







Presto-高效SQL交互式查询引擎
Presto简介
Presto是Facebook开源的分布式SQL查询引擎,适用于交互式分析查询的场景(OLAP),响应时间在小于 1 秒到几分钟的场景,数据量支持GB到PB字节。类似的工具有Impala、ClickHouse等…
Presto优缺点
优点:
- 架构清晰,可不依赖任何外部系统独立运行。
- Presto自身提供了对集群的监控。
- 基于纯内存计算,不需要写磁盘,效率高
- 自身更加轻量级资源调度,线程级别的Task,效率高
- 轮询查询结果并立刻返回结果,效率高
- 解耦数据源,统一查询入口,支持多个数据源不同表的联邦查询分析
- MPP架构的优势-扩展性,节点独立,无锁资源竞争,无IO冲突,无共享数据
- 简单的数据结构,列式存储,逻辑行,大部分数据都可以轻易的转化成Presto所需要的这种数据结构。
- 丰富的接口,可完美对接外部存储系统,以及添加自定义的函数。
缺点:
- 无容错能力,无重试机制
- 不支持数据类型隐式转换
- 与Hive相比存在不小的语法差异、函数和UDF差异以及运算结果差异(如1/2在Hive结果为0.5在Presto结果为0)
- Hive views are not supported.需要创建Presto视图
- 因为纯内存计算,不适合多个大表Join(聚合操作边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高;但关联操作可能产生大量临时数据,可能比Hive慢)
- Coordinator单点问题(常见方案:ip漂移、Nginx代理动态获取等)
Presto原理
在学习Presto原理前推荐先看看我之前关于Impala的文章:《Impala-基于内存的高效SQL交互查询引擎》
Presto架构和进程
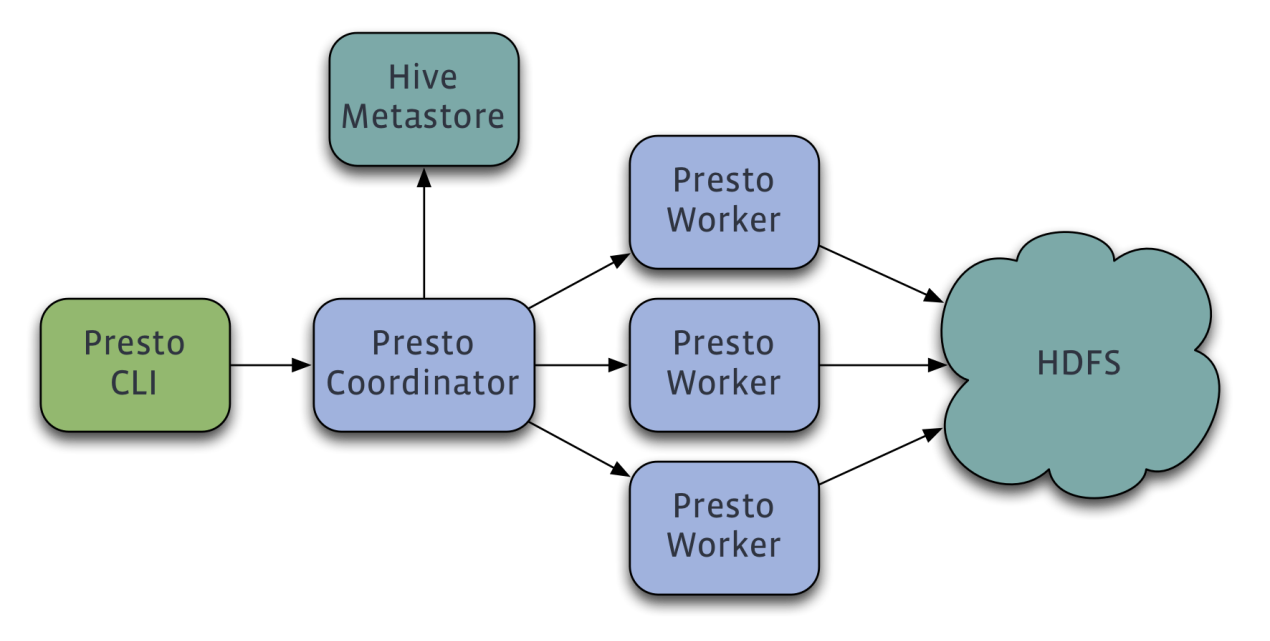
Presto与Impala的架构极其相似,都是采用Master-Slave模型以及MPP架构,而且Presto的工作角色也与ImpalaDaemon的角色基本相同,Presto有三种工作角色:Coordinator,Worker和DiscoveryServer:
- Coordinator:即Master,负责管理Meta元数据,Worker节点,SQL的解析和调度,生成Stage和Task分发给Workers,负责合并结果集并返回给客户端。相当于结合了Impalad的Coordinator角色和Planner角色的功能,区别是每个Impalad节点都可以是Coordinator,而Presto只能有一个Coordinator,多个协调者进程会导致脑裂,查询任务会死锁。
- Worker:负责计算和读写数据。相当于Impalad的Executor角色的功能。
- DiscoveryServer:通常内嵌于Coordinator节点,也可以独立出来部署,功能类似ZK,类似Impala中的ImpalaStateStore,用于监控节点心跳,一般DS和Coordinator在同一节点。Worker启动会向DS进程注册,Coordinator可以从DS获取到所有正常提供服务的Worker。
Coordinator 与 Worker、Client 通信是通过 REST API。
Presto数据模型
Presto使用Catalog、Schema和Table这3层结构来管理数据: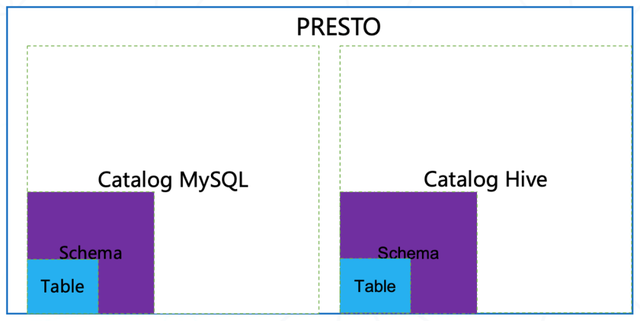
- Catalog:每个数据源都有一个名字,一个Catalog可包含多个Schema。通过show catalogs命令查看Presto已连接的所有数据源
- Schema:相当于一个数据库实例,一个Schema(数据库)中有多个Table表,通过show schemas from hive命令查看hive数据源所有库
- Table:相当于一张表,通过show tables from catalog_name.schema_name来查看库下有哪些表。定位一张表:数据源的类别.数据库.数据表
Presto有两种存储单元:Page和Block
- Page:多行数据的集合,包含多个列的数据,这里的多行数据是逻辑行,实际是以列式存储。
- Block:一列数据,根据不同类型的数据,通常采取不同的编码方式。(Kudu也有类似的思想)
- array类型的Block:应用于固定长度的类型如int、long、double,由两部分组成
- boolean valueIsNull[]表示每一行是否有值。
- T values[] 每一行的具体值。
- 可变长度的Block:String类型,由三部分组成:
- Slice:所有行数据拼接起来的字符串
- int offsets[]:每行数据的起始偏移位置(每一行的长度等于下一行的起始偏移量减去当前行的起始偏移量)
- boolean valueIsNull[]:是否空值,如果无值,偏移量与上一行相等
- 固定长度的string类型的block:所有行的数据拼接成一长串Slice,每一行的长度固定
- 字典类型的Block:可以嵌套任意类型的Block,由两部分组成:
- 字典
- int ids[] 数据的编号,查找时先找到id,再从字典中拿到真实值
- array类型的Block:应用于固定长度的类型如int、long、double,由两部分组成
Presto插件
了解了Presto的数据模型后,就可以利用插件来对接自己的系统。Presto提供了一套Connector接口,支持从自定义存储中读取元数据,以及列式存储数据。
- ConnectorMetadata:管理表的元数据,表的元数据,partition等信息。在处理请求时,需要获取元信息,以便确认读取的数据的位置。Presto会传入filter条件,以便减少读取的数据的范围。元信息可以从磁盘上读取,也可以缓存在内存中。
- ConnectorSplit:一个IO Task处理的数据的集合,是调度的单元。一个split可以对应一个partition,或多个partition。
- SplitManager:根据表的meta,构造split。
- SlsPageSource:根据split的信息以及要读取的列信息,从磁盘上读取0个或多个page,供计算引擎计算。
基于Presto的插件我们可以开发这些功能:
- 对接自己的存储系统。
- 添加自定义数据类型。
- 添加自定义处理函数。
- 自定义权限控制。
- 自定义资源控制。
- 添加query事件处理逻辑。
目前Presto已经支持很多类型的Connector,具体可见官方文档:Presto-Connectors
Presto内存管理机制
Presto作为基于内存的计算引擎,对内存的分配很精细。Presto采用逻辑上的内存池,来管理不同类型的内存需求。Presto把机器的内存划分成三个内存池,分别是System Pool,Reserved Pool,General Pool。
- System Pool:保留给系统使用的内存,默认是Xmx的40%
- General Pool:大部分Query使用这个内存池中的内存,因为大部分Query消耗内存并不高
- Reserved Pool:用于给消耗内存最大的一个Query使用,这个内存池默认占10%的总内存,也表示一个Query在一台机器上最大的内存使用量
为什么Presto会使用内存池机制?
首先,System Pool为了系统正常运行以及数据传输时系统缓存消耗;在资源不充足时,一个消耗内存较大的Query开始运行,因为没足够空间所以会挂起等待执行,等一些消耗内存小的Query执行完,又有新的Query请求,内存一直不充足,如果没有Reserved Pool,这个消耗内存大的Query就会一直被挂起直到失败。为了防止这种情况,预留出Reserved Pool内存池供大Query执行。Presto每秒钟挑出来一个内存占用最大的query,允许它在所有机器上都能使用Reserved pool,避免一直没有可用内存供大Query使用。
如果大Query不在某些节点使用Reserved Pool就会浪费那台节点的预留内存,所以为什么不是单台机器中挑出占用内存最大的Task来使用Reserved Pool?
这样设计会死锁,假设一个大Query的一个Task在某台机器可用Reserved Pool很快执行完,而另外一台机器的Task还是挂起状态,这个Query也会一直处于挂起状态,效率降低。
Presto内存管理分为两部分:Query内存管理和机器内存管理,是由Coordinator负责的
Query内存管理:Query会划分为多个Task,每个Task会有一个线程循环获取Task状态包括内存使用情况,Query内存管理就是汇总这些Task的内存使用情况。
机器内存管理:Coordinator有一个线程定时轮询每台机器的内存状态
Presto执行计划
Presto与Spark、Hive一样,都是使用Antlr进行语法解析,一条SQL经过如下步骤最终生成在每个节点执行的LocalExecutionPlan逻辑计划。

样例:
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;生成的逻辑计划: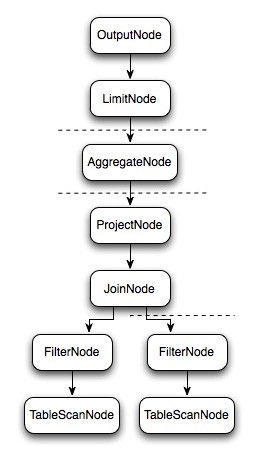
物理执行计划:逻辑计划的每一个SubPlan都会提交到一个或者多个Worker节点上执行,一个SubPlan也可以理解为一个Stage,SubPlan有几个重要的属性planDistribution、outputPartitioning、partitionBy属性。
- planDistribution有三种类型
- Source:数据源,会根据数据源大小确定分配多少个节点
- Fixed:分配到固定个数的节点执行(Config配置中的query.initial-hash-partitions参数配置,默认是8)
- None:这个SubPlan只分配到一个节点执行
- outputPartitioning有两种类型,表示这个SubPlan的输出是否按照partitionBy属性的key值对数据进行Shuffle。
- Hash:发生Shuffle
- None:不进行Shuffle
在下面的执行计划中,SubPlan1和SubPlan0 PlanDistribution=Source,这两个SubPlan都是提供数据源的节点,SubPlan1所有节点的读取数据都会发向SubPlan0的每一个节点;SubPlan2分配8个节点执行最终的聚合操作;SubPlan3只负责输出最后计算完成的数据。只有SubPlan0的OutputPartitioning=HASH(存在AggregateNode计划),所以SubPlan2接收到的数据是按照rank字段Partition后的数据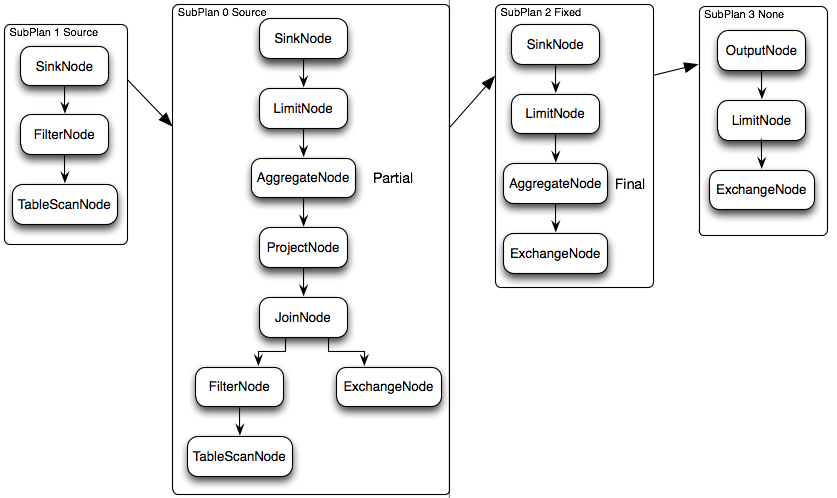
SQL提交并解析为SubPlan后的执行流程:
比如一条SQL最终生成4个SubPlan(0-3),其中0,1并行执行Join或聚合操作,其余串行执行,每个SubPlan都会分发到多个工作节点执行。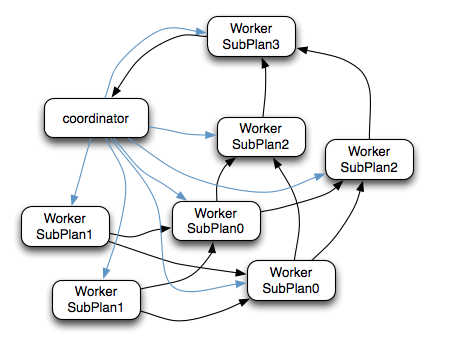
- Coordinator通过HTTP协议调用Worker节点的/v1/task接口将执行计划分配给所有Worker节点(图中蓝色箭头)
- SubPlan1的每个节点读取一个Split的数据并过滤后将数据分发给每个SubPlan0节点进行Join或聚合操作
- SubPlan1的每个节点计算完成后按GroupBy Key的Hash值将数据分发到不同的SubPlan2节点
- 所有SubPlan2节点计算完成后将数据分发到SubPlan3节点
- SubPlan3节点计算完成后通知Coordinator结束查询,并将数据发送给Coordinator
总结一条SQL在Presto执行的完整流程:
- 客户端通过HTTP协议发送一个查询语句给Presto集群的Coordinator
- Coordinator接收到客户端传来的查询语句,对该语句进行解析、生成查询执行计划,并根据查询执行计划依次生成SqlQueryExecution -> SqlStageExecution -> HttpRemoteTask
- Coordinator将每个Task分发到所需要处理的数据所在的Worker上进行分析
- 执行Source Stage的Task,这些Task通过Connector从数据源中读取所需要的数据
- 处于下游Stage中用的Task会读取上游Stage产生的输出结果,并在该Stage的每个Task所在的Worker内存中进行后续的计算和处理
- Coordinator从分发的Task之后,一直持续不断的从最后的Stage中的Task获得计算结果,并将结果写入到缓存中,直到所有的计算结束
- Client从提交查询后,就一直监听Coordinator中的本次查询结果集,立即输出。直到所有的结果都返回,本次查询结束
部署与使用
Presto集群部署
下载Presto
使用GUID生成工具生成所需机器数量相等的GUID,用于配置node.properties
cd $PRESTO_HOME
mkdir etc
# node.properties配置节点信息(每个节点不同)
vim etc/node.properties
node.environment=cdh 一个Presto集群有相同的env名称,我这里起名叫cdh
node.id=AB1C6EAC-8CF6-B397-EFD3-77C8AB041CD5 刚刚生成的GUID,每个节点都要不同的GUID
node.data-dir=/var/presto/data 存放数据的目录
# JVM配置(每个节点相同)
vim etc/jvm.config
-server
-Xmx4G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
# Presto配置 Coordinator节点 非生产集群单个节点可以既为Coordinator又为Worker可设node-scheduler.include-coordinator=true
vim etc/config.properties(每个节点不同)
coordinator=true 是否为Coordinator
node-scheduler.include-coordinator=false 是否在Coordinator节点执行计算(会影响性能,不建议true)
http-server.http.port=8080 请求发送的HTTP端口
query.max-memory=4GB 单条Query占用集群内存的最大值
query.max-memory-per-node=1GB 单条Query单个节点占用内存的最大值
query.max-total-memory-per-node=2GB 单条Quey单个节点占用的执行内存和系统内存(readers, writers, and network buffers, etc.)总和的最大值
discovery-server.enabled=true 整合Coordinator和DiscoveryServer为一个进程,使用同一个端口
discovery.uri=http://cdh101:8080
# Presto配置 Worker节点
vim etc/config.properties
coordinator=false
http-server.http.port=8080
query.max-memory=4GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery.uri=http://cdh101:8080 指定集群中已有的DS服务HTTP地址
# 日志等级设置(每个节点相同)
vim etc/log.properties
com.facebook.presto=INFO
# 配置支持Hive数据源 (每个节点相同)(其他数据源可参考https://prestodb.io/docs/current/connector)
mkdir etc/catalog
vim etc/catalog/hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://cdh101:9083
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
# ###############################################
ln -s /var/presto/data/var/log log 将日志链接到安装目录
在各个节点后台启动Presto:bin/launcher start
也可以在前台运行,查看具体的日志:bin/launcher run
停止服务进程命令:bin/laucher stop
启动脚本编写
#!/bin/bash
# 需要root用户免密
# 使用 sh presto-server.sh start
PRESTO_HOME=/opt/modules/presto-server-0.248
OP=$1
if [ "$OP" == "start" ] || [ "$OP" == "stop" ] || [ "$OP" == "status" ] || [ "$OP" == "restart" ]; then
echo "Begin to $OP Presto Coordinator and Workers."
for((host=101; host<=104; host++)); do
echo --- "$OP" presto server on cdh$host ---
ssh -l root cdh$host $PRESTO_HOME/bin/launcher "$OP"
done
else
echo "Usage: ./presto-server.sh [start|stop|restart|status]"
exit 1
fi
# ###############################################
根据自己的版本下载presto客户端:https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.248/presto-cli-0.248-executable.jar
chmod a+x presto-cli-0.248-executable.jar
mv presto-cli-0.248-executable.jar presto
ln -s /opt/modules/presto-server-0.248/presto /usr/bin/presto
进入Presto客户端(指定数据源hive,指定库名default) presto --server cdh101:8080 --catalog hive --schema default
# ###############################################
# 配置MySQL数据源
vim etc/catalog/mysql.properties
connector.name=mysql
connection-url=jdbc:mysql://cdh102:3306
connection-user=root
connection-password=123456Presto On Yarn部署
待补充Presto On kerberized Hive
Hive集群是Kerberos认证的安全集群,Presto Hive插件需要设置kerberos以及sasl相关属性,否则会报如下错误
-执行 ./presto --debug --execute 'show schemas' --server presto-server:8080 --catalog hive
Caused by: org.apache.thrift.transport.TTransportException: hms:9083: null
at com.facebook.presto.hive.metastore.thrift.Transport.rewriteException(Transport.java:92)
at com.facebook.presto.hive.metastore.thrift.Transport.access$000(Transport.java:32)
at com.facebook.presto.hive.metastore.thrift.Transport$TTransportWrapper.readAll(Transport.java:169)
at org.apache.thrift.protocol.TBinaryProtocol.readStringBody(TBinaryProtocol.java:380)
at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:230)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_all_databases(ThriftHiveMetastore.java:1187)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_all_databases(ThriftHiveMetastore.java:1175)
at com.facebook.presto.hive.metastore.thrift.ThriftHiveMetastoreClient.getAllDatabases(ThriftHiveMetastoreClient.java:89)
at com.facebook.presto.hive.metastore.thrift.ThriftHiveMetastore.getMetastoreClientThenCall(ThriftHiveMetastore.java:1068)
at com.facebook.presto.hive.metastore.thrift.ThriftHiveMetastore.lambda$getAllDatabases$0(ThriftHiveMetastore.java:219)
at com.facebook.presto.hive.metastore.thrift.HiveMetastoreApiStats.lambda$wrap$0(HiveMetastoreApiStats.java:48)
at com.facebook.presto.hive.RetryDriver.run(RetryDriver.java:139)
at com.facebook.presto.hive.metastore.thrift.ThriftHiveMetastore.getAllDatabases(ThriftHiveMetastore.java:218)
... 57 more
Suppressed: org.apache.thrift.transport.TTransportException: hms:9083: null
... 71 more
Caused by: org.apache.thrift.transport.TTransportException
at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132)
at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86)
at com.facebook.presto.hive.metastore.thrift.Transport$TTransportWrapper.readAll(Transport.java:166)
... 68 more参考:Presto hive-security
Presto默认没有使用权限认证,所有Query都是以运行PrestoServer进程的用户身份提交的.Presto Hive Plugin支持连接Kerberos集群以扩展权限管理,对数据做访问权限控制.集成Kerberos后,Presto可以模拟执行Query的用户来访问数据,数据权限得到控制.
vim etc/catalog/hive.properties 添加kerberos相关参数,并重启PrestoServers
connector.name=hive-hadoop2
hive.metastore.uri=thrift://metastoreIP:9083
hive.config.resources=/etc/ecm/hadoop-conf/core-site.xml,/etc/ecm/hadoop-conf/hdfs-site.xml
hive.metastore.authentication.type=KERBEROS
hive.metastore.service.principal=hive/metastoreIP@REALM.COM
hive.metastore.client.principal=hive/prestoServerIp@REALM.COM
hive.metastore.client.keytab=/opt/keytabs/hive.keytab
hive.hdfs.authentication.type=KERBEROS
hive.hdfs.impersonation.enabled=true
hive.hdfs.presto.principal=hive/prestoServerIp@REALM.COM
hive.hdfs.presto.keytab=/opt/keytabs/hive.keytab错误与异常排查解决:
在使用OSS存储的Hive集群使用Presto报错
Query 20220808_061604_00004_dp628 failed: java.lang.ClassNotFoundException: Class com.aliyun.jindodata.oss.JindoOssFileSystem not found
Query 20220809_023611_00025_43gsw failed: java.lang.NoClassDefFoundError: com/aliyun/jindodata/api/spec/JdoException解决:
拷贝jindo-sdk-4.4.1.jar和jindo-core-4.4.1.jar到$PRESTO_HOME/plugin/hive-hadoop2/
presto:db_name> select * from table_name limit 1;
Query 20220808_061604_00004_dp628, FAILED, 1 node
Splits: 17 total, 0 done (0.00%)
0:01 [0 rows, 0B] [0 rows/s, 0B/s]
查看Presto WebUI发现如下报错:
com.facebook.presto.spi.PrestoException: For input string: "30s"
at com.facebook.presto.hive.BackgroundHiveSplitLoader$HiveSplitLoaderTask.process(BackgroundHiveSplitLoader.java:128)
at com.facebook.presto.hive.util.ResumableTasks.safeProcessTask(ResumableTasks.java:47)
at com.facebook.presto.hive.util.ResumableTasks.access$000(ResumableTasks.java:20)
at com.facebook.presto.hive.util.ResumableTasks$1.run(ResumableTasks.java:35)
at com.facebook.airlift.concurrent.BoundedExecutor.drainQueue(BoundedExecutor.java:78)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NumberFormatException: For input string: "30s"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:589)
at java.lang.Long.parseLong(Long.java:631)
at org.apache.hadoop.conf.Configuration.getLong(Configuration.java:1311)
at org.apache.hadoop.hdfs.DFSClient$Conf.<init>(DFSClient.java:502)检查hive.config.resources中的hdfs-site.xml等文件,发现dfs.client.datanode-restart.timeout等配置参数值为30s,修改为30并重启PrestoServer即可.
Presto On Iceberg
Presto兼容Iceberg,参考Iceberg Connector配置Iceberg连接器配置vim etc/catalog/iceberg.properties 支持的Iceberg Catalog Type有hive和hadoop两种,配置方式分别为如下
iceberg.catalog.type=hive的配置方式:
connector.name=iceberg
hive.metastore.uri=thrift://metastoreIP:9083
hive.metastore.authentication.type=KERBEROS
hive.metastore.service.principal=hive/metastoreIP@REALM.COM
hive.metastore.client.principal=hive/prestoServerIp@REALM.COM
hive.metastore.client.keytab=/opt/keytabs/hive.keytab
iceberg.catalog.type=hive
iceberg.file-format=PARQUET
iceberg.compression-codec=SNAPPY
hive.config.resources=/etc/ecm/hadoop-conf/core-site.xml,/etc/ecm/hadoop-conf/hdfs-site.xmliceberg.catalog.type=hadoop的配置方式:
connector.name=iceberg
hive.metastore.uri=thrift://metastoreIP:9083
iceberg.catalog.type=hadoop
iceberg.file-format=PARQUET
iceberg.catalog.cached-catalog-num=10
iceberg.hadoop.config.resources=/etc/ecm/hadoop-conf/core-site.xml,/etc/ecm/hadoop-conf/hdfs-site.xml
iceberg.catalog.warehouse=hdfs://nameservice/user/iceberg/warehouse然后重启PrestoServer
与Hive整合:
到Iceberg-Releases页面下载对应版本(可在$PRESTO_HOME/plugins/iceberg下查看Presto Iceberg版本)的Hive runtime Jar。
下载libfb303-0.9.3.jar依赖包。
在hive-site.xml中添加
<property>
<name>iceberg.engine.hive.enabled</name>
<value>true</value>
</property>所有hive节点创建/etc/hive/auxlib目录,将两个jar放入
配置HiveServer2生效jar,在hive-site.xml添加
<property>
<name>hive.aux.jars.path</name>
<value>/etc/hive/auxlib</value>
</property>配置hiveCli生效jar
hive-env.sh增加export HIVE_AUX_JARS_PATH=/etc/hive/auxlib
重启HiveServer2
在hive创建Iceberg表
CREATE TABLE iceberg_db.hive_iceberg_table (
id BIGINT,
name STRING
)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler';使用Hive和Presto读写和操作Iceberg表
hive> insert into hive_iceberg_table values (1,'qjj'),(2,'abc');
presto> select * from hive_iceberg_table;
presto> insert into hive_iceberg_table values (3,'jjq'),(4,'def');
hive> select count(1) from hive_iceberg_table;相关TroubleShooting
- Vectorization only supported for Hive 3+
解决:设置set hive.vectorized.execution.enabled=false; - Presto插入Iceberg表String类型数据后,Hive读取不到String的值而是显示java.nio.HeapByteBuffer
待排查…
Presto语法:
SHOW CATALOGS; 查看Presto集群当前可用数据源
SHOW SCHEMAS; 查看当前数据源有哪些库
SHOW SCHEMAS FROM hive; 查看hive数据源的所有库 (FROM可以用IN替换)
SHOW TABLES; 查看当前Schema库下有哪些表
SHOW TABLES FROM hive.default; 查看hive数据源下default库下的所有表
CREATE SCHEMA hive.web WITH (location = 'hdfs:///user/hive/warehouse/web/') # 建库
ALTER SCHEMA old_db_name RENAME TO new_db_name # 改库名
-- 建表
CREATE TABLE hive.test.page_views (
view_time timestamp,
user_id bigint,
page_url varchar,
ds date,
country varchar
)
WITH (
format = 'Parquet',
partitioned_by = ARRAY['ds', 'country'],
bucketed_by = ARRAY['user_id'],
bucket_count = 50
);
-- 查看表
desc hive.test.page_views;
-- 查看表字段
SHOW COLUMNS IN hive.test.page_views;
-- 统计表信息(类似于Spark的Analyzed table)(数据大小,行数,最大值,最小值,无重复值个数,NULL值占比)
SHOW STATS FOR table
SHOW STATS FOR ( SELECT * FROM table [ WHERE condition ] )
-- 查看逻辑计划(相比Spark的逻辑计划,多了每个节点的行数及数据大小,CPU操作数,内存消耗,网络传输大小)
EXPLAIN sql
EXPLAIN ANALYZE sql -- 更全面 但会触发计算
-- 枚举表
SELECT * FROM (
VALUES
(1, 'a'),
(2, 'b'),
(3, 'c')
) t (id, name);
SELECT * FROM (
VALUES
(1, 'a', ARRAY[1, 2, 3]),
(2, 'b', ARRAY[4, 5, 6]),
(3, 'c', ARRAY[7, 8, 9])
) AS t (id, name, arr);
-- 准备好执行语句,延迟执行
PREPARE statement_1 FROM
show tables;
PREPARE statement_2 FROM
select * from test;
EXECUTE statement_2;
EXECUTE statement_1;
DEALLOCATE PREPARE statement_1;
DEALLOCATE PREPARE statement_2;
-- timestamp字段过滤条件 kafka_timestamp字段类型为timestamp(6)
select appid from iceberg.iceberg_db.iceberg_table where ds='2022120910' and kafka_timestamp = from_unixtime(1670625207.945); -- 效率更高
select appid from iceberg.iceberg_db.iceberg_table where ds='2022120910' and to_unixtime(kafka_timestamp) = 1670525207.945;Presto支持事务,相关命令有COMMIT,START TRANSACTION,ROLLBACK
更多语法:SQL Statement Syntax
Presto WEBUI
访问WEBUI地址即为DiscoveryServer地址:http://cdh101:8080/ui/
透过WEB UI可以查看到每个SQL Query的执行相关状态信息以及Presto集群的运行状态信息。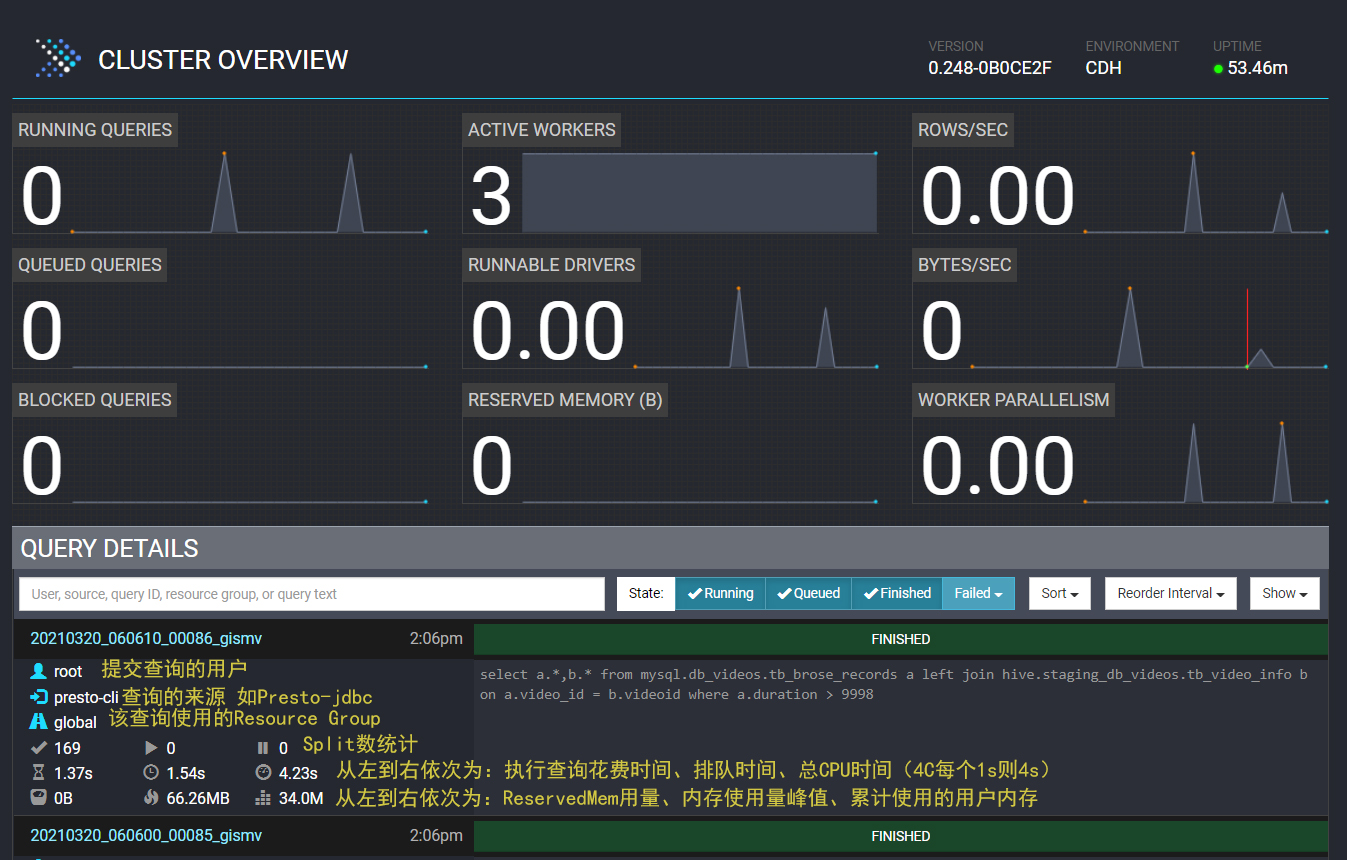
| 任务状态 | 原因 |
|---|---|
| QUEUED | 等待执行 |
| PLANNING | 正在转成执行计划 |
| RUNNING | 正在运行Query |
| BLOCKED | 阻塞中,等待内存、Buffer等资源 |
| FINISHING | 即将完成执行,正在返回数据 |
| FINISHED | 执行完成 |
| FAILED | 执行失败 |
BLOCKED状态是正常的,但持续很长时间都是这个状态就需要排查下原因,有很多可能的原因:
1.内存不足
2.磁盘或网络I/O瓶颈
3.数据倾斜(所有数据都转移到几个worker上)
4.并行度低(只有几个worker可用)
5.某个Stage查询开销较高(如select *操作数据过多)
对于某个Query的执行过程相关监控信息,可以在WebUI上点那个Query ID即可查看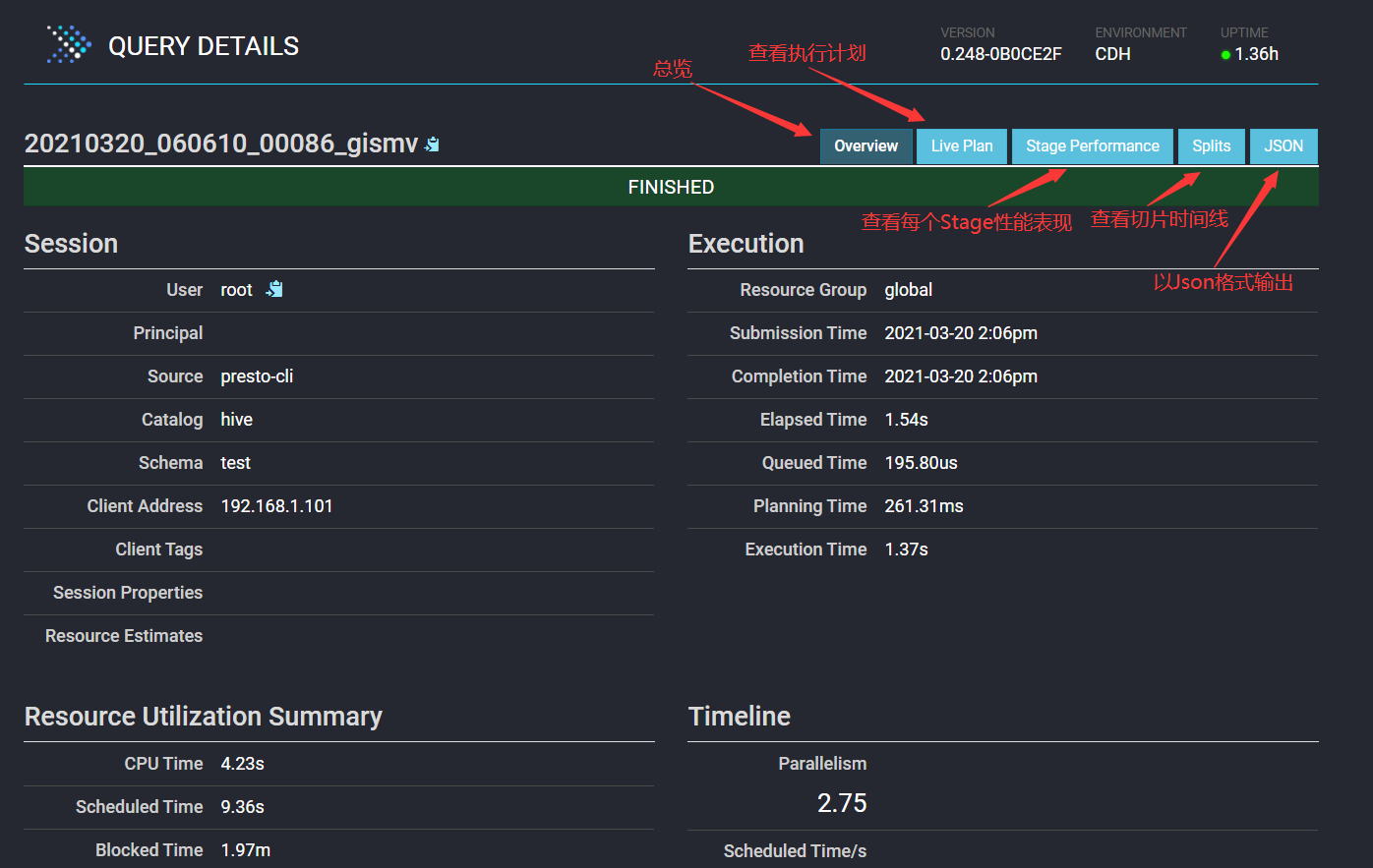
连接Presto
用户连接Presto的主要方式:Presto-Cli,JDBC,PyHive,PrestoOnSpark等。
Presto-Cli:
wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.248/presto-cli-0.248-executable.jar
mv presto-cli-0.248-executable.jar presto
chmod a+x presto
presto --server cdh101:8080 --catalog hive --schema default --user adminJDBC:
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.248</version>
</dependency>
public class PrestoConnetToJDBC {
public static void main(String[] args) throws SQLException {
// 1.简单创建连接
// String url = "jdbc:presto://cdh101:8080/hive/staging_db_users";
// Connection connection = DriverManager.getConnection(url, "root", null);
// connection.prepareStatement("show tables");
// 2.带参数创建连接
String url = "jdbc:presto://cdh101:8080/hive/staging_db_users";
Properties properties = new Properties();
properties.setProperty("user", "root");
properties.setProperty("password", "");
properties.setProperty("SSL", "false");
Connection connection = DriverManager.getConnection(url, properties);
// 3.带参数创建连接
// String url = "jdbc:presto://cdh101:8080/hive/staging_db_users?user=root&password=secret&SSL=true";
// Connection connection = DriverManager.getConnection(url);
// 读数据或做其他操作
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("select * from tb_user_info limit 10");
while (rs.next()){
System.out.println(rs.getString(1) + "--" + rs.getString(2));
}
}
}python:
pip3 install sasl
pip3 install thrift
pip3 install thrift-sasl
pip3 install PyHive
pip3 install sqlalchemy
pip3 install requests
from sqlalchemy import *
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import *
import pandas as pd
# Presto
engine = create_engine('presto://admin:123456@cdh101:8080/mysql/db_users') # 密码连接
engine = create_engine('presto://cdh101:8080/mysql/db_users')
df = pd.read_sql("select * from tb_user_records limit 10",engine)
print(df)PrestoOnSpark:
Presto on Spark即利用Spark作为Presto查询的执行框架
操作:Executing Presto on Spark
最佳实践
Presto参数调优:Properties Reference,官方详细介绍了Presto的config.properties中的常规参数如join参数,内存管理参数,Spilling溢出磁盘相关参数,数据网络交换参数(一个查询任务不同Stage会有不同节点交换数据,这些参数提高网络利用率),任务参数,节点调度参数,优化器参数以及正则相关参数
Presto不是纯内存计算吗?为什么要溢写到磁盘?
正常情况Presto执行Query请求的内存资源超过query_max_memory或query_max_memory_per_node这个Query就会被终止。
溢写磁盘机制:Presto节点空闲时Query会利用全部内存资源,如果没足够内存,Query被迫使用磁盘来存储中间数据,写入磁盘再从磁盘读取回来,有较高的IO开销。
解决IO开销高的方法:spiller-spill-path可设置多个磁盘多个路径,并行读写提高IO效率;spill-encryption-enabled启用压缩用CPU开销换IO开销
局限:系统无法将中间数据划分成足够小的块,导致从磁盘加载块数据时发生OOM;只有Join和聚合操作可以落盘资源隔离机制?
Presto可以像Yarn一样将全部资源分为多个资源组(通过配置文件etc/resource-groups.properties),资源组也可以有子组。配置可参考:Resource GroupsSession配置管理
通过配置etc/session-property-config.properties可以将任务分为不同类型(如即时查询,etl,高消耗etl等…),然后对不同类型的任务配置不同的资源,参数(configuration property)。具体见:Session Property Managers
(Presto参数分为configuration property和session property)分布式排序
需要排序数据超过单节点query.max-memory-per-node大小限制,默认会启用分布式排序(参数distributed-sort)。排序速度不会随节点数量增加而线性加快,因为排序后数据在单个节点合并使用Alluxio基于内存缓存热点数据和降低远程机房网络IO影响
注意:计算与存储节点共置的场景下,Alluxio对Presto的加速效果并不明显
Alluxio分布式缓存数据湖相关知识可以参考我的另一篇文章:Alluxio-基于内存的虚拟分布式存储系统
Presto结合Alluxio配置和使用可以参考官方文档:Alluxio Cache Service基于成本的优化
Join操作对查询性能影响大,Presto也会像Spark一样,评估Join的表的顺序,自动选择最低成本的Join表顺序。
对应的ConfigurationProperty(optimizer.join-reordering-strategy)
对应的SessionProperty(join_reordering_strategy)
参数值:AUTOMATIC全自动的Join优化,ELIMINATE_CROSS_JOINS默认参数消除不必要的笛卡尔积,NONE按SQL语法的顺序Join分布式Join算法选择
Presto的Join是基于Hash的,分为两种方式:Partitioned和Broadcast
Partitioned:每个节点都持有一部分Hash后的数据,然后Join
Broadcast:一个表被广播到所有参与Join计算节点
对应的ConfigurationProperty(join-distribution-type)
对应的SessionProperty(join_distribution_type)
参数值:AUTOMATIC全自动的Join算法选择,BROADCAST,PARTITIONED(默认)Presto会根据元数据信息读取分区数据,合理设置分区能减少Presto数据读取量,提升查询性能
Presto对ORC格式文件的读取进行了特定优化,相对于Parquet,Presto对ORC支持更好(Impala对Parquet支持更好)
数据压缩可以减少节点间数据传输对网络带宽的压力,对于即席查询需要快速解压,建议采用Snappy压缩算法
预先排序以提高性能
对于已经排序的数据,在查询的数据过滤阶段,ORC格式支持跳过读取不必要的数据。比如对于经常需要过滤的字段可以预先排序。
INSERT INTO table nation_orc partition(p) SELECT * FROM nation SORT BY n_name;
如果需要过滤 n_name 字段,则性能将提升:
SELECT count(*) FROM nation_orc WHERE n_name=’AUSTRALIA’;一些Presto优化常识
- 因为列式存储,尽量避免select *,而是只查询有用字段
- 对于有分区的表,where语句中优先使用分区字段进行过滤
- 合理安排__group by字段的顺序__有助于提高查询效率,这些字段按照每个字段distinct数据多少进行降序排列
- 多表Join时,数据越多的表越往后放,Left join时,条件过滤尽量在ON阶段完成,而少用WHERE,Join左边尽量放小数据量的表,而且最好是重复关联键少的表
- 将使用频繁的表作为一个子查询抽离出来,避免多次读取IO
Order by时使用limit:Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存。如果是查询Top N或者Bottom N,使用limit可减少排序计算和内存压力
精度要求低的场景使用近似聚合函数:Presto有一些近似聚合函数,对于允许有少量误差的查询场景,使用这些函数对查询性能有大幅提升。比如使用approx_distinct()函数比Count(distinct x)有大概2~3%的误差。
用regexp_like代替多个like语句:Presto查询优化器没有对多个like语句进行优化,使用regexp_like对性能有较大提升
[GOOD] SELECT xxx FROM access WHERE regexp_like(method, 'GET|POST|PUT|DELETE') [BAD] SELECT xxx FROM access WHERE method LIKE '%GET%' OR method LIKE '%POST%' OR method LIKE '%PUT%' OR method LIKE '%DELETE%'使用Rank函数代替row_number函数来获取Top N:在进行一些分组排序场景时,使用rank函数性能更好
[GOOD] SELECT checksum(rnk) FROM ( SELECT rank() OVER (PARTITION BY l_orderkey, l_partkey ORDER BY l_shipdate DESC) AS rnk FROM lineitem ) t WHERE rnk = 1 [BAD] SELECT checksum(rnk) FROM ( SELECT row_number() OVER (PARTITION BY l_orderkey, l_partkey ORDER BY l_shipdate DESC) AS rnk FROM lineitem ) t WHERE rnk = 1使用Presto分析统计数据时,可考虑把多次查询合并为一次查询,用Presto提供的子查询完成。
WITH subquery_1 AS ( SELECT a1, a2, a3 FROM Table_1 WHERE a3 between 20180101 and 20180131 ), /*子查询subquery_1,注意:多个子查询需要用逗号分隔*/ subquery_2 AS ( SELECT b1, b2, b3 FROM Table_2 WHERE b3 between 20180101 and 20180131 ) /*最后一个子查询后不要带逗号,不然会报错。*/ SELECT subquery_1.a1, subquery_1.a2, subquery_2.b1, subquery_2.b2 FROM subquery_1 JOIN subquery_2 ON subquery_1.a3 = subquery_2.b3;字段名与关键字冲突:MySQL对于关键字冲突的字段名加反引号,Presto对与关键字冲突的字段名加双引号。
Hive分析任务如何迁移Presto
Presto使用ANSI标准的SQL语法,Hive使用类SQL语法HQL
官方案例:Migrating From Hive
-- 1.Presto使用下标取数组元素 下标从1开始
select id,
arr[1] as arr2,
arr[3] as arr3
from
(SELECT * FROM (
VALUES
(1, 'a', ARRAY[1, 2, 3]),
(2, 'b', ARRAY[4, 5, 6]),
(3, 'c', ARRAY[7, 8, 9])
) AS t (id, name, arr)) a;
-- 2.不支持隐式数据类型转换,需要手动转换
SELECT
CAST(x AS varchar)
, CAST(x AS bigint)
, CAST(x AS double)
, CAST(x AS boolean)
FROM ...
SELECT CAST(5 AS DOUBLE) / 2;SELECT 5 / 2;
-- 3.WITH AS语法
WITH a AS
(SELECT uploader,videos
FROM tb_user_info
LIMIT 10)
select * from a;
-- 4.UNNEST关键字代替LATERAL VIEW explode()进行行转列
Hive写法:
SELECT student, score
FROM tests
LATERAL VIEW explode(scores) t AS score;
Presto写法:
SELECT student, score
FROM tests
CROSS JOIN UNNEST(scores) AS t (score);
-- 5.Hive视图不支持通过Presto查询,所以要在Presto创建同名视图(即在presto读取视图定义(StatementAnalyzer.java)的时候,解析原始的sql定义的语句,转换成presto的视图结构)
-- 6.cast as string不支持,因为Presto的是Varchar,需要在ASTBuilder.java中把string替换为了varchar类型
-- 7.select 1 = '1';在Hive和Presto计算结果分别为true,cannot be applied to integer, varchar(1) 需要额外操作实现透明的隐式转换
-- 8.UDF支持、null值处理
-- 9.对于timestamp类型字段做where条件比较,hive可以直接比较,presto需要加timestamp关键字
/*Hive的写法*/
SELECT t FROM a WHERE t > '2021-01-01 00:00:00';
/*Presto中的写法*/
SELECT t FROM a WHERE t > timestamp '2021-01-01 00:00:00';
-- 10.Presto的MD5传入binary类型则会返回binary类型,所以对字符串的MD5需要转换:
SELECT to_hex(md5(to_utf8('abcd')));
-- 11.Presto不支持INSERT OVERWRITE,只能先DELETE再INSERT- Hive数仓的数据安全性和权限
参考Built-in System Access Control
在我看来hive.security=file形式的授权比较灵活
先配置全局的Catalog访问权限:
user:可选参数,正则匹配用户名,默认.*
catalog:可选参数,正则匹配Catalog名,默认.*.
allow:必选参数,用户是否对calalog有访问权限true\false
# 启用基于文件的权限控制
vim /opt/modules/presto-server-0.248/etc/access-control.properties
access-control.name=file
security.config-file=/opt/modules/presto-server-0.248/etc/rules.json
security.refresh-period=10s # 配置权限自动刷新时间间隔 10s
# 设置权限控制规则:允许只admin用户有mysql catalog的权限,所有用户有hive catalog权限,所有用户无system catalog权限
vim /opt/modules/presto-server-0.248/etc/rules.json
{
"catalogs": [
{
"user": "admin",
"catalog": "(mysql|system)",
"allow": true
},
{
"catalog": "hive",
"allow": true
},
{
"catalog": "system",
"allow": false
}
]
}
分发access-control.properties和rules.json,重启PrestoServer生效
连接PrestoClient并指定用户presto --server cdh101:8080 --catalog hive --schema default --user qjj配置hive数据源的权限,参考Hive Security Configuration
有legacy,read-only,file,sql-standard四种形式,仍然是file的授权形式比较灵活
vim etc/catalog/hive.properties
hive.security=file
security.config-file=/opt/modules/presto-server-0.248/etc/catalog/hive-security.json
vim /opt/modules/presto-server-0.248/etc/catalog/hive-security.json
{
"schemas": [
{
"user": "admin",
"schema": ".*",
"owner": true
},
{
"user": "staging",
"owner": false
},
{
"user": "test",
"schema": "test",
"owner": false
}
],
"tables": [
{
"user": "admin",
"privileges": ["SELECT", "OWNERSHIP"]
},
{
"user": "staging",
"table": "(staging_db_users|staging_db_videos).*",
"privileges": ["SELECT"]
},
{
"user": "test",
"table": "test.*",
"privileges": ["SELECT"]
}
]
}
分发catalog/hive.properties、catalog/hive-security.json
重启Presto-server总结
- Hive\Spark的SQL任务迁移到Presto在语法、计算结果、视图使用、类型转换、UDF及空值处理上有差异
- Hive\Spark任务迁移Presto,如果要做到对业务透明,还有很长的路要走
参考资料
Presto Documentation
Iceberg Hive Doc
深入理解Presto
Presto实现原理和美团的使用实践
Hive迁移Presto在OPPO的实践
零基础熟悉 Presto的概念、安装、使用及优化



