
alluxio.zookeeper.enabled=true
alluxio.zookeeper.address=192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181
alluxio.master.journal.type=UFS
alluxio.master.journal.folder=hdfs://192.168.1.101:9000/alluxio/journal
alluxio.worker.block.heartbeat.timeout.ms=300000
alluxio.zookeeper.session.timeout=120s
# User properties
alluxio.user.file.readtype.default=CACHE_PROMOTE
alluxio.user.file.writetype.default=ASYNC_THROUGH
alluxio.user.metrics.collection.enable=true
alluxio.master.metrics.time.series.interval=1000
# Security properties
alluxio.security.authorization.permission.enabled=true
alluxio.security.authentication.type=SIMPLE
alluxio.master.security.impersonation.hive.users=*
alluxio.master.security.impersonation.hive.groups=*
alluxio.master.security.impersonation.yarn.users=*
alluxio.master.security.impersonation.yarn.groups=*
alluxio.master.security.impersonation.hdfs.users=*
alluxio.master.security.impersonation.hdfs.groups=*
在103机器上配置Worker
vim alluxio-site.properties
# 192.168.1.103 Worker
# Common properties
# Worker不需要写alluxio.master.hostname参数和alluxio.master.journal.folder参数
alluxio.underfs.hdfs.configuration=/opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml:/opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
alluxio.master.mount.table.root.ufs=hdfs://hadoop101:9000/
# Worker properties
alluxio.worker.memory.size=512MB
alluxio.worker.tieredstore.levels=1
alluxio.worker.tieredstore.level0.alias=MEM
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
# HA properties
alluxio.zookeeper.enabled=true
alluxio.zookeeper.address=192.168.1.101:2181,192.168.1.102:2181,192.168.1.103:2181
alluxio.worker.block.heartbeat.timeout.ms=300000
alluxio.zookeeper.session.timeout=120s
# User properties
alluxio.user.file.readtype.default=CACHE_PROMOTE
alluxio.user.file.writetype.default=ASYNC_THROUGH
alluxio.user.metrics.collection.enable=true
alluxio.master.metrics.time.series.interval=1000
# Security properties
alluxio.security.authorization.permission.enabled=true
alluxio.security.authentication.type=SIMPLE
alluxio.master.security.impersonation.hive.users=*
alluxio.master.security.impersonation.hive.groups=*
alluxio.master.security.impersonation.yarn.users=*
alluxio.master.security.impersonation.yarn.groups=*
alluxio.master.security.impersonation.hdfs.users=*
alluxio.master.security.impersonation.hdfs.groups=*
在所有机器上指定Master和Worker节点
vim masters
192.168.1.101
192.168.1.102
vim workers
192.168.1.101
192.168.1.102
192.168.1.103
# 测试部署是否成功
alluxio format
alluxio-start.sh all SudoMount
alluxio fsadmin report
alluxio runTests # 如果出现Passed the test则说明部署成功
# 测试高可用模式的自动故障处理: (假设此时hadoop101位primary master)
ssh hadoop101
jps | grep AlluxioMaster
kill -9 <AlluxioMaster PID>
alluxio fs leader # 显示新的primary Master(可能需要等待一小段时间选举)部署说明
- Alluxio可以像CM一样,部署在同一网络中的节点上且不需要机器间免密登陆。免密登陆只是为了方便使用start-all.sh脚本一键启动。非免密登陆的集群可以使用Ansible自动化运维工具对每个节点执行启动和挂载等操作(在每个Master上使用部署Alluxio的用户分别执行alluxio-start.sh master,然后如果使用非root用户启动Alluxio服务,则要在每个worker的root用户执行alluxio-mount.sh Mount local ,然后用部署Alluxio的用户执行alluxio-start.sh worker,并在所有节点alluxio-start.sh job_master,alluxio-start.sh job_worker即可),作用等同于start-all.sh脚本,不会对Alluxio服务的运行造成影响。
- Mount和SudoMount需要在root权限下执行,因为只有root用户有权限创建和访问RamFS,启动Alluxio的用户要有这个RamFS的读写执行权限,Alluxio的RAM FLODER(ramdisk)可以理解为是在普通HDD磁盘目录上挂载的一个RamFS文件系统,RamFS是把系统的RAM作为存储,且RamFS不会使用swap交换内存分区,Linux会把RamFS视为一个磁盘文件目录。 查看RamFS的方法: mount | grep -E “(tmpfs|ramfs)” 这里的tmpFS也是基于内存的存储系统,但它会使用到Swap分区,使读写效率降低,Alluxio也可以使用tmpFS作为缓存。 了解更多:ramfs和tmpfs的区别
- Alluxio的”/“目录权限由启动Mater和Worker的用户决定,并与UFS中对应的文件夹权限一致,可以修改Alluxio根目录权限,Alluxio创建文件和文件夹的用户和组与Linux用户合组一致,并且与持久化到HDFS的文件的用户和组一致。
- Mount|SudoMount|Umount|SudoUmount说一下这四个参数,Mount和SudoMount是挂载RamFS,后者带sudo权限,Umount和SudoUmount是卸载RamFS,后者带sudo权限。Mount和SudoMount会格式化已存在的RamFS。
- 关于用户模拟的一些理解和使用很重要参考这篇文章:User Impersonation相关配置问题分析与解决
- Alluxio部署前,要决定用哪个用户启动Alluxio,如果底层存储是HDFS,建议使用启动NameNode进程的用户来启动Alluxio Master和Workers,保证HDFS权限映射:Alluxio On HDFS
- Mount参数一般只在Worker节点使用
- 可以在HDFS建立一个777权限的文件路径作为Alluxio的底层存储
- job_master和job_worker官网没做介绍,但在当前版本这两个组件必须启动,否则会影响persist功能以及一些其他功能(我目前只知道persist会Time Out)
配置这块踩了好多坑,终于,Alluxio基本服务部署完毕,一些关于优化和细节的参数在Alluxio原理部分中涉及到,也可查阅Alluxio配置参数大全
Alluxio2.1.0版本官方介绍说使用ASYNC_THROUGH进行写入时防止数据丢失,所以我这里设置了ASYNC_THROUGH异步写磁盘,既能保证写入速度,又能将文件持久化
之前配置Alluxio高可用,一直不稳定,心跳中断,Master和Worker掉线问题频发,Alluxio2.1版本官方说修复了各种心跳中断问题,当然Alluxio的高可用要求底层的Journal日志存储系统的稳定性很高,如果底层Journal存储系统不稳定(比如HDFS No More Good DataNode的情况),就会导致Master崩溃。
Alluxio常用命令
Alluxio命令速查表包括缓存载入,驻留,释放,数据生存时间等重要命令
Alluxio常用Shell命令速查表:
#文件基本操作
可以在执行命令时指定参数 方法: alluxio fs -D...指定参数 copyFromLocal ....
alluxio fs cat <path/file> # 打开文件
alluxio fs ls [-d|-f|-p|-R|-h|--sort=option|-r] <path> #查看目录
alluxio fs copyFromLocal [--thread <num>] [--buffersize <bytes>] <src> <remoteDst> # 从本地上传文件到Alluxio
alluxio fs copyToLocal [--buffersize <bytes>] <src> <localDst> #从Alluxio载文件到本地
alluxio fs count <path> # 统计Alluxio目录的文件数,文件夹数和总大小
alluxio fs du [-h|-s|--memory] <path> # 文件大小
alluxio fs cp [-R] [--buffersize <bytes>] <src> <dst> #复制文件
alluxio fs mv <src> <dst> # 移动文件
alluxio fs rm [-R] [-U] [--alluxioOnly] <path> # 删除文件
alluxio fs mkdir <path1> [path2] ... [pathn] # 创建文件夹
alluxio fs touch <path> #创建一个空文件
alluxio fs setTtl [--action delete|free] <path> <time to live> # 设置一个文件的TTL时间
alluxio fs unsetTtl <path> # 删除文件的TTL值
alluxio fs checksum <Alluxio path> # 得到文件的MD5值
alluxio fs stat <path> # 显示文件路径信息
alluxio fs tail <path> # 显示文件最后1KB的内容
alluxio fs location <path> # 输出包含某个文件数据的主机,使用location命令可以调试数据局部性
alluxio fs help <command> # 查看命令介绍和用法
alluxio fs distributedMv <src> <dst> # 并行移动文件或目录
alluxio fs distributedCp <src> <dst> # 并行复制文件或目录
alluxio fs distributedLoad [--replication <num>] <path> # 在alluxio空间中加载文件或目录,使其驻留在内存中
#与底层存储的交互操作
alluxio fs load [--local] <path> # load命令可为数据分析编排数据,加快数据分析的效率,load命令将底层文件系统中的数据载入到Alluxio中,如果运行该命令的机器上正在运行一个Alluxio worker,那么数据将移动到该worker上,否则数据会被随机移动到一个worker上。 如果该文件已经存在在Alluxio中,设置了--local选项,并且有本地worker,则数据将移动到该worker上。否则该命令不进行任何操作。如果该命令的目标是一个文件夹,那么其子文件和子文件夹会被递归载入。
alluxio fs persist [-p|--parallelism <#>] [-t|--timeout <milliseconds>] [-w|--wait <milliseconds>] <path> [<path> ...] # 持久化Alluxio中的数据到底层存储
alluxio fs checkConsistency [-r] [-t|--threads <threads>] <Alluxio path> # 检查Alluxio与底层存储系统的元数据一致性(确定文件在底层存储还是在under storage system.)
alluxio fs free -f <> # 已经持久化到底层存储,但内存中还保留着的文件可以通过free从内存中释放,未被持久化的文件不能被free
alluxio fs mount [--readonly] [--shared] [--option <key=val>] <alluxioPath> <ufsURI>] # 将底层文件系统的"ufsURI"路径挂载到Alluxio命名空间中的"alluxioPath"路径下,"path"路径事先不能存在并由该命令生成。 没有任何数据或者元数据从底层文件系统加载。当挂载完成后,对该挂载路径下的操作会同时作用于底层文件系统的挂载点。monut命令可以挂载linux服务器上的某个文件夹alluxio fs mount /demo file:///tmp/alluxio-demo
alluxio fs unmount <alluxioPath> # 取消挂载
alluxio fs updateMount [--readonly] [--shared] [--option <key=val>] <alluxioPath> # 保留元数据的同时更改挂载点设置
alluxio fs pin <path> media1 media2 media3 ... 如果管理员对作业运行流程十分清楚,那么可以使用pin命令手动提高性能。pin命令对Alluxio中的文件或文件夹进行标记。该命令只针对元数据进行操作,不会导致任何数据被加载到Alluxio中。如果一个文件在Alluxio中被标记了,该文件的任何数据块都不会从Alluxio worker中被剔除。如果存在过多的被锁定的文件,Alluxio worker将会剩余少量存储空间,从而导致无法对其他文件进行缓存。
alluxio fs unpin <path> # 将Alluxio中的文件或文件夹解除标记。该命令仅作用于元数据,不会剔除或者删除任何数据块。一旦文件被解除锁定,Alluxio worker可以剔除该文件的数据块。
alluxio fs startSync <path> # 启动指定路径的自动同步进程
alluxio fs stopSync <path> # 关闭指定路径的自动同步进程
alluxio fs setReplication [-R] [--max <num> | --min <num>] <path> # 设置给定路径或文件的最大/最小副本数 (-1表示不限制最大副本数) -R递归
#权限相关操作及管理员命令
alluxio fs chgrp [-R] <group> <path> # 换组
alluxio fs chmod [-R] <mode> <path> # 更改读写执行等权限
alluxio fs chown [-R] <owner>[:<group>] <path> # 所有者
alluxio fsadmin backup [directory] [--local] # 备份Alluxio的元数据到备份目录(默认目录由alluxio.master.backup.directory决定)
alluxio fsadmin doctor [category] # 显示错误和警告
alluxio fsadmin report [category] [category args] # 报告运行集群的信息
alluxio fsadmin ufs --mode <noAccess/readOnly/readWrite> "ufsPath" # 更新挂载的底层存储系统的属性
alluxio formatMaster 初始化Master元数据
alluxio formatWorker 初始化Worker数据,Worker数据会被清空
alluxio getConf [key] 查看各个组件的参数和配置 key:[--master / --source]
alluxio runJournalCrashTest 测试Alluxio 高可用日志系统(会停止服务一段时间)
alluxio runUfsTests --path <ufs path>
alluxio validateConf 使修改的配置生效
alluxio validateEnv <args> 使运行环境生效
alluxio copyDir <PATH> 类似于xsync脚本,可以向各个节点分发文件
#集群相关信息
alluxio fs masterInfo # 获得master节点的信息
alluxio fs leader # 打印当前Alluxio的leader master节点主机名。
alluxio fs getCapacityBytes # 获取Alluxio总容量
alluxio fs getSyncPathList # 获取同步路径列表
alluxio fs getUsedBytes # 获取已用空间大小
alluxio fs getfacl <path> # 显示访问控制列表(ACLs)
alluxio fs setfacl [-d] [-R] [--set | -m | -x <acl_entries> <path>] | [-b | -k <path>] # 设置访问控制列表(ACLs)上面的命令不能帮到你? 那就戳这里:
Alluxio命令使用示例
管理员命令使用示例
Alluxio WEB UI介绍及使用
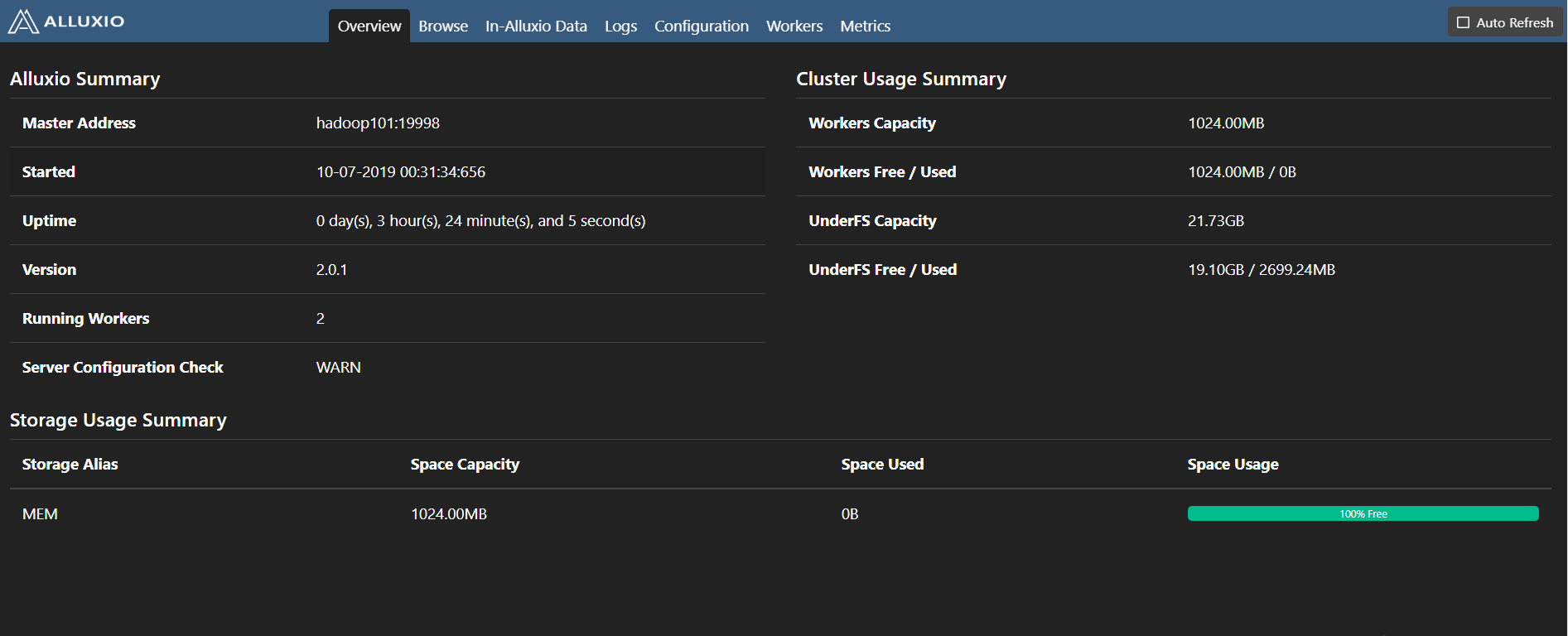
Alluxio master提供了Web界面以便用户管理
Alluxio master Web界面的默认端口是19999:访问 http://MASTER IP:19999 即可查看
Alluxio worker Web界面的默认端口是30000:访问 http://WORKER IP:30000 即可查看
WEB UI官方介绍很明确->戳这里:Alluxio Web UI
Alluxio与计算框架整合
Alluxio+Hive
频繁使用的表存在Alluxio上,可通过内存读文件获得更高的吞吐量和更低的延迟
准备工作:
cd /opt/module/hive vim conf/hive-env.sh export HADOOP_HOME=/opt/module/hadoop-2.7.2 # 添加 export HIVE_AUX_JARS_PATH=$ALLUXIO_HOME/client:$HIVE_AUX_JARS_PATH四种情况:
创建一个Hive表并指定其存储在Alluxio
bin/hive create table alluxio_test( id int, name string, color string ) row format delimited fields terminated by '\t' LOCATION "alluxio://hadoop101:19998/user/hive/warehouse/alluxio_test"; # 查看表位置 describe extended alluxio_test;
已存在HDFS的内部表
bin/hive describe extended table_name; # 查看Hive表存储位置 alter table table_name set location "alluxio://hadoop101:19998/user/hive/warehouse/table_name" describe extended table_name; msck repair table table_name; # 确定alluxio对应位置存在表数据后修复Hive表元数据第一次访问alluxio中的文件默认会被认为访问hdfs的文件,一旦数据被缓存在Alluxio中,之后的查询数据都会从Alluxio读取。
已存在HDFS的外部表
bin/hive describe extended table_name; # 将表数据改为Alluxio存储 alter table table_name set location "alluxio://hadoop101:19998/user/hive/warehouse/table_name" describe extended table_name; # 还原表数据到HDFS alter table table_name set location "hdfs://hadoop101:9000/user/hive/warehouse/table_name" describe extended table_name;Hive使用Alluxio作为默认存储系统
vim conf/hive-site.xml # 添加以下属性 <property> <name>fs.defaultFS</name> <value>alluxio://hadoop101:19998</value> <description>Hive Use Alluxio As Default FileSystem</description> </property> # 对Hive指定的Alluxio配置属性,将它们添加到每个结点的Hadoop配置目录下core-site.xml中。例如,将alluxio.user.file.writetype.default 属性由默认的MUST_CACHE修改成CACHE_THROUGH: <property> <name>alluxio.user.file.writetype.default</name> <value>CACHE_THROUGH</value> </property> # Alluxio中为Hive创建目录 alluxio fs mkdir /tmp alluxio fs mkdir /user/hive/warehouse alluxio fs chmod 775 /tmp alluxio fs chmod 775 /user/hive/warehouse # 检查Hive与Alluxio的集成情况 integration/checker/bin/alluxio-checker.sh -h # 查看该命令帮助 integration/checker/bin/alluxio-checker.sh hive -hiveurl [HIVE_URL]注:CM集群设置Hive连接Alluxio Client的方式:

排坑:
安全认证问题:


alluxio-site.properties中添加要模拟的用户:alluxio.master.security.impersonation.hive.users=* alluxio.master.security.impersonation.hive.groups=* alluxio.master.security.impersonation.yarn.users=* alluxio.master.security.impersonation.yarn.groups=*
Alluxio+Spark
Spark可以在进行简单配置后直接使用Alluxio作为数据访问层,Spark应用程序可以通过Alluxio透明地访问许多不同类型的持久化存储服务(例如,AWS S3 bucket、Azure Object Store buckets、远程部署的 HDFS 等)的数据,也可以透明地访问同一类型持久化存储服务不同实例中的数据。为了加快I/O性能,用户可以主动获取数据到Alluxio中或将数据透明地缓存到Alluxio中,尤其是在Spark部署位置与数据相距较远时特别有效。此外,通过将计算和物理存储解耦,Alluxio 能够有助于简化系统架构。当底层持久化存储中真实数据的路径对 Spark 隐藏时,对底层存储的更改可以独立于应用程序逻辑;同时Alluxio作为邻近计算的缓存,仍然可以给计算框架提供类似 Spark 数据本地性的特性。
- 配置
参数配置(spark-defaults.conf中添加)
spark.driver.extraClassPath //client/alluxio-2.0.1-client.jar
spark.executor.extraClassPath //client/alluxio-2.0.1-client.jar
或者Jar包拷贝
cp client/alluxio-2.0.1-client.jar $SPARK_HOME/jars/
如果高可用的Alluxio,还需在spark-default中指定:
自定义Spark作业中Alluxio的属性:spark.driver.extraJavaOptions -Dalluxio.zookeeper.address=zkHost1:2181,zkHost2:2181,zkHost3:2181 -Dalluxio.zookeeper.enabled=true spark.executor.extraJavaOptions -Dalluxio.zookeeper.address=zkHost1:2181,zkHost2:2181,zkHost3:2181 -Dalluxio.zookeeper.enabled=true 或者配置Hadoop文件core-site.xml如下 <configuration> <property> <name>alluxio.zookeeper.enabled</name> <value>true</value> </property> <property> <name>alluxio.zookeeper.address</name> <value>zkHost1:2181,zkHost2:2181,zkHost3:2181</value> </property> </configuration>
spark-submit…. –driver-java-options “-Dalluxio.user.file.writetype.default=CACHE_THROUGH” 而不是–conf
val s = sc.textFile("alluxio://192.168.1.101:19998/LICENSE")
val double = s.map(line => line + line)
double.saveAsTextFile("alluxio://192.168.1.101:19998/out")
df = spark.table("select ...")
df.format.parquet("alluxio://xxxxx")检查配置是否正确
在$ALLUXIO_HOME运行 integration/checker/bin/alluxio-checker.sh spark spark://sparkMaster:7077使用
存储 RDD 到 Alluxio 内存中就是将 RDD 作为文件保存到 Alluxio 中: saveAsTextFile:将 RDD 作为文本文件写入,其中每个元素都是文件中的一行 saveAsObjectFile:通过对每个元素使用 Java 序列化,将 RDD 写到一个文件中 // as text file rdd.saveAsTextFile("alluxio://localhost:19998/rdd1") rdd = sc.textFile("alluxio://localhost:19998/rdd1") // as object file rdd.saveAsObjectFile("alluxio://localhost:19998/rdd2") rdd = sc.objectFile("alluxio://localhost:19998/rdd2") 缓存 Dataframe 到 Alluxio 中(将 DataFrame 作为文件保存到 Alluxio 中): df.write.parquet("alluxio://localhost:19998/data.parquet") df = sqlContext.read.parquet("alluxio://localhost:19998/data.parquet")Alluxio对Shuffle的提升
目前三种方案:
一是基于Alluxio-Fuse客户端,无需修改源码,直接挂载Shuffle目录,但Alluxio-Fuse目前的性能不是很好
二是重写Spark Shuffle Service底层源码实现基于Alluxio Client的Shuffle
三是可以Splash Shuffle Manager插件,我的另一篇文章有讲到 -> QCon总结-Splash Shuffle Manager
当然也可以选择等Spark3.0的Remote Shuffle Service
Alluxio+HadoopMR
运行HadoopMR程序:
bin/hadoop jar ../libexec/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount -Dalluxio.user.file.writetype.default=CACHE_THROUGH -libjars /opt/module/alluxio/client/alluxio-2.0.1-client.jar \<INPUT FILES> <OUTPUT DIRECTORY>Alluxio+Presto
后续更新…
性能测试
使用官方提供的沙箱
申请官方测试沙箱Sandbox:**ALLUXIO SANDBOX**
申请成功后,按照邮件的指引操作,注意,bin/sandbox setup &的过程中千万不要Ctrl+C中止,部署完成状态如下图:
运行基准测试(TPC-DS),耐心等待后的测试结果:
已安装TPC-DS基准套件,用于运行性能测试。Spark已安装为TPC-DS用来将其作业发送到的计算框架。TPC-DS的比例因子为100,这与26GB的数据集大小相关。由索引单独标识的基准按不同的使用方案分组,并且将结果报告为每个方案的汇总。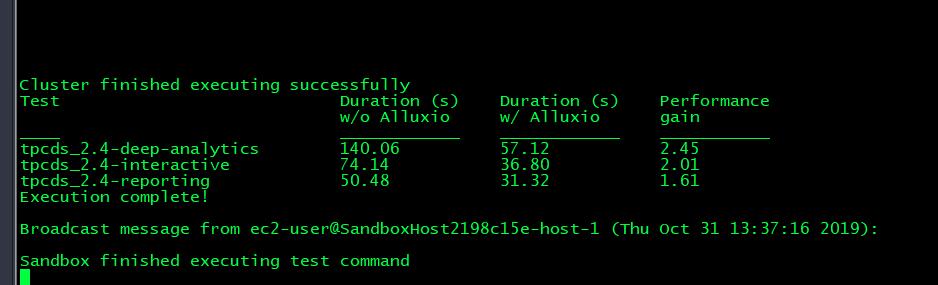
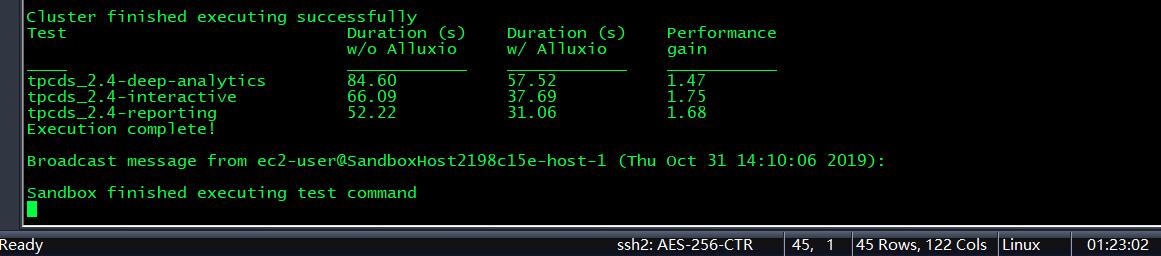
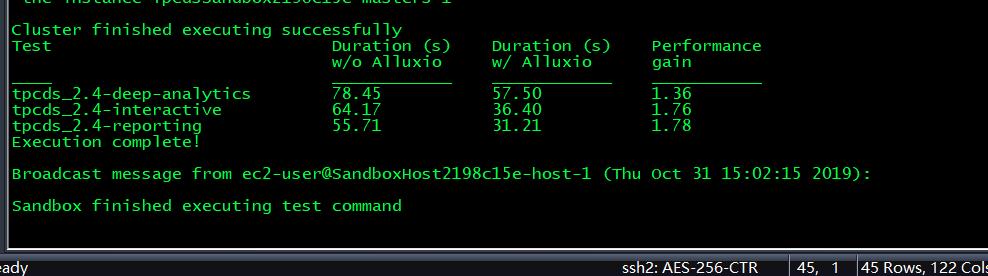
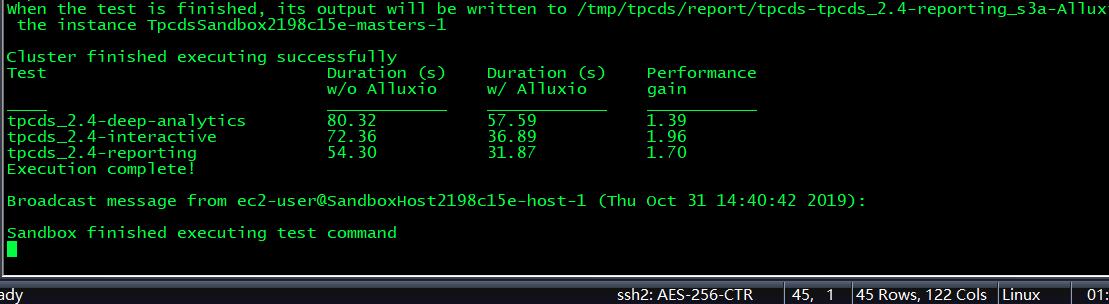
其中 w/o是without,即只是用S3为直接底层存储的情况;w/是with,即使用了Alluxio作为中间件下的性能
从图中测试结果可以看出,当计算数据存储在公有云虚拟机实例中时,Alluxio作为存储与计算框架的中间件,能够有1.5-3倍左右的性能提升
受到各方面限制,以上测试结果并非Alluxio的最佳预期。其他人的试过程
自测
Spark Sql做测试时候多次重复作业输入数据位于OS的高速缓冲区,Alluxio没有加速效果甚至变慢
我的测试环境是三台机器,每台101GB内存,16核,同台机器部署CM Hadoop,Spark,Hive,AlluxioWorker,AlluxioClient
Alluxio读参数CACHE_PROMOTE,写参数CACHE_THROUGH
| 测试方法 | 测试操作 | 运行时间(HDFS) | 运行时间(Alluxio) | 表结构 |
|---|---|---|---|---|
| SparkSQL | select count(1) from table; | 4s | 6s | 13.5GB 17字段 |
| SparkSQL | select count(1) from table; | 5s | 6s | 13.5GB 17字段 |
| SparkSQL | select count(1) from table; | 6s | 8s | 13.5GB 17字段 |
| SparkSQL | select first(ip),first(language),first(operation_channel),first(imei) from table group by product_name; | 80s | 80s | 13.5GB 17字段 |
| SparkSQL | select first(ip),first(language),first(operation_channel),first(imei) from table group by product_name; | 77s | 52s | 13.5GB 17字段 |
| SparkSQL | select first(ip),first(language),first(operation_channel),first(imei) from table group by product_name; | 60s | 73s | 13.5GB 17字段 |
| SparkSQL | select count(1) from test.table group by language; | 11.5s | 11.5s | 13.5GB 17字段 |
| Spark Persist | df.write.parquet(Path) | 3.0min | 4.0min | 13.5GB 17字段 |
| Spark Persist | spark.read.parquet(Path).count() | 4s | 5s | 13.5GB 17字段 |
| Spark Persist | spark.read.parquet(Path).count() | 6s | 6s | 13.5GB 17字段 |
后来又做了Spark Dataframe的Persist到MEMORY_ONLY和Persist到Alluxio,效果也不是很好,究其原因,我认为是我的HDFS DataNode已经和计算框架Spark部署在一起了,而且磁盘IO没有瓶颈,所以这不符合Alluxio的应用场景,从而没有令人满意的效果.
至于HDFS更快的原因,我想是Spark要读取的数据很可能已经存在OS的高速缓冲区
Alluxio还是要用对场景才行.
Alluxio FUSE
什么是Alluxio FUSE
Alluxio-FUSE可以在一台Unix机器上的本地文件系统中挂载一个Alluxio分布式文件系统。通过使用该特性,一些标准的命令行工具(例如ls、 cat以及echo)可以直接访问Alluxio分布式文件系统中的数据。此外更重要的是用不同语言实现的应用程序如C, C++, Python, Ruby, Perl, Java都可以通过标准的POSIX接口(例如open, write, read)来读写Alluxio,而不需要任何Alluxio的客户端整合与设置。
Alluxio FUSE局限性
- 文件只能顺序地一次写入,不能修改和覆盖,如果要修改就要删除原文件再创建
- 不支持soft-link和hard-link(即ln)
- alluxio.security.group.mapping.class选项设置为ShellBasedUnixGroupsMapping的值时,用户与分组信息才与Unix系统的用户分组对应
- 与直接使用Alluxio客户端相比,使用挂载文件系统的性能会相对较差
Alluxio FUSE使用
- 挂载
挂载alluxio_path到本地mount_point,mount_point必须是本地文件系统中的一个空文件夹,并且启动Alluxio-FUSE进程的用户拥有该挂载点及对其的读写权限。可以多次调用该命令来将Alluxio挂载到不同的本地目录下。所有的Alluxio-FUSE会共享$ALLUXIO_HOME\logs\fuse.log这个日志文件。integration/fuse/bin/alluxio-fuse mount mount_point [alluxio_path] - 卸载
integration/fuse/bin/alluxio-fuse umount mount_point - 检查挂载点运行信息
integration/fuse/bin/alluxio-fuse stat - 注意事项
要使用启动master和worker的用户来挂载fuse,比如使用hdfs用户启动的Alluxio,则要用hdfs来挂载,可以正常使用,如果使用root用户挂载,目录信息会乱码且无法正常使用。hdfs用户下成功mount后,切换到root用户也会看到挂载点信息乱码。Alluxio相关服务未启动,挂载点信息也会乱码。
Alluxio默认只能写本地worker,如果明确知道要写入的文件大小的范围,可以使用ASYNC_THROUGH并加大worker的缓存大小,或者配置多级缓存使worker的缓存空间大于写入文件的大小,才能防止被置换,从而提高效率
如果不确定写的文件大小的范围,就不要使用ASYNC_THROUGH这个参数,因为如果本地Worker缓存空间不够就会写入失败,这时,为了保险起见可以使用写参数CACHE_THROUGH边缓存边写或写参数THROUGH只写底层存储,来防止写入文件失败。
当然,还有一种比较好的方案,写参数设为ASYNC_THROUGH配合更大的Worker缓存来提高效率,同时设置alluxio.user.file.write.location.policy.class=alluxio.client.file.policy.RoundRobinPolicy参数来保证写入不会失败。如果只写一次,可以及时free掉无用的缓存,减少后面写数据时发生的缓存置换。
Alluxio 客户端API
Java API
Alluxio提供了两种不同的文件系统API:Alluxio API和与Hadoop兼容的API,Alluxio API提供了更多功能,而Hadoop兼容API为用户提供了使用Alluxio的灵活性,无需修改使用Hadoop API编写的现有代码.
Maven项目依赖设置 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.my.alluxio</groupId>
<artifactId>AlluxioTest</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- alluxio-fs -->
<dependency>
<groupId>org.alluxio</groupId>
<artifactId>alluxio-core-client-fs</artifactId>
<version>2.0.1</version>
</dependency>
<!-- hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>7</source>
<target>7</target>
</configuration>
</plugin>
<!-- 打jar插件 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<!--Jar包运行时的主类-->
<mainClass>IOTestUtil</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Java读写文件API
import alluxio.AlluxioURI;
import alluxio.client.file.FileInStream;
import alluxio.client.file.FileOutStream;
import alluxio.exception.AlluxioException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
/**
* HDFS & Allxuio IO读取文件测试工具 IO接口 文件API
*/
public class IOTestUtil {
public static void main(String[] args) throws IOException, AlluxioException {
String filePath = args[0];
HDFSUtil h = new HDFSUtil("hdfs://192.168.1.101:8020");
h.readFile(filePath);
AlluxioUtil a = new AlluxioUtil();
a.readFile(filePath);
System.out.println("读文件测试 Finished");
System.out.println("------------------------");
if (args.length != 1){
String fileToWritePath = args[1];
a.writeFile(fileToWritePath);
System.out.println("写文件测试 Finished");
}
}
}
class HDFSUtil{
private Configuration conf = new Configuration();
public HDFSUtil(String HDFSURL){
conf.set("fs.defaultFS",HDFSURL);
System.setProperty("HADOOP_USER_NAME","hdfs");
}
public void readFile(String path) throws IOException {
FileSystem fs = FileSystem.get(conf);
fs.getFileStatus(new Path(path));
FSDataInputStream in = fs.open(new Path(path));
try{
long hdfsStartTime=System.currentTimeMillis();
in = fs.open(new Path(path));
byte[] buffer = new byte[1024];
int byteRead = 0;
while ((byteRead = in.read(buffer)) != -1) {
System.out.write(buffer, 0, byteRead); //输出字符流
}
long hdfsEndTime=System.currentTimeMillis();
System.out.println("HDFS读取运行时间:"+(hdfsEndTime-hdfsStartTime)+" ms");
}catch (Exception e){
e.printStackTrace();
} finally {
in.close();
}
}
}
class AlluxioUtil{
private static final alluxio.client.file.FileSystem fs = alluxio.client.file.FileSystem.Factory.get();
public AlluxioUtil(){}
public FileInStream readFile(String AlluxioPath) throws IOException, AlluxioException {
AlluxioURI path = new AlluxioURI(AlluxioPath); //封装Alluxio 文件路径的path
FileInStream in = fs.openFile(path);
try{
long startTime=System.currentTimeMillis();
in = fs.openFile(path);
// 调用文件输入流FileInStream实例的read()方法读数据
byte[] buffer = new byte[1024];
int byteRead = 0;
// 读入多个字节到字节数组中,byteRead为一次读入的字节数
while ((byteRead = in.read(buffer)) != -1) {
System.out.write(buffer, 0, byteRead); //输出字符流
}
long endTime=System.currentTimeMillis();
System.out.println("Alluxio读取运行时间:"+(endTime-startTime)+" ms");
}catch (IOException | AlluxioException e){
e.printStackTrace();
}finally {
in.close();
}
in.close(); //关闭文件并释放锁
return in;
}
public void writeFile(String AlluxioPath) throws IOException, AlluxioException {
AlluxioURI path = new AlluxioURI(AlluxioPath); // 文件夹路径
FileOutStream out = null;
try {
out = fs.createFile(path); //创建文件并得到文件输入流
out.write("qjj1234567".getBytes()); // 调用文件输出流FileOutStream实例的write()方法写入数据
}catch (IOException | AlluxioException e){
e.printStackTrace();
}finally {
out.close(); // 关闭和释放文件
}
}
}Python API
Alluxio的Python库基于REST API实现的
CentOS6和Windows的环境下安装alluxio的python库失败,最终在CentOS7 Python2.7.5的环境下成功执行了**pip install alluxio**
if __name__ == '__main__':
print("后续用到API再更新")
passQ&A
- 加速不明显?
Alluxio通过使用分布式的内存存储以及分层存储,和时间或空间的本地化来实现性能加速。如果数据集没有任何本地化, 性能加速效果并不明显。 - 速度反而更慢了?
测试时尽量多观察集群的CPU占用率,Yarn内存分配和网络IO等多种因素,可能瓶颈不在读取数据的IO上。
确保要读取的数据缓存在Alluxio中,才能加速加速数据的读取。
一定要明确应用场景,Alluxio的设计主要是针对计算与存储分离的场景。在数据远端读取且网络延迟和吞吐量存在瓶颈的情况下,Alluxio的加速效果会很明显,但如果HDFS和Spark等计算框架已经共存在一台机器(计算和存储未分离),Alluxio的加速效果并不明显,甚至可能出现更慢的情况。
多次重复作业输入数据位于OS的高速缓冲区,Alluxio没有加速效果甚至变慢。 - 内存爆炸,副本过多内存占用过大?
两种方案:关闭被动缓存alluxio.user.file.passive.cache.enabled=false关闭被动缓存对于不需要数据本地性但希望更大的Alluxio存储容量的工作负载是有益的,或者通过命令alluxio fs setReplication -R –max 5限制某个目录的文件最大副本数 - 一些官方的Q&A
Alluxio官方问题与答案
总结
- 对新技术的调研,最重要的是了解它的应用场景,只有场景对了,效果才会很明显
- 一定要多看官方文档,虽然Alluxio文档不是很详细,但也有帮助,要自己找细节
- 对自己遇到的难以解决的问题要积极与社区沟通和讨论
- 自己遇到的问题可能别人也遇到了,有可能是版本的BUG,或许已经有人提交Issue了,一定多留意
- 新的稳定版发行,一定要了解它的新特性以及修复了哪些漏洞



