







实现基于Spark的数据脱敏
前言
Spark是当前大数据领域不可替代的重要组件,拥有成熟的生态、强大的性能和广泛的应用场景,但在数据安全越来越重要的今天,Spark在对数据权限的管控能力方面仍然没有进展。
不仅仅是Spark,大多数大数据生态圈中的组件都缺乏对数据安全的管控,于是很多硬件资源较充裕的公司会将数据全量脱敏后分别存放,牺牲存储空间来达到数据脱敏的目的;而有些公司选择Apache Ranger作为权限管控组件,但Ranger(目前版本2.2)在设计上对各个大数据组件版本有着严格的依赖,且暂时不支持对Spark的权限管控。
经过阅读Ranger源码,以及在测试环境试用后,确定了Ranger方案不可行,我决定在Spark基础上二次开发来实现数据脱敏功能。
知识准备
- SparkSQL执行过程:SQL->Parser(Antlr)->AST->Catalyst->UnresolvedLogicalPlan->Analyzer->Optimizer->PhysicalPlan->执行计算和IO
- 以上过程直到物理计划都是继承自LogicalPlan,共四种:
UnresolvedLogicalPlan: 也叫ParsedLogicalPlan,是根据语法树解析SQL后得到的逻辑计划,没有关联catalog,没有获取底层存储的元数据信息,也就是说SELECT *在这个阶段不会被解析为具体字段(AnalyzedLogicalPlan、OptimizedLogicalPlan、PhysicalPlan可看到具体字段)。
AnalyzedLogicalPlan: 结合表的Catalog,绑定元数据,resolve化LogicalPlan,替换掉UnresolvedLogicalPlan,这里会检查表是否存在以及Schema完整性。绑定元数据是否成功主要有两点:1.子节点是否是resolved 2.输入的数据类型是否满足要求,具体可参考类:Expression,Analyzer类。
OptimizedLogicalPlan:对AnalyzedLogicalPlan进行优化,有很多RuleExecutor,如谓词下推,Filter裁剪,WholeStageCodegen(大量类型转换和虚函数调用转为即时编译),RemoveLiteralFromGroupExpressions移除group下的常量,RemoveRepetitionFromGroupExpressions移除重复的group表达式等…
PhysicalPlan:将OptimizedLogicalPlan转换为实际执行的步骤,具体可参考SparkPlanner类。// 拿到四种执行计划的方法 val sql:String = "select * from qjj" // 单独获取UnresolvedLogicalPlan,不用读元数据,效率最高 val unresolvedLogicalPlan:LogicalPlan = sqlContext.sparkSession.sessionState.sqlParser.parsePlan(sql) // 获取QueryExecution val qe:org.apache.spark.sql.execution.QueryExecution = sqlContext.sparkSession.sql(sql).queryExecution // 通过QueryExecution获取所有计划包括ParsedLogicalPlan,AnalyzedLogicalPlan,OptimizedLogicalPlan和PhysicalPlan val parsedLogicalPlan:LogicalPlan = qe.logical val analyzedLogicalPlan:LogicalPlan = qe.analyzed val optimizedLogicalPlan:LogicalPlan = qe.optimizedPlan val physicalPlan:LogicalPlan = qe.executedPlan val physicalPlan:LogicalPlan = qe.sparkPlan - LogicalPlan包含三种子类型UnaryNode,BinaryNode和LeafNode,每种子类型下又有多种子类型,子类型下又包含子类型如:Project,GlobalLimit,LocalLimit,CreateTable,Distinct,SubqueryAlias,InsertIntoTable,Join,Aggregate,Union,Filter等。
- Dataset和DataFrame的区别与联系:
联系:
1.API统一,使用上没差别
2.DataFrame算是特殊类型的Dataset,是每个元素都为ROW类型的Dataset(DataFrame = Dataset[Row])
区别:
1.Dataset是强类型,编译时检查类型,DataFrame是弱类型,执行时才检查类型
2.Dataset是通过Encoder进行序列化,支持动态的生成代码,直接在bytes的层面进行排序过滤等的操作;而DataFrame是采用可选的java的标准序列化或是kyro进行序列化 - Spark的TemporaryView:
Spark的四种视图创建方法:
①df.createGlobalTempView(df.createOrReplaceGlobalTempView) 创建全局临时视图,多个SparkSession共享 SparkSQL写法:create global temporary view view_name(col1,col2…) as select (col1,col2…) from table_name;
②df.createTempView(df.createOrReplaceTempView) 创建Session级别的临时视图,多个SparkSession不共享 SparkSQL写法:create temporary view view_name(col1,col2…) as select (col1,col2…) from table_name;
通过SQL创建视图时会有几种异常:
It is not allowed to define a TEMPORARY view with IF NOT EXISTS. (创建视图不支持if not exists)
It is not allowed to add database prefixtestfor the TEMPORARY view name. (创建视图不支持库名前缀)
Not allowed to create a permanent view by referencing a temporary function. (不支持用带临时UDF的逻辑创建永久视图)
视图删除:
spark.catalog.dropTempView(‘view_name’)
spark.catalog.dropGlobalTempView(‘global_view_name’)
全局视图调用:
spark.sql(“select * from global_temp.view_name”) 需要加global_temp前缀 - 从一条SQL到ThriftServer上的一个Job,如何生成:
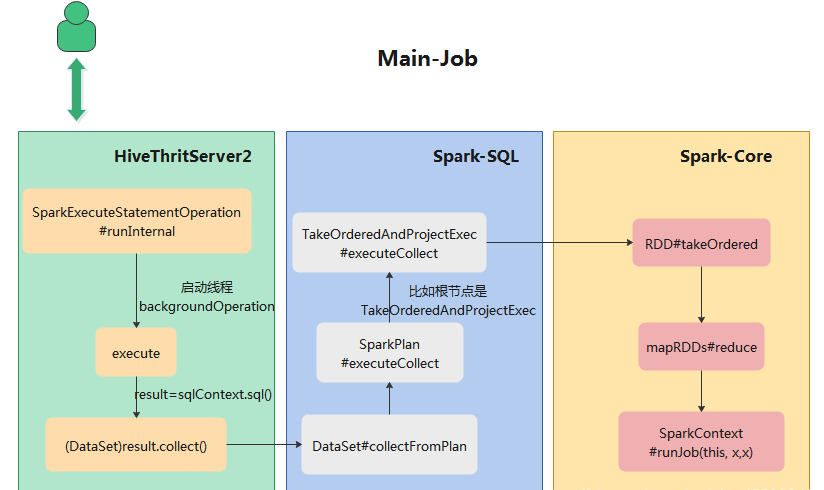
(该图引自SparkSQL并行执行多个Job的探索,文章不错,推荐有空看看)
基于SparkThriftServer的数据脱敏
工作原理流程
流程: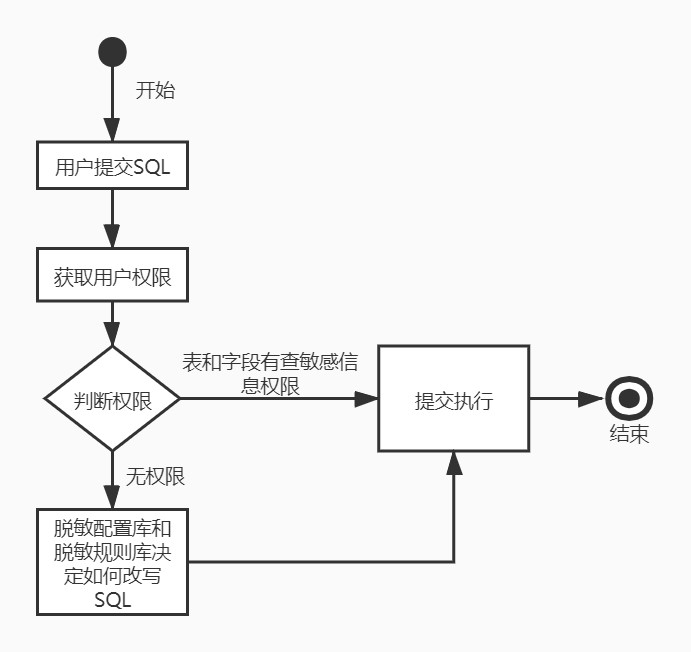
原理: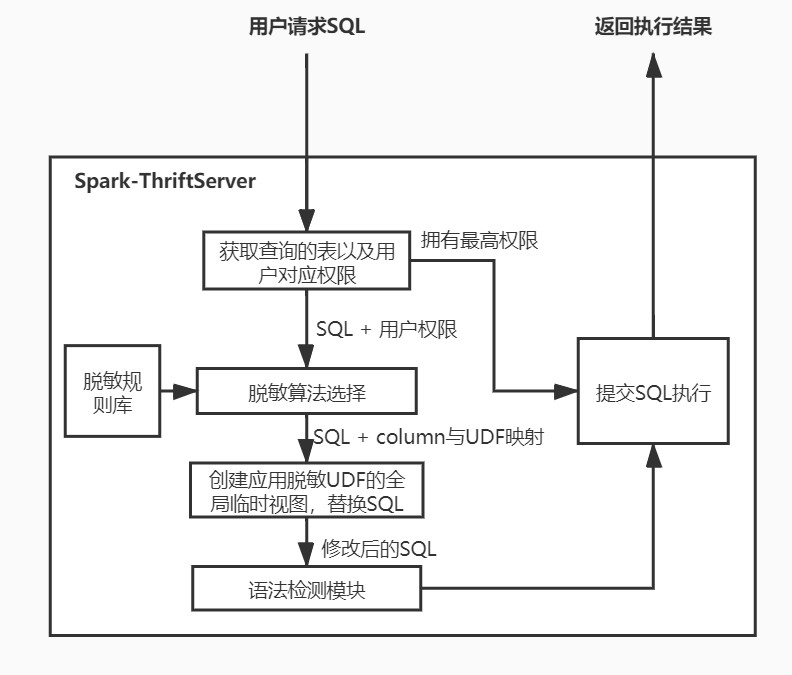
实现细节
数据库建表:
-- 脱敏规则表
create table desensitization_rules(
rule_name varchar(100) not null primary key comment "脱敏规则名称",
rule_type varchar(100) not null comment "类型-可逆、不可逆、加密、解密",
encrypt_column_type varchar(100) not null comment "可加密的敏感数据分类如phone_num、id_card、bank_account、cust_name",
encrypt_udf_name varchar(100) comment "对应脱敏UDF名称",
decrypt_udf_name varchar(100) comment "解密UDF名称",
create_datetime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP comment "规则创建时间"
)ENGINE=Innodb comment='脱敏规则库-用于配置脱敏规则与对应的加密UDF、解密UDF和加密数据类型的映射关系';
-- 脱敏配置表
create table desensitization_conf(
db_table varchar(255) comment "库名.表名,为*代表对所有表都生效",
column_name varchar(255) not null comment "单个敏感字段名",
column_type varchar(100) not null comment "敏感字段数据分类",
rule_name varchar(100) not null comment "脱敏规则名称",
create_datetime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP comment "创建时间",
PRIMARY KEY (db_table,column_name)
)ENGINE=Innodb comment='脱敏配置表-具体到字段的脱敏配置,该表决定如何脱敏,未配置的 默认是白名单';
-- 角色权限表
create table desensitization_role_permissions(
role varchar(100) not null primary key comment "角色",
authorized_dbs varchar(1000) NOT NULL comment "有查敏感信息权限的库,逗号隔开,all表示全部库",
authorized_tables text NOT NULL comment "有查敏感信息权限的表,逗号隔开-库名.表名,all表示全部表",
authorized_data_type varchar(1000) NOT NULL comment "有权限的敏感数据类型如phone_num、id_card、account_num、cust_name,all表示数据类型",
authorized_columns text NOT NULL comment "有权限的字段名,多个字段逗号隔开,all表示全部字段",
create_datetime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP comment "角色创建时间"
)ENGINE=Innodb comment='角色权限表-用于配置每个角色的权限';
-- 用户权限表
create table desensitization_user_role(
user varchar(100) not null primary key comment "用户名",
role varchar(255) not null comment "角色,多个角色逗号隔开",
create_datetime timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP comment "添加时间"
)ENGINE=Innodb comment='用户角色映射关系表-默认无查询敏感数据的权限';
-- ----------配置数据----------
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","phone_num","phone_num","HideLast4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","phone","phone_num","HideLast4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","phone_number","phone_num","HideLast4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","mobile","phone_num","HideLast4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","mobile_phone","phone_num","HideLast4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","mobile_no","phone_num","HideLast4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","phone_no","phone_num","HideLast4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","cust_name","cust_name","HideUserName");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("*","bank_card_no","bank_account","HideBankCardNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("test_pn","phone_num","phone_num","HideMid4PhoneNumber");
insert into desensitization_conf(db_table,column_name,column_type,rule_name) values ("test_pn","phone","phone_num","HideMid4PhoneNumber");
insert into desensitization_role_permissions(role,authorized_dbs,authorized_tables,authorized_data_type,authorized_columns) values ("admin","all","all","all","");
insert into desensitization_role_permissions(role,authorized_dbs,authorized_tables,authorized_data_type,authorized_columns) values ("d_bd","d_bd","","","cust_name");
insert into desensitization_role_permissions(role,authorized_dbs,authorized_tables,authorized_data_type,authorized_columns) values ("d_qjj","","d_bd.test_qjj","","cust_name");
insert into desensitization_user_role(user,role) values ("admin","d_bd,d_qjj");
insert into desensitization_user_role(user,role) values ("bd_admin","admin"); 这样设计权限考虑的点:
1.用户权限按角色管理
2.用户可以有多个角色
3.可以方便用户临时申请权限
4.敏感数据的字段可以支持默认脱敏配置
5.可以细粒度地指定某个用户查询某个表某个字段时如何脱敏
6.对数据进行敏感信息分类,方便按敏感数据类型控制权限(表设计了但实际没实现这块)
代码实现
SQLAnalyzer类,工具类,主要是匹配SQL中的表以及判断SQL类型,下面列举主要方法
/**
* Get all tables in a select sql
* @param sql
* @return List(table1,table2) or List()
*/
def getTablesInSelect(sql:String):List[String] = "(?i)(?:from|join)\\s+[a-zA-Z0-9_.]+"
.r.findAllIn(sql)
.map(x => x.replaceFirst("(?i)(?:from|join)\\s+", ""))
.toList
/**
* Determines SQL is a select statement or not.
* @param sql
* @return boolean
*/
def isSelectSQL(sql:String):Boolean =
!StringUtils.isBlank(sql) &&
sql.trim.replaceAll("\r|\n|\r\n"," ").matches("(?i)\\s*select.*")
/**
* Determines SQL is a Data transfer statement or not.
* @param sql
* @return boolean
*/
def isSelectInsertSQL(sql:String):Boolean =
!StringUtils.isBlank(sql) &&
sql.trim.replaceAll("\r|\n|\r\n"," ").matches("(?i)\\s*insert.*select.*")DesensitizationModule类,脱敏模块,实现了:读取并缓存脱敏配置;用户权限聚合,鉴权,创建临时视图并应用脱敏规则,替换SQL生成真正执行的SQL,其中getDesensitizedSQL是这个类提供给外部的方法,返回的是实际执行的SQL,用于替换原来的逻辑计划。loadDesensitizationMeta也是提供给外部的方法,用于加载脱敏配置和用户权限信息。
package org.apache.spark.sql.hive.thriftserver.desensitization
import com.smy.exceptions.DesensitizationException
import org.apache.spark.internal.Logging
import org.apache.spark.sql.hive.thriftserver.xxxxx.getDF // 连接mysql,查询脱敏配置得到dataframe的方法
import org.apache.spark.sql.{SQLContext, SparkSession}
import org.apache.spark.sql.hive.thriftserver.desensitization.SQLAnalyzer._
import scala.tools.scalap.scalax.util.StringUtil
private[hive] object DesensitizationModule extends Logging{
// entities
case class DesensitizationConf(columnName: String, columnType: String, ruleName:String)
case class Permission(role: String, authorizedDBs: String, authorizedTables:String, authorizedDataTypes:String, authorizedColumns:String)
object DesensitizationMeta {
var RULE_UDF_MAP: Map[String, String] = _ //desensitization_rules
var DBTABLE_DESENSITIZATION_CONF_MAP: Map[String, Set[DesensitizationConf]] = _ //desensitization_conf
var USER_PERMISSION_MAP: Map[String, Permission] = _ //desensitization_user_permissions
var ROLE_PERMISSION_MAP: Map[String, Permission] = _ //desensitization_role_permissions
var DEFAULT_COLUMN_UDF_MAPPING: Map[String,String] = _
}
private def getMergedParas(para1: String, para2: String, isRolePara: Boolean=false): String = {
if(isRolePara && (para1.split(",").contains("admin") || para2.split(",").contains("admin"))) return "admin"
if (para1 != null && para1.nonEmpty && para2 != null && para2.nonEmpty) {
if(para1.split(",").contains("all") || para2.split(",").contains("all")) return "all"
s"$para1,$para2"
} else if (para1 != null && para1.nonEmpty) {
if(para1.split(",").contains("all")) return "all"
para1
} else if (para2 != null && para2.nonEmpty){
if(para1.split(",").contains("all")) return "all"
para2
}else{
""
}
}
private def permissionReduce(p1: Permission, p2: Permission): Permission = Permission(
getMergedParas(p1.role,p2.role,true),
getMergedParas(p1.authorizedDBs, p2.authorizedDBs),
getMergedParas(p1.authorizedTables, p2.authorizedTables),
getMergedParas(p1.authorizedDataTypes, p2.authorizedDataTypes),
getMergedParas(p1.authorizedColumns, p2.authorizedColumns))
private def getFullTableName(tableName:String):String = if (tableName.isEmpty || tableName.equals("*")) "*" else if(tableName.contains(".")) tableName else s"default.$tableName"
/**
* Load desensitization metadata
* @param sqlContext
* @return true->succeed false->failed
*/
def loadDesensitizationMeta(sqlContext: SQLContext):Boolean = {
logWarning("Loading desensitization meta.")
try {
// load RULE_UDF_MAP
DesensitizationMeta.RULE_UDF_MAP = getDF(sqlContext, "select rule_name,encrypt_udf_name from desensitization_rules")
.collect()
.map(x => (x.get("rule_name"), x.get("encrypt_udf_name"))).toMap
// load DBTABLE_DESENSITIZATION_CONF_MAP
val desensitizationConfMap = scala.collection.mutable.Map[String,scala.collection.mutable.MutableList[DesensitizationConf]]()
getDF(sqlContext,"select db_table,column_name,column_type,rule_name from desensitization_conf")
.collect()
.foreach{x =>
val desensitizationConf = DesensitizationConf(x.get("column_name"), x.get("column_type"), x.get("rule_name"))
if(desensitizationConfMap.get(x.get("db_table")).orNull==null){
desensitizationConfMap.put(x.get("db_table"),scala.collection.mutable.MutableList(desensitizationConf))
}else{
desensitizationConfMap(x.get("db_table")) += desensitizationConf
}
}
DesensitizationMeta.DBTABLE_DESENSITIZATION_CONF_MAP = desensitizationConfMap.map(x => (getFullTableName(x._1),x._2.toSet)).toMap
// load USER_PERMISSION_MAP and ROLE_PERMISSION_MAP
DesensitizationMeta.ROLE_PERMISSION_MAP = getDF(sqlContext, "select role,authorized_dbs,authorized_tables,authorized_data_type,authorized_columns from desensitization_role_permissions")
.collect()
.map {x =>
(x.get("role"), Permission(x.get("role"),
x.getOrDefault("authorized_dbs",""),
x.getOrDefault("authorized_tables",""),
x.getOrDefault("authorized_data_type",""),
x.getOrDefault("authorized_columns","")))
}.toMap
DesensitizationMeta.USER_PERMISSION_MAP = getDF(sqlContext, "select user,role from desensitization_user_role where user != '' and role != ''")
.collect()
.map{ x => (x.get("user"),
x.get("role")
.split(",")
.map(role => DesensitizationMeta.ROLE_PERMISSION_MAP.getOrElse(role,null))
.filter(x => x != null)
.reduce(permissionReduce)
)
}.toMap
// load DEFAULT_COLUMN_UDF_MAPPING (db_table is * means default global column desensitization configuration.)
DesensitizationMeta.DEFAULT_COLUMN_UDF_MAPPING = DesensitizationMeta.DBTABLE_DESENSITIZATION_CONF_MAP.getOrElse("*",Set())
.map { ddc =>
val udfName = DesensitizationMeta.RULE_UDF_MAP.getOrElse(ddc.ruleName,null)
if (udfName == null) {
throw new DesensitizationException(s"The mask rule ${ddc.ruleName} on column ${ddc.columnName} is not right or no Configured UDF.Please check desensitization_conf.")
}
(ddc.columnName, udfName)
}.toMap
logWarning(s"## RULE_UDF_MAP ==> ${DesensitizationMeta.RULE_UDF_MAP}")
logWarning(s"## DBTABLE_DESENSITIZATION_CONF_MAP ==> ${DesensitizationMeta.DBTABLE_DESENSITIZATION_CONF_MAP}")
logWarning(s"## USER_PERMISSION_MAP ==> ${DesensitizationMeta.USER_PERMISSION_MAP}")
logWarning(s"## DEFAULT_COLUMN_UDF_MAPPING ==> ${DesensitizationMeta.DEFAULT_COLUMN_UDF_MAPPING}")
true
}catch {
case e:Exception =>
throw new DesensitizationException("Exception when reloadAuth",e)
false
}
}
/**
* create temporary view and get the view name.
* The temporary view will clear when spark session exited.
* @param spark SQLContext
* @param tableName Full tableName with database prefix.
* @param userName
*/
def createAndGetTempViewName(spark:SQLContext,userName:String,tableName:String):String={
val columns = spark.table(tableName).columns
val sourceCols = columns.mkString(",")
val newViewName = tableName.replace(".","_") + "_" + System.currentTimeMillis()
try{
val colUDFMap:Map[String,String] = getTableColUDFMapping(tableName, userName, columns)
if(colUDFMap.isEmpty) return tableName
logWarning(s"### Desensitization table:$tableName user:$userName columnUDFMapping:$colUDFMap")
val viewCols = columns.map { col =>
if (!colUDFMap.contains(col)) {
col
} else {
colUDFMap(col) + s"($col)"
}
}.mkString(",")
spark.sql(s"create temporary view $newViewName($sourceCols) as select $viewCols from $tableName")
newViewName
}catch {
case e:Exception =>
logError(s"Failed to create a masked temporary view on table $tableName.",e)
// If there is an exception, return the source table name.
tableName
}
}
/**
* Determine whether the user has access to the table and get the desensitization strategy of table columns.
* @param tableName FullTableName with database prefix
* @param userName userName
* @param tableColumns 表的所有字段
* @return columnUDFMap
*/
def getTableColUDFMapping(tableName:String,userName:String,tableColumns:Array[String]):Map[String,String] = {
logInfo(s"Begin to get table($tableName) user($userName) auth and col-udf mapping.")
// Judge User permission.
val userPermission = DesensitizationMeta.USER_PERMISSION_MAP.getOrElse(userName,Permission("","","","",""))
if(userPermission.role.equals("admin")){
// user role is admin.
return Map()
}else if("all".equals(userPermission.authorizedDBs) || userPermission.authorizedDBs.split(",").contains(tableName.split("\\.")(0))) {
//User has permissions for this database.
return Map()
}else if("all".equals(userPermission.authorizedTables) || userPermission.authorizedTables.split(",").map(getFullTableName).contains(tableName)) {
//User has permissions for this table.
return Map()
}else if("all".equals(userPermission.authorizedDataTypes)){
return Map()
}else if("all".equals(userPermission.authorizedColumns)){
// User has permissions for all fields.
return Map()
}
val result:scala.collection.mutable.Map[String,String] = scala.collection.mutable.Map[String,String]()
// Apply specified desensitization conf.
// TODO: User has access to one dataType?
val authorizedCols:Set[String] = userPermission.authorizedColumns.split(",").toSet
val unauthorizedCols:Set[String] = DesensitizationMeta.DEFAULT_COLUMN_UDF_MAPPING.keySet -- authorizedCols
val tableSpecificDesensitizationConf:Set[DesensitizationConf] = DesensitizationMeta.DBTABLE_DESENSITIZATION_CONF_MAP.getOrElse(tableName,Set())
if(tableSpecificDesensitizationConf.nonEmpty) {
logWarning(s"Table $tableName has specific desensitization rules.")
tableSpecificDesensitizationConf.foreach{ tsdc =>
val udfName = DesensitizationMeta.RULE_UDF_MAP.get(tsdc.ruleName).orNull
if (udfName == null) {
throw new DesensitizationException(s"The mask rule ${tsdc.ruleName} on table $tableName column ${tsdc.columnName} is not right or no Configured UDF.Please check desensitization_conf.")
}
logInfo(s"Apply specific desensitization udf: ${tsdc.columnName} => $udfName .")
result.put(tsdc.columnName,udfName)
}
}else{
logInfo(s"There is no specific desensitization conf in table $tableName.Use default desensitization conf.")
}
// Apply default desensitization conf.
unauthorizedCols.foreach{ uc =>
if(tableColumns.contains(uc) && !result.contains(uc)) {
val udfName = DesensitizationMeta.DEFAULT_COLUMN_UDF_MAPPING.get(uc).orNull
// if (udfName == null) {
// throw new DesensitizationException(s"There is no desensitization UDF associated with column $uc ,Please check desensitization_conf where db_table='*'.")
// }
logInfo(s"Apply default desensitization udf: $uc => $udfName .")
result.put(uc,udfName)
}
}
result.toMap
}
/**
* Main method to generate desensitized sql.
* @param spark sparkSession
* @param userName request user of this sql
* @param sql
* @return Desensitized sql
*/
def getDesensitizedSQL(spark:SQLContext,userName:String,sql:String):String = {
if(isSelectSQL(sql)){
val tableList = getTablesInSelect(sql)
if(tableList.isEmpty){
return sql
}
var outputSQL:String = sql
tableList
.foreach { table =>
val viewName = createAndGetTempViewName(spark, userName,getFullTableName(table))
logInfo(s"tableName: $table => viewName: $viewName")
outputSQL = outputSQL.replace(table, viewName)
}
outputSQL
}else if(isSelectInsertSQL(sql)){
//TODO: There is a vulnerability in the export of sensitive data.
// 'insert select' operation and 'create table as select' operation.
sql
}else{
sql
}
}
}寻找修改切入点
org.apache.spark.sql.hive.thriftserver.SparkExecuteStatementOperation类,是ThriftServer提供服务的入口,其中我们只需要将执行时的逻辑计划替换掉即可,该类中execute方法中可以找到源码:
// Always set the session state classloader to `executionHiveClassLoader` even for sync mode
if (!runInBackground) {
parentSession.getSessionState.getConf.setClassLoader(executionHiveClassLoader)
}
sqlContext.sparkContext.setJobGroup(statementId, substitutorStatement, forceCancel)
result = sqlContext.sql(statement)
logDebug(result.queryExecution.toString())
HiveThriftServer2.eventManager.onStatementParsed(statementId,
result.queryExecution.toString())
iter = if (sqlContext.getConf(SQLConf.THRIFTSERVER_INCREMENTAL_COLLECT.key).toBoolean) {
new IterableFetchIterator[SparkRow](new Iterable[SparkRow] {
override def iterator: Iterator[SparkRow] = result.toLocalIterator.asScala
})
} else {
new ArrayFetchIterator[SparkRow](result.collect())
}我们可以明确的是statement是用户提交运行的SQL,后面触发计算操作时调用了result.collect(),则result就是这条SQL的结果集,我们需要修改的就是result这个dataframe对象。
修改方法很简单,用我们脱敏后的SQL重新生成ParsedLogicalPlan,再用Dataset.ofRows得到新的Dataset:
var logicalPlan = sqlContext.sparkSession.sessionState.sqlParser.parsePlan(statement)
// Desensitization
var sqlAfterDesensitization:String = statement
try{
sqlAfterDesensitization = DesensitizationModule.getDesensitizedSQL(sqlContext, parentSession.getUserName, sql)
if(!sqlAfterDesensitization.equals(statement)){
logWarning(s"### SQL has changed after Desensitization Module. outputSQL: $sqlAfterDesensitization ###")
logicalPlan = sqlContext.sparkSession.sessionState.sqlParser.parsePlan(sqlAfterDesensitization)
}else{
logInfo(s"###经过脱敏模块处理后的SQL为: $statement 未发生改变###")
}
}catch {
case e:Exception =>
logError("***There may be some errors in DesensitizationModule.getDesensitizedSQL ***", e)
// throw new DesensitizationException("Desensitization failed.",e) // Table not found and sql syntax error also throw this.
}
result=Dataset.ofRows(sqlContext.sparkSession, logicalPlan)这样在需要脱敏时逻辑计划就可以被替换并执行后续的操作了,返回给用户的数据也是脱敏后的数据。
UDF编写和注册
DesensitizationUDFs类,注册脱敏UDF的统一入口,在org.apache.spark.sql.hive.thriftserver.SparkSQLSessionManager的OpenSession方法中调用:DesensitizationUDFs.register(ctx,username),为正在登陆的用户调用注册UDF,保证UDF可用。但如果有用户恶意频繁登陆会触发频繁UDF注册,导致Thriftserver负载高,故可设置免UDF加载的白名单用户参数:–conf “spark.thrift.desensitization.load.udf.user.whitelist=user1,admin”
// Register Desensitization UDFs
var loadUDFWhitelist:Array[String] = Array()
try{
// 提交任务时加--conf "spark.thrift.desensitization.load.udf.user.whitelist=user1,admin" 这些用户不加载脱敏UDF
loadUDFWhitelist = ctx.sparkSession.conf.get("spark.thrift.desensitization.load.udf.user.whitelist").split(",")
}catch {
case e:Exception => e.printStackTrace() //如果没配置该参数 java.util.NoSuchElementException
}
if(!loadUDFWhitelist.contains(username)){
DesensitizationUDFs.register(ctx,username)
}UDF类:
package org.apache.spark.sql.hive.thriftserver.desensitization
import org.apache.commons.lang.StringUtils
import org.apache.spark.internal.Logging
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.hive.thriftserver.UDFUtil
/**
* Desensitization UDF
* Created by Shmily on 2020/11/23.
*/
object DesensitizationUDFs extends Serializable with Logging{
// private val logger: Logger = LoggerFactory.getLogger(Desensitization.getClass)
/**
* [Irreversible] Hide the mid 4 digits of mobile phone number
* @param phoneNumber
* @return Encrypted phoneNumber
*/
def HideMid4PhoneNumber(phoneNumber:String): String = {
if(phoneNumber==null){
return phoneNumber
}
if(StringUtils.isBlank(phoneNumber)){
return ""
}
phoneNumber.length match {
case 11 => phoneNumber.replaceAll("(\\w{3})\\w*(\\w{4})", "$1****$2")
case 7 => phoneNumber.replaceAll("(\\w{3})\\w*", "$1****")
case _ => phoneNumber
}
}
/**
* [Irreversible] Hide the last 4 digits of mobile phone number
* @param phoneNumber
* @return Encrypted phoneNumber
*/
def HideLast4PhoneNumber(phoneNumber:String): String = {
if(phoneNumber==null){
return phoneNumber
}
if(StringUtils.isBlank(phoneNumber)){
return ""
}
phoneNumber.length match {
case 11 => phoneNumber.replaceAll("(\\w{7})\\w*", "$1****")
case 7 => phoneNumber.replaceAll("(\\w{3})\\w*", "$1****")
case _ => phoneNumber
}
}
/**
* [Irreversible] Keep first char only.
* @param name
* @return Encrypted Name
*/
def HideUserName(name:String): String = {
if(name==null){
return name
}
if(StringUtils.isBlank(name)){
return ""
}
val length = name.length
name.substring(0,1).concat("*" * (length-1))
}
/**
* [Irreversible] ID Card keep 1-6 and last 3 digits.
* @param id
* @return Encrypted id
*/
def HideIDCard(id:String): String = {
if(id==null){
return id
}
if(StringUtils.isBlank(id)){
return ""
}
id.length match {
case 15 => id.replaceAll("(\\w{6})\\w*(\\w{3})", "$1******$2")
case 18 => id.replaceAll("(\\w{6})\\w*(\\w{3})", "$1*********$2")
case _ => id
}
}
/**
* [Irreversible] ID Card keep 1-6 and last 3 digits.
* @param bankCardId
* @return Encrypted bankCardId
*/
def HideBankCardNumber(bankCardId:String): String = {
if(bankCardId==null){
return bankCardId
}
if(StringUtils.isBlank(bankCardId)){
return ""
}
bankCardId.length match {
case 16 => bankCardId.replaceAll("(\\w{6})\\w*(\\w{3})", "$1*******$2")
case 17 => bankCardId.replaceAll("(\\w{6})\\w*(\\w{3})", "$1********$2")
case 19 => bankCardId.replaceAll("(\\w{6})\\w*(\\w{3})", "$1**********$2")
case _ => bankCardId
}
}
/**
* register all desensitization udf
* @param ctx SQLContext
*/
def register(ctx:SQLContext,username:String):Unit = {
logWarning(s"Registering desensitization UDFs for session [user: $username]")
ctx.udf.register("hide_mid_4_phone_number",HideMid4PhoneNumber _)
ctx.udf.register("hide_last_4_phone_number",HideLast4PhoneNumber _)
ctx.udf.register("hide_user_name",HideUserName _)
ctx.udf.register("hide_id_card",HideIDCard _)
ctx.udf.register("hide_bank_card_number",HideBankCardNumber _)
}
}实现启动时加载脱敏配置
org.apache.spark.sql.hive.thriftserver.HiveThriftServer2类,含有ThriftServer的main方法,在启动ThriftServer服务时运行,在DeveloperApi注解下的startWithContext方法添加加载脱敏配置信息的方法loadDesensitizationMeta,保证每次启动ThriftServer生效配置。
@DeveloperApi
def startWithContext(sqlContext: SQLContext): HiveThriftServer2 = {
val executionHive = HiveUtils.newClientForExecution(
sqlContext.sparkContext.conf,
sqlContext.sessionState.newHadoopConf())
DesensitizationModule.loadDesensitizationMeta(sqlContext)
......实现手动刷新脱敏配置
org.apache.spark.sql.hive.thriftserver.server.SparkSQLOperationManager类,用于管理Spark的Operation,其中newExecuteStatementOperation是实际执行statement的方法,在这里判断SQL如果为”refresh_desensitization_auth”则调用loadDesensitizationMeta方法刷新脱敏配置信息
override def newExecuteStatementOperation(
parentSession: HiveSession,
statement: String,
confOverlay: JMap[String, String],
async: Boolean): ExecuteStatementOperation = synchronized {
val sqlContext = sessionToContexts.get(parentSession.getSessionHandle)
Authentication.checkIp(parentSession)
Authentication.checkUser(parentSession)
require(sqlContext != null, s"Session handle: ${parentSession.getSessionHandle} has not been" +
s" initialized or had already closed.")
val conf = sqlContext.sessionState.conf
val hiveSessionState = parentSession.getSessionState
setConfMap(conf, hiveSessionState.getOverriddenConfigurations)
setConfMap(conf, hiveSessionState.getHiveVariables)
val runInBackground = async && conf.getConf(HiveUtils.HIVE_THRIFT_SERVER_ASYNC)
var sql = statement.toLowerCase.trim
var statement2 = statement
if (sql.startsWith("create") && sql.indexOf("options(") != -1) { //remove "\n" when creating external hbase table
statement2 = statement.replaceAll("\n", " ")
}
// load desensitization
if ("refresh_desensitization_auth".equals(sql)) {
if (DesensitizationModule.loadDesensitizationMeta(sqlContext)) { // 这里可以加限制admin权限的用户才能刷新
statement2 = "select 'refresh_desensitization_auth succeed'"
} else {
statement2 = "select 'refresh_desensitization_auth failed'"
}
}
......实现效果
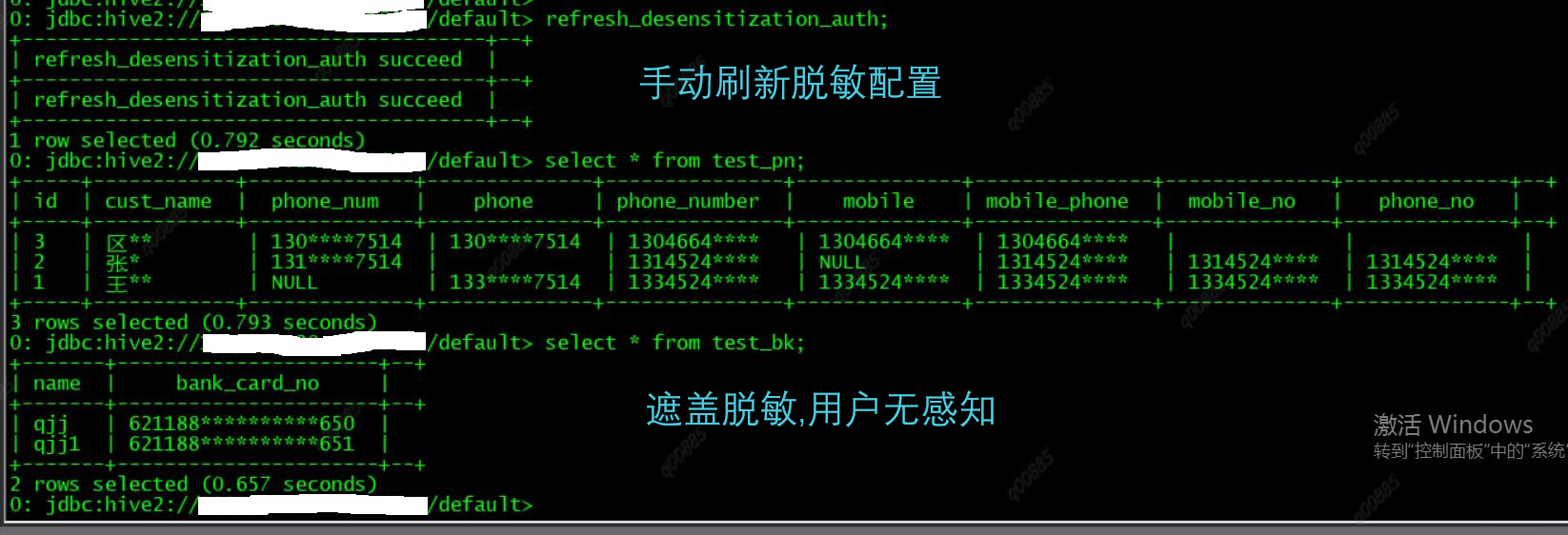
总结
优点:
1.无额外的硬件成本开销
2.性能损耗小
3.用户无感知
4.权限设计灵活
缺点:
1.用户如果用敏感字段关联,结果不准确
2.如果用户将敏感数据创建临时表,且字段名称非通用敏感字段名称,就没办法脱敏了
改进:设置跑批程序,遍历数仓的表,根据数据特征自动发现敏感字段,并自动迭代脱敏配置库
扩展
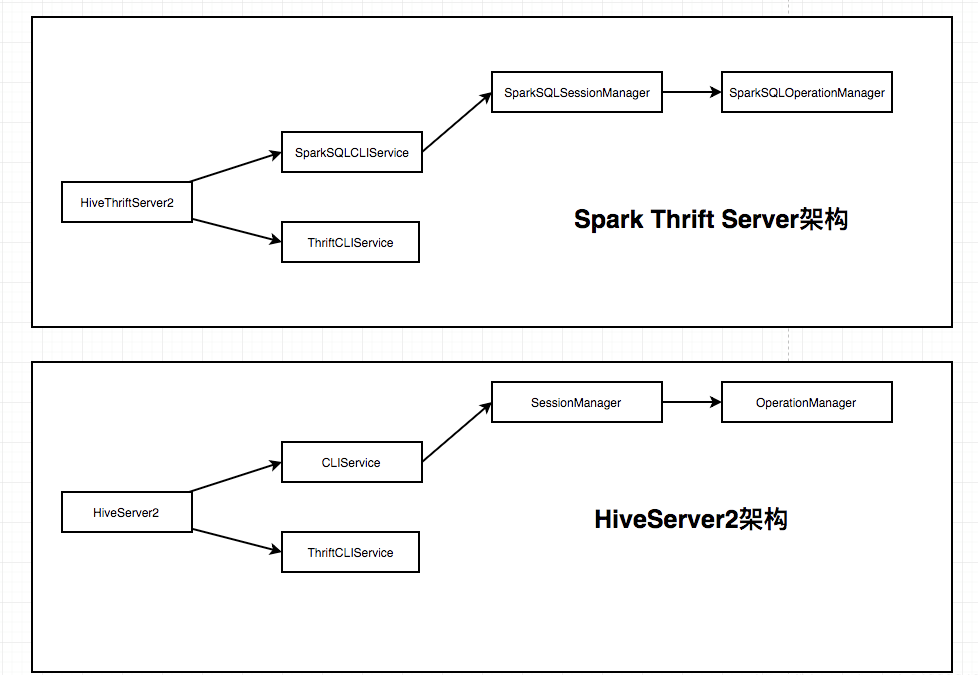
上图是HiveServer2和SparkThriftServer的架构,可以看出两者架构相近。SparkThriftServer大量复用了HiveServer2的代码。
HiveServer2的架构主要是通过ThriftCLIService监听端口,然后获取请求后委托给CLIService处理。CLIService又一层层的委托,最终交给OperationManager处理。OperationManager会根据请求的类型创建一个Operation的具体实现处理。比如Hive中执行sql的Operation实现是SQLOperation。
Spark Thrift Server做的事情就是实现自己的CLIService——SparkSQLCLIService,接着也实现了SparkSQLSessionManager以及SparkSQLOperationManager。另外还实现了一个处理sql的Operation——SparkExecuteStatementOperation。这样,当Spark Thrift Server启动后,对于sql的执行就会最终交给SparkExecuteStatementOperation了。
基于Spark执行计划自定义Rule的数据脱敏
未完待续…
。。。
!!!
???



