







Apache Kudu
前言
在Kudu出现前,由于传统存储系统的局限性,对于数据的快速输入和分析还没有一个完美的解决方案,要么以缓慢的数据输入为代价实现快速分析,要么以缓慢的分析为代价实现数据快速输入。随着快速输入和分析场景越来越多,传统存储层的局限性越来越明显,Kudu应运而生,它的定位介于HDFS和HBase之间,将低延迟随机访问,逐行插入、更新和快速分析扫描融合到一个存储层中,是一个既支持随机读写又支持OLAP分析的存储引擎。本篇文章研究一下Kudu,对其应用场景,架构原理及基本使用做一个总结。
Kudu介绍
在Kudu出现前,无法对实时变化的数据做快速分析:
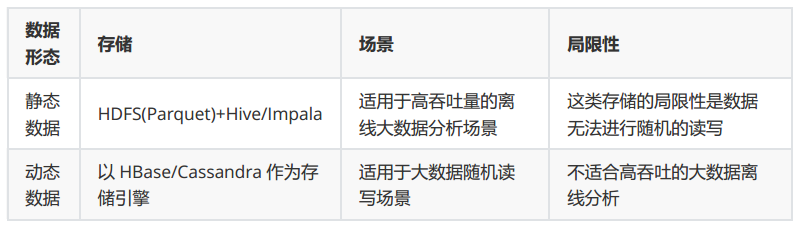
以上设计方案的缺陷:
1.数据存储多份造成冗余,存储资源浪费。
2.架构复杂,运维成本高,排查问题困难。
而Kudu就融合了动态数据与静态数据的处理,同时支持随机读写和OLAP分析。
Kudu与HDFS,HBase的对比:
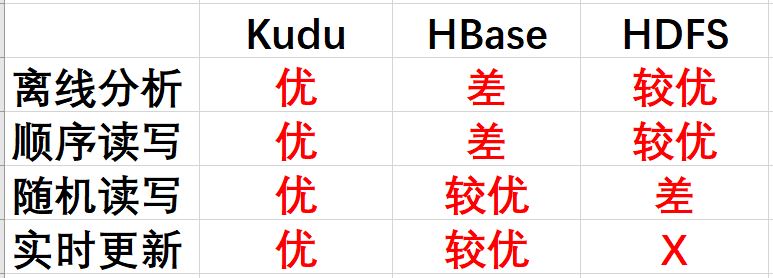
适用场景
- 既有随机读写随机访问,又有批量扫描分析的场景(OLAP)
- HTAP(Hybrid Transactional Analytical Processing)混合事务分析处理场景
- 要求分析结果实时性高(如实时决策,实时更新)的场景
- 实时数仓
- 支持数据逐行插入、更新操作
- 同时高效运行顺序读写和随机读写任务的场景
- Kudu作为持久层与Impala紧密集成的场景
- 解决HBase(Phoenix)大批量数据SQL分析性能不佳的场景
- 跨大量历史数据的查询分析场景(Time-series场景)
特点及缺点
- 特点
- 基于列式存储
- 快速顺序读写
- 使用 LSM树 以支持高效随机读写
- 查询性能和耗时较稳定
- 不依赖Zookeeper
- 有表结构,需要定义Schema,需要定义唯一键,支持SQL分析(依赖Impala,Spark等引擎)
- 支持增删列,单行级ACID(不支持多行事务-不满足原子性)
- 查询时先查询内存再查询磁盘
- 数据存储在Linux文件系统,不依赖HDFS存储
- 缺点
- 暂不支持除PK外的二级索引和唯一性限制
- 不支持多行事务
- 不支持BloomFilter优化join
- 不支持数据回滚
- 不能修改PK,不支持AUTO INCREMENT PK
- 每表最多不能有300列,每个TServer数据压缩后不超8TB
- 数据类型少,不支持Map,ARRAY,Struct等复杂类型
与相似类型存储引擎对比
本文重点说Kudu,但我们也需要了解其他类似组件,了解它们各自擅长的地方,才能更好地做技术选型。这里简单对比一下Kudu,Hudi和DeltaLake这三种存储方案,因为它们都具有相似的特性,能解决类似的问题。
| 特性 | Kudu | Hudi | Delta Lake |
|---|---|---|---|
| 行级别更新 | 支持 | 支持 | 支持 |
| schema修改 | 支持 | 支持 | 支持 |
| 批流共享 | 支持 | 支持 | 支持 |
| 可用索引 | 是 | 是 | 否 |
| 多并发写 | 支持 | 不支持 | 支持 |
| 版本回滚 | 不支持 | 支持 | 支持 |
| 实时性 | 高 | 近实时 | 差 |
| 使用HDFS | 不支持 | 支持 | 支持 |
| 空值处理 | 默认null | error | 默认null |
| 并发读写 | 支持 | 不支持并发写 | 支持 |
| 云存储 | 不支持 | 支持 | 支持 |
| 兼容性 | Spark,Impala,Presto | Spark,Presto,Hive,MR 较好 | 依赖Spark,有限支持Hive,Presto |
选择建议:考虑实时数仓方案以及SQL支持方面可选Kudu,数据湖方案及可回滚可选DeltaLake和Hudi,考虑兼容性高且应对读多写少读少写多都有很好的方案选Hudi,考虑并发写能力读多写少且与Spark紧密结合选DeltaLake。
Kudu架构原理
Raft算法介绍
为了更好地理解Kudu,需要简单了解一下Raft算法。Raft是一个一致性算法,在分布式系统中一致性算法就是让多个节点在网络不稳定甚至部分节点宕机的情况下能对某个事件达成一致。而Raft是一个用于管理日志一致性的协议,它将分布式一致性分解为多个子问题:LeaderElection,LogReplication,Safety,LogCompaction等。
Raft将系统中的角色分为Leader,Follower和Candidate。正常运行时只有Leader和Follower,选举时才会有Candidate。
Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。响应Candidate的邀请投票请求。把客户端请求重定向到Leader。
Candidate:Leader选举过程中的临时角色,由于Follower转变而来。
Leader选举
发生在Follower接收不到Leader的HeartBeat导致ElectionTimeout超时的情况下。
①每个Follower都有一个时钟ElectionTimeout,是个随机值,表示Follower等待成为Leader的时间,谁的时钟先跑完则先发起Leader选举。(收到Leader心跳时会清零ElectionTimeout)
②Follower将其任期(Term)加1然后转为Candidate状态,并且给自己投票,然后携Term_id和日志index给其他节点发起选举(RequestVote RPC)。有三种情况:
①赢得半数以上选票,成为Leader
②收到Leader消息,Leader被抢了,成为Follower
③选举超时时,没有节点赢得多数选票,选举失败,Term_id自增1,进行下一轮选举
③Raft协议所有日志都只能从Leader写入Follower,Leader节点日志只会增加(index+1),不会删除和覆盖。
所以Leader必须包含全部日志,能被选举为Leader的节点一定包含了所有已经提交的日志。
每个节点最多只能给一个候选人投票,先到先服务的原则。
选举胜出规则:节点Term_id越大越新则可能胜出,但可能有Term_id相同的情况,Term_id相同,比较日志Index越大越新则胜出。这一点很像Zookeeper选举的规则。
详细过程:首先会有一个Candidate选自己然后发起投票->Follower收到邀票,如果这个Follower还没给其他节点投票(一个节点只能一票),且对比Term_id比自己大,就把票投给这个Candidate,如果Term_id比自己小且自己还没投票,就拒绝请求,给自己投票。
概括:增加任期编号->给自己投票->重置ElectionTimeout->发送投票RPC给其他节点
日志复制
过程:Leader接收来自客户端的请求并将其以日志的形式复制到集群中的其它节点,并且强制要求其它节点的日志和自己保持一致。
Raft同步日志由编号index、term_id和命令组成。=>有助于选举和根据term持久化
日志永远只有一个流向Leader->Follower
1.日志复制的保证:
1.如果不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的(原因:leader 最多在一个任期里的一个日志索引位置创建一条日志条目,日志条目在日志的位置从来不会改变)。
2.如果不同日志中的两个条目有着相同的索引和任期号,则它们之前的所有条目都是完全一样的(原因:每次 RPC 发送附加日志时,leader 会把这条日志条目的前面的日志的下标和任期号一起发送给 follower,如果 follower 发现和自己的日志不匹配,那么就拒绝接受这条日志,这个称之为一致性检查)。2.网络故障或Leader崩溃时保证一致性:
网络崩溃讲集群分为两拨,没有Leader存在的另一波会重新选主,这时网络恢复,会出现两个Leadr的情况,这是会产生冲突的,这时会根据任期Term_id将任期低的Leader自动降级为Follower,Leader和Follower日志有冲突的时候,Leader将校验Follower最后一条日志是否和Leader匹配,如果不匹配,将递减查询,直到匹配,匹配后,删除冲突的日志。这样就实现了主从日志的一致性。
递减查询,直到匹配,强制覆盖 =>Leader会强制Follower复制它的日志,Leader会从最后的LogIndex从后往前试,直到找到日志一致的index,然后开始复制,覆盖该index之后的日志条目。场景:
发生了网络分区或者网络通信故障,使得Leader不能访问大多数Follwer了,那么Leader只能正常更新它能访问的那些Follower,而大多数的Follower因为没有了Leader,他们重新选出一个Leader,然后这个 Leader来接受客户端的请求,如果客户端要求其添加新的日志,这个新的Leader会通知大多数Follower。如果这时网络故障修复 了,那么原先的Leader就变成Follower,在失联阶段这个老Leader的任何更新都不能算commit,都回滚,接受新的Leader的新的更新(递减查询匹配日志)。
日志压缩
日志不能无限增长,否则会导致重播日志时耗时很长。所以对日志进行压缩,定量Snapshot。
Raft参考:Raft算法详解
Raft算法在Kudu中的应用:多个TMaster之间通过Raft协议实现数据同步和高可用–Raft负责在多个Tablet副本中选出Leader和Follower,Leader Tablet负责发送写入数据给Follower Tablet,大多数副本都完成了写操作则会向客户端确认。
Kudu的一致性模型
相关资料不多,可以一起讨论
Kudu为用户提供了两种一致性模型(snapshot consistency和external consistency)。默认的一致性模型是snapshot consistency。这种一致性模型保证用户每次读取出来的都是一个可用的快照,但这种一致性模型只能保证单个client可以看到最新的数据,但不能保证多个client每次取出的都是最新的数据。另一种一致性模型external consistency(后开始的事务一定可以看到先提交的事务的修改。所有事务的读写都加锁可以解决这个问题,缺点是性能较差。)可以在多个client之间保证每次取到的都是最新数据,但是Kudu没有提供默认的实现,需要用户做一些额外工作。
为了实现external consistency,Kudu提供了两种方式:
1.在client之间传播timestamp token。在一个client完成一次写入后,会得到一个timestamp token,然后这个client把这个token传播到其他client,这样其他client就可以通过token取到最新数据了。不过这个方式的复杂度很高,基于HybridTime方案,这也就是为什么Kudu高度依赖NTP。
2.通过commit-wait方式,这有些类似于Google的Spanner。但是目前基于NTP的commit-wait方式延迟实在有点高。不过Kudu相信,随着[分布式事务实现-Spanner](https://blog.csdn.net/weixin_30650039/article/details/94998723)的出现,未来几年内基于real-time clock的技术将会逐渐成熟。LSM树
LSM树(Log-Structured Merge Tree)
Kudu与HBase在写的过程中都采用了LSM树的结构,LSM树的主要思想就是随机写转换为顺序写来提高写性能,随机读写需要磁盘的机械臂不断寻道,延迟较高,而转换为顺序写后机械臂不会频繁寻址,性能较好。
LSM树原理是把一棵大的树拆分成N棵小树,小树存在于内存中,随着更新和写入操作,小树存放数据达到一定大小后会写入磁盘,小树到了磁盘中,定期与磁盘中的大树做合并。
大家都知道HBase的MemStore,Kudu在写入方面的设计与之类似,Kudu先将对数据的修改保留在内存中,达到一定大小后将这些修改操作批量写入磁盘。但读取的时候稍微麻烦些,需要读取历史数据和内存中最近修改操作。所以写入性能大大提升,而读取时要先去内存读取,如果没命中,则会去磁盘读多个文件。
压缩和编码
我们都知道列式存储的压缩效果很好,那么为什么列式存储比行存储压缩效果好呢?
比如一个列存的国家名,那只能包含“美国”,“日本”,“韩国”,“加拿大”等值,而这些值会存储在一起,而不是分散到包含很多不相关的其他列值之间。这样列式存储也就不需要将每个值都完完整整保存起来,所以压缩效果显著。
编码对于列式存储的优化更加明显,编码和压缩作用相同,比如上面的例子,编码会将数据的值转换为一种更小的表现形式,比如,“美国”编码为1,“日本”编码为2,“韩国”编码为3,“加拿大”编码为4…则Kudu只存储1,2,3,4…而不存储长字符串,占用空间大大减少。
Kudu一些概念

Table:具有Schema和全局有序主键的表。一张表有多个Tablet,多个Tablet包含表的全部数据。
Tablet:Kudu的表Table被水平分割为多段,Tablet是Kudu表的一个片段(分区),每个Tablet存储一段连续范围的数据(会记录开始Key和结束Key),且两个Tablet间不会有重复范围的数据。一个Tablet会复制(逻辑复制而非物理复制,副本中的内容不是实际的数据,而是操作该副本上的数据时对应的更改信息)多个副本在多台TServer上,其中一个副本为Leader Tablet,其他则为Follower Tablet。只有Leader Tablet响应写请求,任何Tablet副本可以响应读请求。
TabletServer:简称TServer,负责数据存储Tablet、提供数据读写服务、编码、压缩、合并和复制。一个TServer可以是某些Tablet的Leader,也可以是某些Tablet的Follower,一个Tablet可以被多个TServer服务(多对多关系)。TServer会定期(默认1s)向Master发送心跳。
Catalog Table:目录表,用户不可直接读取或写入,仅由Master维护,存储两类元数据:表元数据(Schema信息,位置和状态)和Tablet元数据(所有TServer的列表、每个TServer包含哪些Tablet副本、Tablet的开始Key和结束Key)。Catalog Table只存储在Master节点,也是以Tablet的形式,数据量不会很大,只有一个分区,随着Master启动而被全量加载到内存。
Master:负责集群管理和元数据管理。具体:跟踪所有Tablets、TServer、Catalog Table和其他相关的元数据。协调客户端做元数据操作,比如创建一个新表,客户端向Master发起请求,Master写入其WAL并得到其他Master同意后将新表的元数据写入Catalog Table,并协调TServer创建Tablet。
WAL:一个仅支持追加写的预写日志,无论Master还是Tablet都有预写日志,任何对表的修改都会在该表对应的WAL中写入条目(entry),其他副本在数据相对落后时可以通过WAL赶上来。
逻辑复制:Kudu基于Raft协议在集群中对每个Tablet都存储多个副本,副本中的内容不是实际的数据,而是操作该副本上的数据时对应的更改信息。Insert和Update操作会走网络IO,但Delete操作不会,压缩数据也不会走网络。
存储与读写
Kudu的存储结构: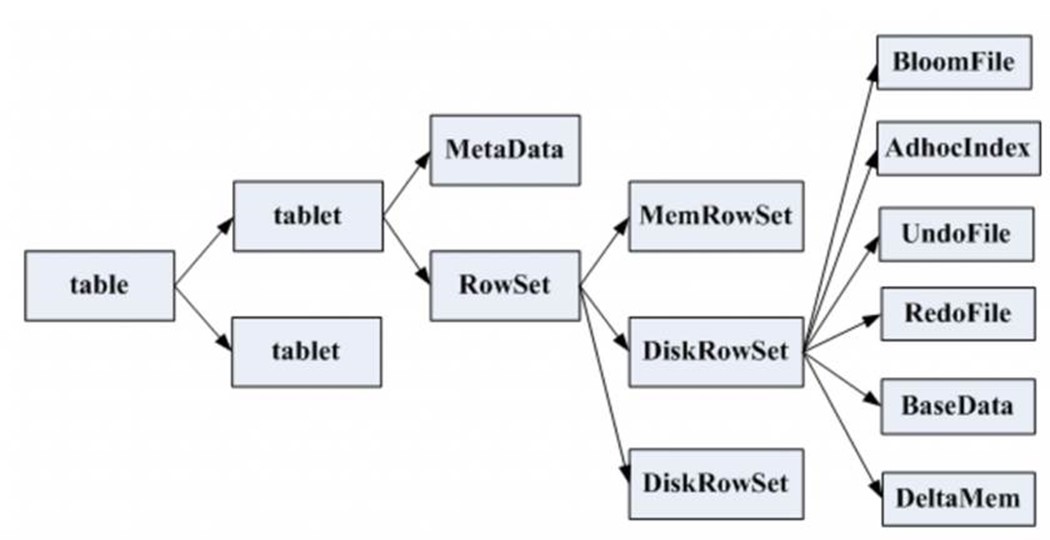
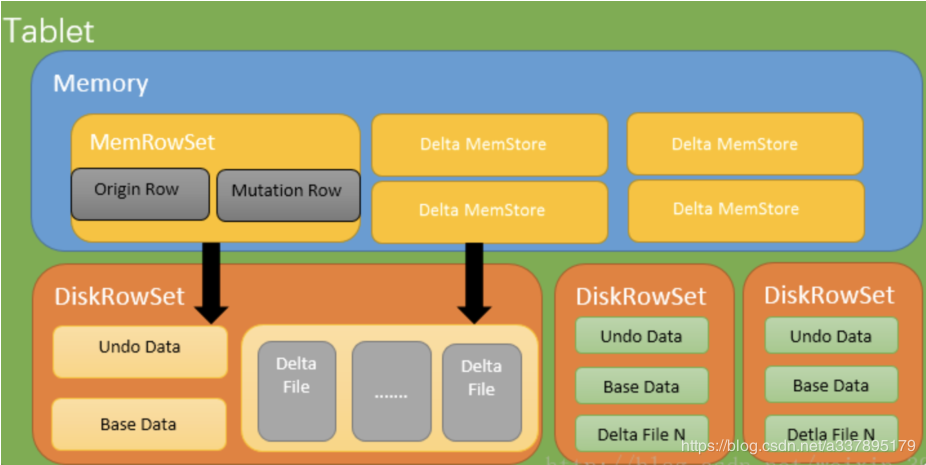
如图,Table分为若干Tablet;Tablet包含Metadata和RowSet,RowSet包含一个MemRowSet及若干个DiskRowSet,DiskRowSet中包含一个BloomFile、AdhocIndex、BaseData、DeltaMem及若干个RedoFile和UndoFile(UndoFile一般情况下只有一个)。
MemRowSet:插入新数据及更新已在MemRowSet中的数据,数据结构是B+树,主键在非叶子节点,数据都在叶子节点。MemRowSet写满后会将数据刷到磁盘形成若干个DiskRowSet。每次达到1G或者120s时生成一个DiskRowSet,DiskRowSet按列存储,类似Parquet。
DiskRowSet:DiskRowSets存储文件格式为CFile。DiskRowSet分为BaseData和DeltaFile。这里每个Column被存储在一个相邻的数据区域,这个数据区域被分为多个小的Page,每个Column Page都可以使用一些Encoding以及Compression算法。后台会定期对DiskRowSet做Compaction,以删除没用的数据及合并历史数据,减少查询过程中的IO开销。
BaseData:DiskRowSet刷写完成的数据,CFile,按列存储,主键有序。BaseData不可变,类似Parquet。
BloomFile:根据一个DiskRowSet中的Key生成一个BloomFilter,用于快速模糊定位某个key是否在DiskRowSet中存在。
AdhocIndex:存放主键的索引,用于定位Key在DiskRowSet中的具体哪个偏移位置。
DeltaMemStore:每份DiskRowSet都对应内存中一个DeltaMemStore,负责记录这个DiskRowSet上BaseData发生后续变更的数据,先写到内存中,写满后Flush到磁盘生成RedoFile。DeltaMemStore的组织方式与MemRowSet相同,也维护一个B+树。
DeltaFile:DeltaMemStore到一定大小会存储到磁盘形成DeltaFile,分为UndoFile和RedoFile。
RedoFile:重做文件,记录上一次Flush生成BaseData之后发生变更数据。DeltaMemStore写满之后,也会刷成CFile,不过与BaseData分开存储,名为RedoFile。UndoFile和RedoFile与关系型数据库中的Undo日子和Redo日志类似。
UndoFile:撤销文件,记录上一次Flush生成BaseData之前时间的历史数据,Kudu通过UndoFile可以读到历史某个时间点的数据。UndoFile一般只有一份。默认UndoFile保存15分钟,Kudu可以查询到15分钟内某列的内容,超过15分钟后会过期,该UndoFile被删除。
DeltaFile(主要是RedoFile)会不断增加,产生大量小文件,不Compaction肯定影响性能,所以就有了下面两种合并方式:
- Minor Compaction:多个DeltaFile进行合并生成一个大的DeltaFile。默认是1000个DeltaFile进行合并一次。
- Major Compaction:RedoFile文件的大小和BaseData的文件的比例为0.1的时候,会将RedoFile合并进入BaseData,Kudu记录所有更新操作并保存为UndoFile。
补充一下:合并和重写BaseData是成本很高的,会产生大量IO操作,Kudu不会将全部DeltaFile合并进BaseData。如果只更新几行数据,但要重写BaseData,费力不讨好,所以Kudu会在某个特定列需要大量更新时再把BaseData与DeltaFile合并。未合并的RedoFile会继续保留等待后续合并操作。
Kudu读流程: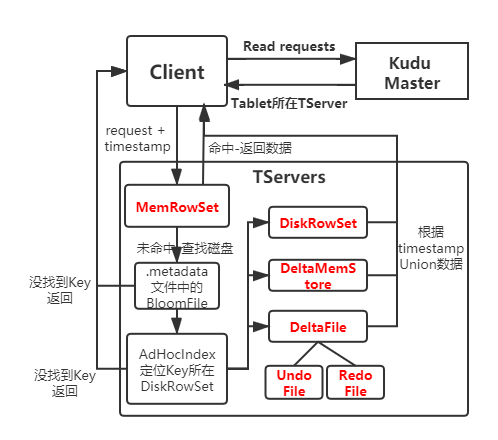
- Client发送读请求,Master根据主键范围确定到包含所需数据的所有Tablet位置和信息。
- Client找到所需Tablet所在TServer,TServer接受读请求。
- 如果要读取的数据位于内存,先从内存(MemRowSet,DeltaMemStore)读取数据,根据读取请求包含的时间戳前提交的更新合并成最终数据。
- 如果要读取的数据位于磁盘(DiskRowSet,DeltaFile),在DeltaFile的UndoFile、RedoFile中找目标数据相关的改动,根据读取请求包含的时间戳合并成最新数据并返回。
Kudu写流程: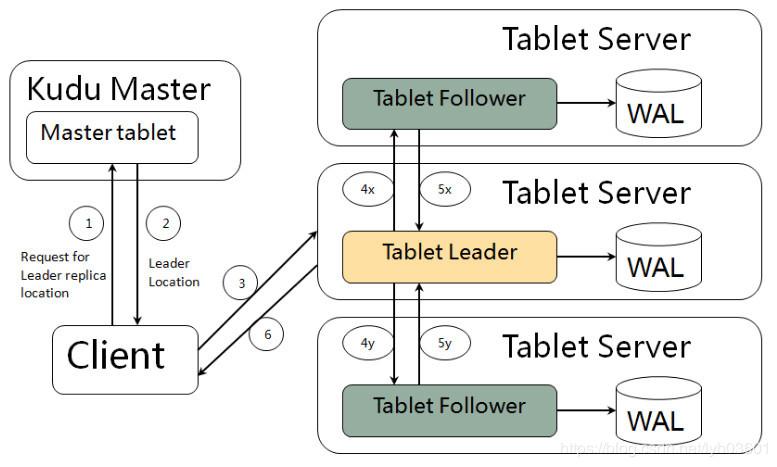
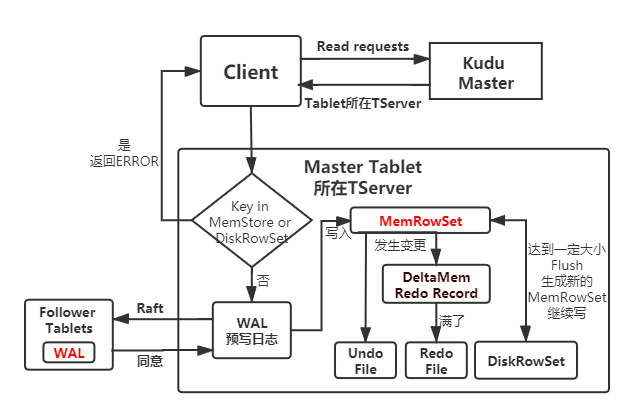
- Client向Master发起写请求,Master找到对应的Tablet元数据信息,检查请求数据是否符合表结构。
- 因为Kudu不允许有主键重复的记录,所以需要判断主键是否已经存在,先查询主键范围,如果不在范围内则准备写MemRowSet。
- 如果在主键范围内,先通过主键Key的布隆过滤器快速模糊查找,未命中则准备写MemRowSet。
- 如果BloomFilter命中,则查询索引,如果没命中索引则准备写MemRowSet,如果命中了主键索引就报错:主键重复。
- 写入MemRowSet前先被提交到一个Tablet的WAL预写日志,并根据Raft一致性算法取得Follower Tablets的同意,然后才会被写入到其中一个Tablet的MemRowSet中。为了在MemRowSet中支持多版本并发控制(MVCC),对最近插入的行(即尚未刷新到磁盘的新的行)的更新和删除操作将被追加到MemRowSet中的原始行之后以生成重做(REDO)记录的列表。
- MemRowSet写满后,Kudu将数据每行相邻的列分为不同的区间,每个列为一个区间,Flush到DiskRowSet。
Kudu更新流程:
- Client发送更新请求,Master获取表的相关信息,表的所有Tablet信息。
- Kudu检查是否符合表结构。
- 如果需要更新的数据在MemRowSet,B+树找到待更新数据所在叶子节点,然后将更新操作记录在所在行中一个Mutation链表中;Kudu采用了MVCC(多版本并发控制,实现读和写的并行,任何写都是插入)思想,将更改的数据以链表形式追加到叶子节点后面,避免在树上进行更新和删除操作。
- 如果需要更新的数据在DiskRowSet,找到其所在的DiskRowSet,前面提到每个DiskRowSet都会在内存中有一个DeltaMemStore,将更新操作记录在DeltaMemStore,达到一定大小才会生成DeltaFile到磁盘。
分区方式
Kudu的分区即为Tablet,如果主键设计不好以及分区不合理都会造成数据发生单点读写问题,也就是热点问题。Kudu分区设计方案需要根据场景和读取写入的方式来制定。最好是将读写操作都能分散到大部分节点。
在Kudu中只有主键才能被用来分区。
分区模式有三种:
- 基于Hash分区(Hash Partitioning):
哈希分区通过哈希值将行分配到许多Buckets(存储桶)之一,一个Bucket对应一个Tablet。
优点:按ID哈希分区可以将数据均匀分布,写操作会分布在多个节点,减轻热点和Tablet大小不均匀问题。也就是基于ID哈希分区写效率高
缺点:按ID查询数据会读取单个Tablet(Bucket),单点读取效率低。 - 基于Range分区(Range Partitioning):
由PK范围划分组成,一个区间对应一个Tablet。将数据按给定的主键范围的存储到各个TS节点上。
优点:如果按日期范围分区,单个ID的读取会跨多个节点并行执行,效率高。也就是基于时间范围分区查询效率高。
缺点:如果按日期范围分区会有写热点问题,而且一旦数据量超出最后一个Range,接下来的数据将全部写入最后一个Range分区,发生倾斜。 - 多级分区(Multilevel Partitioning):**可以在单表上组合分区类型。
优点:结合以上两种分区方式,保留两种分区类型的优点–既可以数据分布均匀,又可以在每个分片中保留指定的数据。也就是基于ID哈希分区且基于时间范围分区组合方式读写效率都会提高**
缺点:优点太多…
复制策略
如果一个TServer出现故障,副本的数量由3减到2个,Kudu会尽快恢复副本数。两种复制策略:
3-4-3:如果一个副本丢失,先添加替换的副本,再删除失败的副本,Kudu默认使用这种复制策略。
3-2-3:如果一个副本丢失,先删除失败的副本,再添加替换的副本。
一些细节
- 为什么Kudu要比HBase、Cassandra扫描速度更快?
HBase、Cassandra都有列簇(CF),并不是纯正的列存储,那么一个列簇中有几个列,但这几个列不能一起编码,压缩效果相对不好,而且在扫描其中一个列的数据时,必然会扫描同一列簇中的其他列。Kudu没有列簇的概念,它的不同列数据都在相邻的数据区域,可以在一起压缩,也可以对不同列使用不同压缩算法,压缩效果很好;而且需要哪列读哪列不会读其他列,读取时不需要进行Merge操作,根据BaseData和Delta数据得到最终数据。Kudu扫描性能可媲美Parquet。还有,Kudu的读取方式避免了很多字段的比较操作,CPU利用率高。 - Kudu一个Tablet中存很多很多DiskRowSet,怎么才能快速判断Key在哪个DiskRowSet?
首先肯定不能遍历,O(n)的复杂度是很难受的。它使用二叉查找树,每个节点维护多个DiskRowSet的最大Key和最小Key,这样就可在O(logn)时间内定位Key所在DiskRowSet。 - Kudu不同的列类型不同,使用的编码和压缩方式?
Kudu每列都有类型,编码方式和压缩方式,编码方式根据数据类型不同有合适的默认值,压缩方式默认不压缩。
Kudu的部署
Kudu有两种进程Master和TServer,Kudu服务是可以单独部署在集群的,但大多数情况可能是与Hadoop集群共置,不同的环境需要不同的部署方案,本节用数据化运营的思想来说Kudu服务的部署。
Master部署
Master高可用,一般配置3或5个Master来保证HA,同一时刻只有一个Master工作,半数以上Master存活,服务都可正常运行。Master之间需要达成共识,大多数Master“投票”得到Leader,其他的为Follower。如果该Master出现问题,也是通过Raft一致性算法来做选举,既容错又高效。
一般配置3或5个Master,7个就有点多了没必要。Master数目必须为奇数个。给定一组需要写N个副本(一般为3或5)的Tablet,可以接受(N-1)/2个写入错误。
由于Mater中只保存元数据,数据量会一直比较小,即使被频繁请求,被全量加载到内存,也不需要占用大量系统资源。
TServer部署
根据业务量,了解大概要存储多少数据。因为Kudu列式存储与Parquet相似,可以根据相同数据量Parquet占用磁盘大小来粗略估计需要多少存储空间。
TServer数量和配置大致给多少呢?
假设:
Parquet格式存储的数据集大小60TB
每个TServer数据磁盘最大8T
给数据磁盘预留25%的磁盘空间
Tablet冗余副本3
TServer数量 = (Parquet格式存储的数据集大小 * 冗余数) / (TS磁盘容量 * ( 1 - 磁盘预留))
TServer数量 = (60 * 3) / (8 * (1 - 0.25)) = 30存储介质
在CM部署Master和TServer时,我们可以看到如下配置: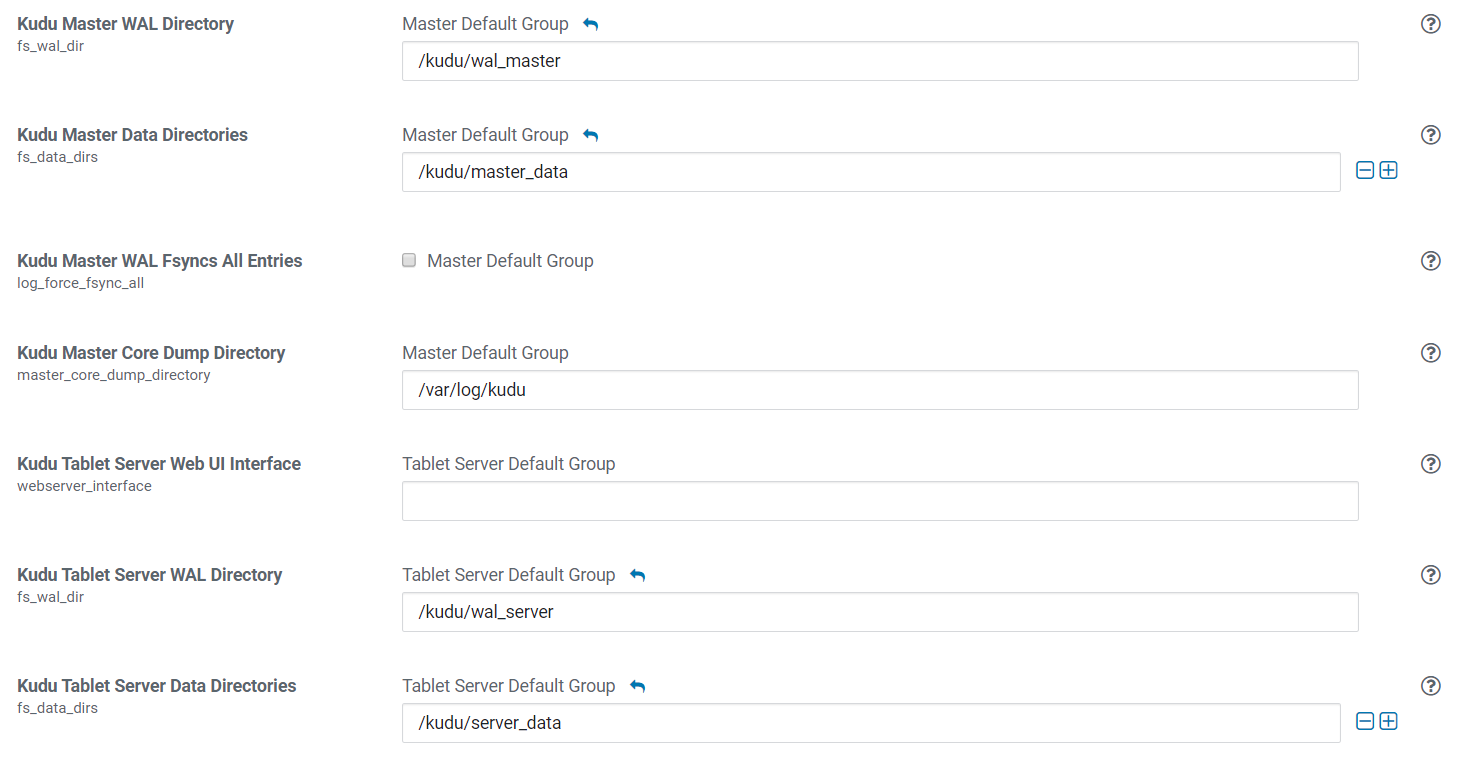

Kudu设计时就对数据和WAL分开存储的,为什么呢?
之前说过WAL仅支持追加写,单个操作乍一看会顺序写WAL,但同时执行多个任务时,更像是随机写WAL,这就很考验WAL底层存储的IOPS(IO Per Second)了。传统机械盘IOPS也就几百,而NVMe-SSD的IOPS能达到万级甚至百万级,所以Kudu WAL尽量存储在SSD中。
那WAL的SSD盘大概要选多大呢?
Kudu的WAL日志是可以控制大小,日志段数量的。
默认日志段大小8M,数量1-80个,按默认的8M,80个算,如果共2000个Tablet,需要WAL的SSD大小:
8 * 80 * 2000 = 1280000MB 约1.3TBTablet的数据可以用机械盘HDD来存储(SSD更好),可以与DataNode处于同一块磁盘,这样更方便管理,因为这样可以充分利用磁盘负载和磁盘空间,不至于一个盘爆满另一个盘空余很多。
Kudu使用
环境:
四台机器CDH6.3.1集群,6核心12线程,内存分别为:20GB,14GB,14GB和10GB。
**OS:**CentOS7;**Impala:**3.2.0-cdh6.3.1;**Kudu:**1.10.0-cdh6.3.1(3Master+3TServer);**Hive:**2.1.1-cdh6.3.1;
依次启动HDFS、hive、Kudu、Impala。
Kudu + Impala
Impala定位是一款实时查询引擎(低延时SQL交互查询),快的原因:基于内存计算,无需MR,C++编写,兼容HiveQL和支持数据本地化。这与Kudu场景相吻合,Kudu官网也说Impala和Kudu可以无缝整合。
进入Impala配置,Kudu服务处勾选Kudu即可。
注意:=, <=, ‘<‘, ‘>‘, >=, BETWEEN, IN等操作会从Impala谓词下推到Kudu,性能高。而!=, like和其他Impala关键字会让Kudu返回所有结果再让Impala过滤,效率低下。因为Kudu没二级索引,所以没有主键的谓词也会造成全表扫描。
1.使用Impala创建Hash分区的Kudu表
impala-shell -i cdh102:21000 -- Impala Daemon在cdh102机器
CREATE DATABASE IF NOT EXISTS impala_kudu;
-- 建内部表,Impala发生drop操作会删除Kudu上对应数据
CREATE TABLE impala_kudu.first_kudu_table(
id INT,
name String,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 8 -- 使用Hash分区
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'cdh102:7051,cdh103:7051,cdh104:7051'
);
-- 查看Kudu中已能看到刚创建的表
kudu table list cdh102:7051,cdh103:7051,cdh104:7051
-- 查看表以及tablets
kudu table list cdh102:7051,cdh103:7051,cdh104:7051 --list_tablets在WebUI上可以看到该表对应8个Tablet以及每个Tablet信息。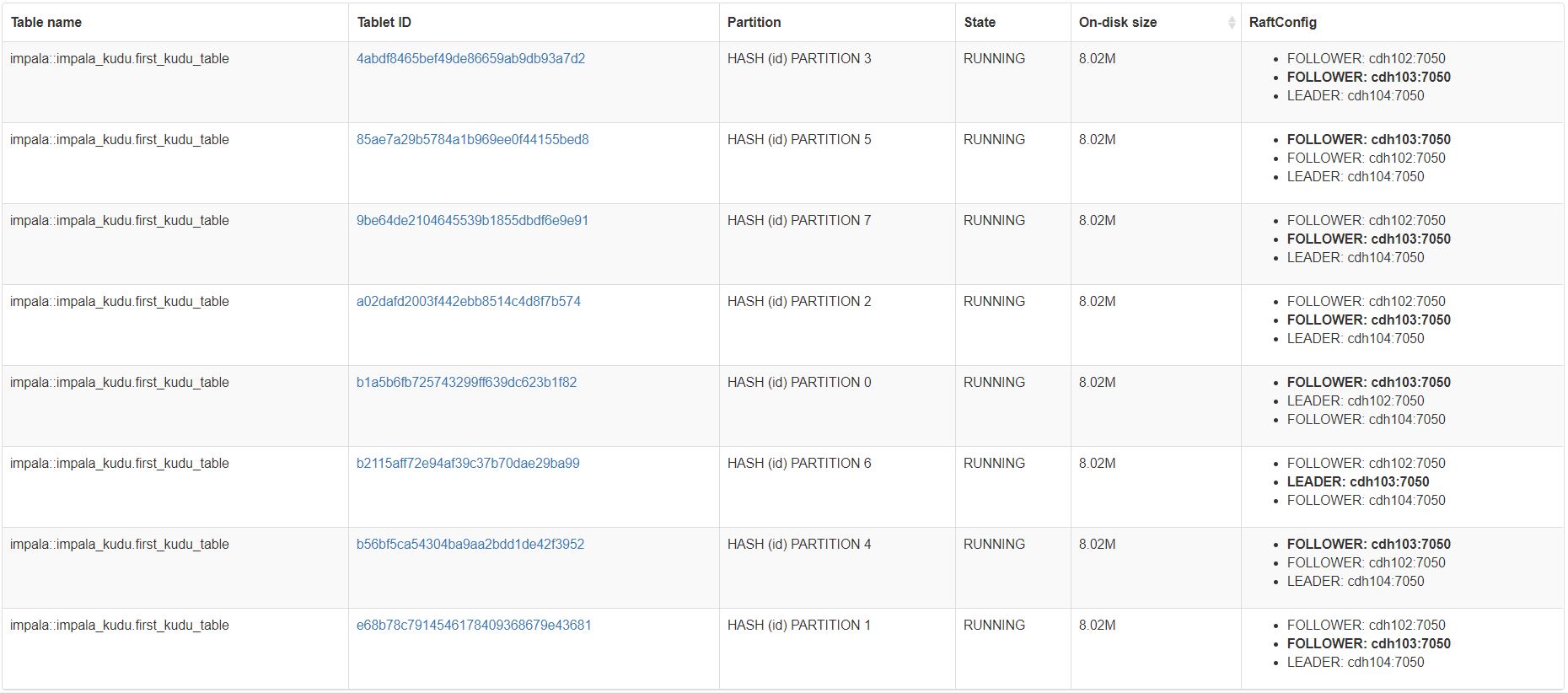
2.使用Impala创建RANGE分区的Kudu表
impala-shell -i cdh102:21000 -- Impala Daemon在cdh102机器
CREATE TABLE impala_kudu.second_kudu_table(
id INT,
name String,
PRIMARY KEY(id)
)
PARTITION BY RANGE (id) ( -- 使用Range分区 只有主键可以做RANGE分区的字段
PARTITION 0 <= values <= 3, -- 如果id范围取多个值,则为values,如果分区字段按是单个值,则为value
PARTITION 4 <= values <= 7,
PARTITION 8 <= values <= 11,
PARTITION 11 < values
)
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'cdh102:7051,cdh103:7051,cdh104:7051'
);
-- ------------------------------------------------------------------------------------
CREATE TABLE impala_kudu.third_kudu_table(
state STRING,
name String,
PRIMARY KEY(state,name)
)
PARTITION BY RANGE (state) ( -- 联合主键时,RANGE分区可以使用其中一个字段
PARTITION value = 'succeed', -- 如果分区字段按是单个值,则为value
PARTITION value = 'queued',
PARTITION value = 'waiting',
PARTITION value = 'failed'
)
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'cdh102:7051,cdh103:7051,cdh104:7051'
);3.使用Impala创建混合分区的Kudu表
impala-shell -i cdh102:21000 -- Impala Daemon在cdh102机器
CREATE TABLE impala_kudu.fourth_kudu_table(
id INT,
state String,
name String,
PRIMARY KEY(id,state)
) PARTITION BY HASH (id) PARTITIONS 4, -- 混合分区 HASH+RANGE
RANGE (state) (
PARTITION value = 'succeed',
PARTITION value = 'queued',
PARTITION value = 'waiting',
PARTITION value = 'failed' -- 最终Tablet数为HASH分区数乘以RANGE分区数
)
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'cdh102:7051,cdh103:7051,cdh104:7051'
);4.在Impala映射已经存在的Kudu表
[kudu@cdh102 /]# kudu table list cdh102:7051,cdh103:7051,cdh104:7051
impala::impala_kudu.first_kudu_table
impala::impala_kudu.test
impala::impala_kudu.second_kudu_table
impala::impala_kudu.fourth_kudu_table
impala::impala_kudu.third_kudu_table
CREATE EXTERNAL TABLE impala_kudu.fifth_kudu_table
STORED AS KUDU -- Kudu表映射到Impala中,不能指定字段,主键和分区方式,由Kudu决定
TBLPROPERTIES (
'kudu.master_addresses' = 'cdh102:7051,cdh103:7051,cdh104:7051',
'kudu.table_name' = 'impala::impala_kudu.first_kudu_table'
);
drop table impala_kudu.fifth_kudu_table; -- 删除不会对Kudu中表有影响5.转储一张Hive表到Kudu
show create table default.test;
CREATE TABLE impala_kudu.test(
id INT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 2 -- 数据量少,分2个桶
STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'cdh102:7051,cdh103:7051,cdh104:7051'
);
INSERT INTO impala_kudu.test SELECT * FROM default.test;
SELECT * FROM impala_kudu.test; -- 这时会发现数据顺序发生变化了,因为Hash分区的原因6.Kudu表备份到Hive
实测在数据量不大 百G级别 使用Impala实现Kudu数据全量同步Hive,不会对Kudu服务造成影响
CREATE TABLE default.impala_kudu_test LIKE impala_kudu.test;
INSERT INTO default.impala_kudu_test SELECT * FROM impala_kudu.test;在官网了解更多:Using Apache Kudu with Apache Impala
Kudu + Spark
<!-- scala.bin.version: 2.12, kudu.version: 1.10.0 -->
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_${scala.bin.version}</artifactId>
<version>${kudu.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2-tools_${scala.bin.version}</artifactId>
<version>${kudu.version}</version>
</dependency>Spark连接并操作Kudu表
import org.apache.kudu.client._
import collection.JavaConverters._
// Read a table from Kudu
val df = spark.read
.options(Map("kudu.master" -> "kudu.master:7051", "kudu.table" -> "kudu_table"))
.format("kudu").load
// Query using the Spark API...
df.select("id").filter("id >= 5").show()
// ...or register a temporary table and use SQL
df.createOrReplaceTempView("kudu_table")
val filteredDF = spark.sql("select id from kudu_table where id >= 5").show()
// Use KuduContext to create, delete, or write to Kudu tables
val kuduContext = new KuduContext("kudu.master:7051", spark.sparkContext)
// Create a new Kudu table from a DataFrame schema
// NB: No rows from the DataFrame are inserted into the table
kuduContext.createTable(
"test_table", df.schema, Seq("key"),
new CreateTableOptions()
.setNumReplicas(1)
.addHashPartitions(List("key").asJava, 3))
// Insert data
kuduContext.insertRows(df, "test_table")
// Delete data
kuduContext.deleteRows(filteredDF, "test_table")
// Upsert data
kuduContext.upsertRows(df, "test_table")
// Update data
val alteredDF = df.select("id", $"count" + 1)
kuduContext.updateRows(filteredRows, "test_table")
// Data can also be inserted into the Kudu table using the data source, though the methods on
// KuduContext are preferred
// NB: The default is to upsert rows; to perform standard inserts instead, set operation = insert
// in the options map
// NB: Only mode Append is supported
df.write
.options(Map("kudu.master"-> "kudu.master:7051", "kudu.table"-> "test_table"))
.mode("append")
.format("kudu").save
// Check for the existence of a Kudu table
kuduContext.tableExists("another_table")
// Delete a Kudu table
kuduContext.deleteTable("unwanted_table")Kudu + Hive
与Hive MetaStore集成
官网写的很详细。
在官网了解更多:Using the Hive Metastore with Kudu
Kudu APIs
Kudu常用Command Lines
Kudu客户端命令
kudu cluster ksck master1,master2,master3 查看表及表状态 HEALTHY正常 UNDER_REPLICATED缺失副本但不影响使用 UNAVAILABLE表无法使用
kudu cluster rebalance master1,master2,master3 -max_moves_per_server 3 -max_run_time_sec 10 Kudu数据重平衡避免热点TS,TS的service_queue被占满、内存占用过大Kudu有很多命令,大致分几类:
su - kudu
kudu cluster 集群管理,包括健康状态检查,移动tablet,rebalance等操作
kudu diagnose 集群诊断工具
kudu fs 在本地Kudu文件系统做操作,检查一致性,列出元顺据,数据集更新,数据转储
kudu hms 操作HiveMetaStore,包括检查与Kudu元数据一致性,自动修复元数据,列出元数据
kudu local_replica 操作本地副本,包括从远程copy副本过来,获取空间占用情况,删除Tablet,获取副本列表,转储本地副本等
kudu master 操作KuduMaster,可以运行master,获取master状态,时间戳,flag等信息,
kudu pbc protobuf容器文件操作
kudu perf 集群性能测试,运行负载,显示本地Tablet行数等
kudu remote_replica 操作远程TServer上的副本,远程复制,删除,转储,列出Tablet
kudu table 操作Kudu表,包括添加范围分区,设置blockSize,设置列的压缩类型,编码类型,默认值,注释,复制表数据到另一表,建表,删除列,删表,描述表,删除范围的分区,获取和更改表其他配置,列出表,找到Row所在Tablet,列重命名,表重命名,scan,获取表的统计信息
kudu tablet 操作Kudu的Tablet 包括更换Tablet的Leader,Raft配置
kudu test 测试
kudu tserver 操作TabletServer包括运行,设置Flag,获取状态,时间戳,列出TServers等
kudu wal 操作Kudu WAL,转储WAL日志文件Kudu常用Java API:
Maven Dep:
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.10.0</version>
</dependency>
//KuduDDL.java Kudu数据定义API包括:建表,删表,增加字段和删除字段
package top.qjj.shmily.operations;
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Schema;
import org.apache.kudu.Type;
import org.apache.kudu.client.*;
import org.apache.kudu.shaded.com.google.common.collect.ImmutableList;
import java.util.LinkedList;
public class KuduDDL{
public static void main(String[] args) {
String kuduMasterAddrs = "cdh102,cdh103,cdh104";
KuduDDLOperations kuduDDLOperations = KuduDDLOperations.getInstance(kuduMasterAddrs);
//创建Kudu表
String tableName = "kudu_table_with_hash";
//1.Schema指定
LinkedList<ColumnSchema> schemaList = new LinkedList<>();
schemaList.add(kuduDDLOperations.newColumn("id", Type.INT32, true));
schemaList.add(kuduDDLOperations.newColumn("name", Type.STRING, false));
Schema schema = new Schema(schemaList);
//2.设置建表参数-哈希分区
// CreateTableOptions options = new CreateTableOptions();
// options.setNumReplicas(1); //设置存储副本数-必须为奇数否则会抛异常
// List<String> hashKey = new LinkedList<String>();
// hashKey.add("id");
// options.addHashPartitions(hashKey,2); //哈希分区 设置哈希键和桶数
//2.设置建表参数-Range分区
CreateTableOptions options = new CreateTableOptions();
options.setRangePartitionColumns(ImmutableList.of("id")); //设置id为Range key
int temp = 0;
for(int i = 0; i < 10; i++){ //id 每10一个区间直到100
PartialRow lowLevel = schema.newPartialRow(); //定义用来分区的列
lowLevel.addInt("id", temp); //与字段类型对应 INT32则addInt INT64则addLong
PartialRow highLevel = schema.newPartialRow();
temp += 10;
highLevel.addInt("id", temp);
options.addRangePartition(lowLevel, highLevel);
}
//3.开始建表
boolean result = kuduDDLOperations.createTable(tableName, schema, options);
System.out.println(result);
//添加字段
kuduDDLOperations.addColumn(tableName, "test", Type.INT8);
//删除字段
kuduDDLOperations.deleteColumn(tableName, "test");
//删除Kudu表
boolean delResult = kuduDDLOperations.dropTable(tableName);
System.out.println(delResult);
//关闭连接
kuduDDLOperations.closeConnection();
}
}
class KuduDDLOperations {
private static volatile KuduDDLOperations instance;
private KuduClient kuduClient = null;
private KuduDDLOperations(String masterAddr){
kuduClient = new KuduClient.KuduClientBuilder(masterAddr).defaultOperationTimeoutMs(6000).build();
}
public static KuduDDLOperations getInstance(String masterAddr){
if(instance == null){
synchronized (KuduDDLOperations.class){
if(instance == null){
instance = new KuduDDLOperations(masterAddr);
}
}
}
return instance;
}
public void closeConnection(){
try {
kuduClient.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public ColumnSchema newColumn(String name, Type type, boolean isKey){
ColumnSchema.ColumnSchemaBuilder column = new ColumnSchema.ColumnSchemaBuilder(name, type);
column.key(isKey);
return column.build();
}
/**
* 创建表
* 注意:Impala DDL对表字段名大小写不敏感,但Kudu层已经转为小写,且Kudu API中字段名必须小写;
* 注意:Impala DDL建表表名大小写敏感且到Kudu层表名不会被转成小写,且Kudu API对表名大小写敏感。
* @param tableName 表名
* @param schema Schema信息
* @param tableOptions 建表参数 TableOptions对象
* @return boolean
*/
public boolean createTable(String tableName, Schema schema, CreateTableOptions tableOptions){
try {
kuduClient.createTable(tableName, schema, tableOptions);
System.out.println("Create table successfully!");
return true;
} catch (KuduException e) {
e.printStackTrace();
}
return false;
}
/**
* 删库跑路
* @param tableName 要删的表名
* @return boolean 是否需要跑路
*/
public boolean dropTable(String tableName){
try {
kuduClient.deleteTable(tableName);
System.out.println("Drop table successfully!");
return true;
} catch (KuduException e) {
e.printStackTrace();
}
return false;
}
/**
* 给Kudu表添加字段
* @param tableName 表名
* @param column 字段名
* @param type 类型
* @return
*/
public boolean addColumn(String tableName, String column, Type type) {
AlterTableOptions alterTableOptions = new AlterTableOptions();
alterTableOptions.addColumn(new ColumnSchema.ColumnSchemaBuilder(column, type).nullable(true).build());
try {
kuduClient.alterTable(tableName, alterTableOptions);
System.out.println("成功添加字段" + column + "到表" + tableName);
return true;
} catch (KuduException e) {
e.printStackTrace();
}
return false;
}
/**
* 删除Kudu表指定字段
* @param tableName 表名
* @param column 字段名
* @return
*/
public boolean deleteColumn(String tableName, String column){
AlterTableOptions alterTableOptions = new AlterTableOptions().dropColumn(column);
try {
kuduClient.alterTable(tableName, alterTableOptions);
System.out.println("成功删除表" + tableName + "的字段" + column);
return true;
} catch (KuduException e) {
e.printStackTrace();
}
return false;
}
}
// -------------------------------------------------------------------------------------------------------------
//KuduDML.java Kudu数据操作API包括:CRUD
package top.qjj.shmily.operations;
import org.apache.kudu.client.SessionConfiguration.FlushMode;
import org.apache.kudu.client.*;
public class KuduDML {
public static void main(String[] args) {
String masterAddr = "cdh102,cdh103,cdh104";
KuduDMLOperations kuduDMLOperations = KuduDMLOperations.getInstance(masterAddr);
//插入数据
kuduDMLOperations.insertRows();
//更新一条数据
kuduDMLOperations.updateRow();
//删除一条数据
kuduDMLOperations.deleteRow();
//查询数据
kuduDMLOperations.selectRows();
//关闭Client连接
kuduDMLOperations.closeConnection();
}
}
class KuduDMLOperations {
private static volatile KuduDMLOperations instance;
private KuduClient kuduClient = null;
private KuduDMLOperations(String masterAddr){
kuduClient = new KuduClient.KuduClientBuilder(masterAddr).defaultOperationTimeoutMs(6000).build();
}
public static KuduDMLOperations getInstance(String masterAddr){
if(instance == null){
synchronized (KuduDMLOperations.class){
if(instance == null){
instance = new KuduDMLOperations(masterAddr);
}
}
}
return instance;
}
public void closeConnection() {
try {
kuduClient.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
/**
* 以kudu_table_with_hash表(id INT,name STRING)为例 插入数据
* 注意:写数据时数据不支持为null,需要对进来的数据判空
*/
public void insertRows(){
try {
KuduTable table = kuduClient.openTable("kudu_table_with_hash"); //打开表
KuduSession kuduSession = kuduClient.newSession(); //创建会话Session
kuduSession.setFlushMode(FlushMode.MANUAL_FLUSH); //设置数据提交方式
/**
* 1.AUTO_FLUSH_SYNC(默认) 目前比较慢
* 2.AUTO_FLUSH_BACKGROUND 目前有BUG
* 3.MANUAL_FLUSH 目前效率最高 远远高于其他
* 关于这三个参数测试调优可看这篇:https://www.cnblogs.com/harrychinese/p/kudu_java_api.html
*/
int numOps = 3000;
kuduSession.setMutationBufferSpace(numOps); //设置MANUAL_FLUSH需要设置缓冲区操作次数限制 如果超限会抛异常
int nowOps = 0; //记录当前操作数
for(int i = 0; i <= 100; i++){
Insert insert = table.newInsert();
//字段数据
insert.getRow().addInt("id", i);
insert.getRow().addString("name", "小"+i);
nowOps += 1;
if(nowOps == numOps / 2){ //所以缓冲区操作次数达到一半时进行flush提交数据,避免抛异常
kuduSession.flush(); //提交数据
nowOps = 0; //计数器归零
}
kuduSession.apply(insert);
}
kuduSession.flush(); //保证最后都提交上去了
kuduSession.close();
System.out.println("数据成功写入Kudu表");
} catch (KuduException e) {
e.printStackTrace();
System.out.println("数据写入失败,原因:" + e.getMessage());
}
}
/**
* 以kudu_table_with_hash表(id INT,name STRING)为例 查询数据
*/
public void selectRows(){
try {
KuduTable table = kuduClient.openTable("kudu_table_with_hash"); // 打开表
KuduScanner scanner = kuduClient.newScannerBuilder(table).build(); //创建Scanner
while (scanner.hasMoreRows()){
for (RowResult r: scanner.nextRows()) {
System.out.println(r.getInt("id") + " - " + r.getString(1));
}
}
scanner.close();
} catch (KuduException e) {
e.printStackTrace();
System.out.println("查询失败,原因:" + e.getMessage());
}
}
/**
* 以kudu_table_with_hash表(id INT,name STRING)为例 更新一条数据
*/
public void updateRow(){
try {
KuduTable table = kuduClient.openTable("kudu_table_with_hash");
KuduSession session = kuduClient.newSession();
session.setFlushMode(FlushMode.AUTO_FLUSH_SYNC);
Update update = table.newUpdate();
PartialRow row = update.getRow(); //定义用来分区的列
row.addInt("id", 66);
row.addString("name", "qjj");
session.apply(update);
session.close();
} catch (KuduException e) {
e.printStackTrace();
System.out.println("数据更新失败,原因:" + e.getMessage());
}
}
/**
* 以kudu_table_with_hash表(id INT,name STRING)为例 删除一条数据
*/
public void deleteRow(){
try {
KuduTable table = kuduClient.openTable("kudu_table_with_hash");
KuduSession session = kuduClient.newSession();
Delete delete = table.newDelete();
delete.getRow().addInt("id",18); //根据主键唯一删除一条记录
session.flush();
session.apply(delete);
session.close();
} catch (KuduException e) {
e.printStackTrace();
System.out.println("数据删除失败,原因:" + e.getMessage());
}
}
}Kudu常用Python API:
import kudu
from kudu.client import Partitioning
from datetime import datetime
# Connect to Kudu master server
client = kudu.connect(host='cdh102,cdh103,cdh104', port=7051)
# Define a schema for a new table
builder = kudu.schema_builder()
builder.add_column('key').type(kudu.int64).nullable(False).primary_key()
builder.add_column('ts_val', type_=kudu.unixtime_micros, nullable=False, compression='lz4')
schema = builder.build()
# Define partitioning schema
partitioning = Partitioning().add_hash_partitions(column_names=['key'], num_buckets=3)
# Create new table
client.create_table('python-example', schema, partitioning)
# Open a table
table = client.table('python_example')
# Create a new session so that we can apply write operations
session = client.new_session()
# Insert a row
op = table.new_insert({'key': 1, 'ts_val': datetime.utcnow()})
session.apply(op)
# Upsert a row
op = table.new_upsert({'key': 2, 'ts_val': "2020-01-01T00:00:00.000000"})
session.apply(op)
# Updating a row
op = table.new_update({'key': 1, 'ts_val': ("2020-07-12", "%Y-%m-%d")})
session.apply(op)
# Delete a row
op = table.new_delete({'key': 2})
session.apply(op)
# Flush write operations, if failures occur, capture print them.
try:
session.flush()
except kudu.KuduBadStatus as e:
print(session.get_pending_errors())
# Create a scanner and add a predicate
scanner = table.scanner()
scanner.add_predicate(table['ts_val'] == datetime(2020, 7, 12))
# Open Scanner and read all tuples
# Note: This doesn't scale for large scans
result = scanner.open().read_all_tuples()Kudu优化
1.使用SSD会显著提高Kudu性能。(因为如果取多个字段,列式存储在传统磁盘上会多次寻址,而使用SSD不会有寻址问题)
2.kudu性能调优
3.memory_limit_hard_bytes 该参数是单个TServer能够使用的最大内存量。如果写入量很大而内存太小,会造成写入性能下降。如果集群资源充裕,可以将它设得比较大,比如设置为单台服务器内存总量的一半。
官方也提供了一个近似估计的方法,即:每1TB实际存储的数据约占用1.5GB内存,每个副本的MemRowSet和DeltaMemStore约占用128MB内存,(对多读少写的表而言)每列每CPU核心约占用256KB内存,另外再加上块缓存,最后在这些基础上留出约25%的余量。
4.block_cache_capacity_mb Kudu中也设计了BlockCache,不管名称还是作用都与HBase中的对应角色相同。默认值512MB,经验值是设置1~4GB之间,我们设了4GB。
5.memory.soft_limit_in_bytes/memory.limit_in_bytes这是Kudu进程组(即Linux cgroup)的内存软限制和硬限制。当系统内存不足时,会优先回收超过软限制的进程占用的内存,使之尽量低于阈值。当进程占用的内存超过了硬限制,会直接触发OOM导致Kudu进程被杀掉。我们设为-1,即不限制。
6.maintenance_manager_num_threads单个TServer用于在后台执行Flush、Compaction等后台操作的线程数,默认是1。如果是采用普通硬盘作为存储的话,该值应与所采用的硬盘数相同。
7.max_create_tablets_per_ts创建表时能够指定的最大分区数目(hash partition * range partition),默认为60。如果不能满足需求,可以调大。
8.follower_unavailable_considered_failed_sec当Follower与Leader失去联系后,Leader将Follower判定为失败的窗口时间,默认值300s,判定为失败则认为数据丢失。
9.max_clock_sync_error_usec NTP时间同步的最大允许误差,单位为微秒,默认值10s。如果Kudu频繁报时间不同步的错误,可以适当调大,比如15s。
Kudu异常处理
Apache Kudu Troubleshooting
1.报错”Remote error:Service unavailable: Scan request on kudu.tserver.TabletServerService from xx.xx.xx.xx:xx dropped due to backpressure.The service queue is full;it has 50 ites.” 原因:高峰期单个Tablet的rpc请求队列达到上限,导致TabletServer无法提供服务,临时解决方案是重启该TabletServer。 可在gflagfile增加参数:–rpc_service_queue_length=120 (适当调大,默认值100)
2.TS维护前需要健康检查,如果有任何副本不足的情况,需等待副本拷贝完成后再维护。可在gflagfile增加参数:–rpc_service_queue_length=3600 follower_unavailable_considered_failed_sec默认为300s,tablet失去联系超过300s后,该节点的数据就会在其他节点重建,为了避免维护造成的不必要的数据移动和拷贝,可以临时设置此时间为更长的时间(重启维护加上tablet重启后初始化需要的时间) KuduTS重启恢复速度更快。
3.Kudu JavaAPI客户端请求连接服务器Mater时报错:
①Caused by: org.apache.kudu.client.RecoverableException: connection disconnected
②你的主机中的软件终止了一个已建立的链接 unexpected exception from downstream on
③Caused by: org.apache.kudu.client.NoLeaderFoundException: Master config (master1_ipaddr:7051,master2_ipaddr:7051,master3_ipaddr:7051) has no leader. Exceptions received: org.apache.kudu.client.RecoverableException: connection disconnected,org.apache.kudu.client.RecoverableException: connection disconnected,org.apache.kudu.client.RecoverableException: connection disconnected
④org.apache.kudu.client.NonRecoverableException: cannot complete before timeout:KuduRpc(method=GetTableSchema,tablet=null,attemtp=7…,Sent:(master-master1_ip:7051,[ConnectToMaster,7 ])…Received(master-master1_ip:7051,[NERWORK_ERROR, 6]))
在网上搜了一大堆:设置完如下的配置,也不起作用。
–rpc_encryption=disabled
–rpc_authentication=disabled
–trusted_subnets=0.0.0.0/0
原因:kudu客户端连接kudu服务器时,服务器返回master的主机名而非IP,告诉客户端谁是master,然后通信,但是主机名不是主机的ip,所以客户端会在本地hosts文件找这个主机名,但是本机没有配置,所以会失败,直到超时。
解决:需要本地解析ip对应的host,修改本地host,增加Master节点的host映射即可解决。
4.Impala 查询Kudu报Error loading metadata for kudu table xxx 如下: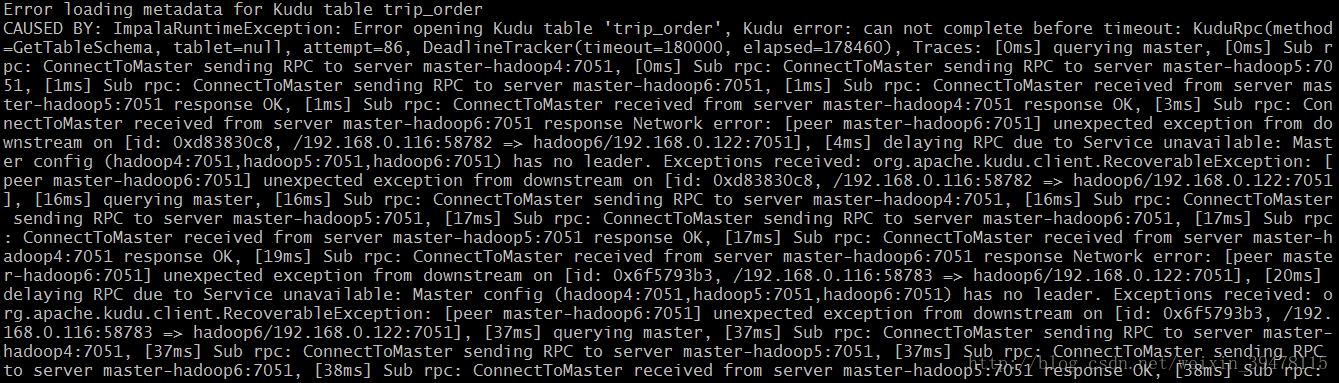
原因:Impala操作Kudu超时
解决:在Impala设置kudu_operation_timeout_ms = 1800000
5.Kudu客户端如下报错:
RPC can not complete before timeout: KuduRpc(method=CreateTable, tablet=null, attempt=26, DeadlineTracker(timeout=30000, elapsed=29427)
解决:
session.setTimeoutMillis(60000);
new KuduClient.KuduClientBuilder("cdh101").defaultAdminOperationTimeoutMs(600000).build();6.Kudu服务部分或全部挂,报错日志如下
Check failed: _s.ok() Bad status: Service unavailable: Cannot initialize clock: Timed out waiting for clock sync: Error reading clock. Clock considered unsynchronized
原因:ntp同步问题,可能是ntpd进程未启动、或/etc/sysconfig/ntpd带有-x参数、或所有节点都同步到一台公用ntp服务器但该ntp服务器有问题
解决:1.检查ntpd进程是否存在 2.去掉/etc/sysconfig/ntpd中-x参数(默认只有-g) 3.配置/etc/ntp.conf将集群内所有节点时钟同步到集群内的某一台节点 再重启Kudu即可
7.Kudu客户端报错提示服务端需要认证
具体堆栈如下:
org.apache.kudu.client.NonRecoverableException: cannot re-acquire authentication token after 5 attempts (Couldn't find a valid master in (master1:7051,master2:7051,master3:7051). Exceptions received: [org.apache.kudu.client.NonRecoverableException: server requires authentication, but client Kerberos credentials (TGT) have expired. Authentication tokens were not used because this connection will be used to acquire a new token and therefore requires primary credentials, org.apache.kudu.client.NonRecoverableException: server requires authentication, but client Kerberos credentials (TGT) have expired. Authentication tokens were not used because this connection will be used to acquire a new token and therefore requires primary credentials, org.apache.kudu.client.NonRecoverableException: server requires authentication, but client Kerberos credentials (TGT) have expired. Authentication tokens were not used because this connection will be used to acquire a new token and therefore requires primary credentials])
at org.apache.kudu.client.KuduException.transformException(KuduException.java:110)
at org.apache.kudu.client.KuduClient.joinAndHandleException(KuduClient.java:413)
at org.apache.kudu.client.KuduScanner.nextRows(KuduScanner.java:72)
at com.smy.crm.common.kudu.KuduApiHelperNew.select(KuduApiHelperNew.java:182)
at com.smy.crm.common.kudu.KuduApiHelper.select(KuduApiHelper.java:161)
at com.smy.crm.tag.util.TagKuduUtil.findCustAllTagFromNarrow(TagKuduUtil.java:302)
at com.smy.crm.tag.manager.TagKuduManager.findCustAllTag(TagKuduManager.java:332)
at com.smy.crm.tag.rule.TagRealTimeExecute.execute(TagRealTimeExecute.java:105)
at com.smy.crm.tag.mq.AutoTagMqConsumer.lambda$startNewConsumer$0(AutoTagMqConsumer.java:78)
at org.apache.rocketmq.client.impl.consumer.ConsumeMessageConcurrentlyService$ConsumeRequest.run(ConsumeMessageConcurrentlyService.java:411)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)查看kudu配置发现服务端–rpc_authentication参数值为required而未按官网说的默认是optional
所以未认证或认证过期的长连接就会连接失败导致程序挂掉
参考Kudu官网介绍如下:
Kudu authentication with Kerberos
Kudu can be configured to enforce secure authentication among servers, and between clients and servers. Authentication prevents untrusted actors from gaining access to Kudu, and securely identifies connecting users or services for authorization checks. Authentication in Kudu is designed to interoperate with other secure Hadoop components by utilizing Kerberos.
Configure authentication on Kudu servers using the --rpc_authentication flag, which can be set to one of the following options:
required - Kudu will reject connections from clients and servers who lack authentication credentials.
optional - Kudu will attempt to use strong authentication, but will allow unauthenticated connections.
disabled - Kudu will only allow unauthenticated connections.
By default, the flag is set to optional. To secure your cluster, set --rpc_authentication to required.解决:在gflagfile增加参数:–rpc_authentication=optional
8.Kudu新增节点无法连接
客户端错误日志
org.apache.kudu.client.NonRecoverableException: cannot complete before timeout: KuduRpc(method=GetTableSchema, tablet=null, attempt=10, TimeoutTracker(timeout=30000, elapsed=30020), Trace Summary(27441 ms): Sent(30), Received(27), Delayed(9), MasterRefresh(10), AuthRefresh(0), Truncated: false
Sent: (master-xxx1:7051, [ ConnectToMaster, 10 ]), (master-xxx2:7051, [ ConnectToMaster, 10 ]), (master-xxx3:7051, [ ConnectToMaster, 10 ])
Received: (master-xxx1:7051, [ NETWORK_ERROR, 9 ]), (master-xxx2:7051, [ NETWORK_ERROR, 9 ]), (master-xxx3:7051, [ NETWORK_ERROR, 9 ])
Delayed: (UNKNOWN, [ GetTableSchema, 9 ]))Master日志
Failed RPC negotiation. Trace:
1203 17:18:29.304059 (+ 0us) reactor.cc:583] Submitting negotiation task for server connection from kudu_client_ip:41573
1203 17:18:29.304166 (+ 107us) server_negotiation.cc:184] Beginning negotiation
1203 17:18:29.304168 (+ 2us) server_negotiation.cc:373] Waiting for connection header
1203 17:18:29.367151 (+ 62983us) server_negotiation.cc:381] Connection header received
1203 17:18:29.368056 (+ 905us) server_negotiation.cc:337] Received NEGOTIATE NegotiatePB request
1203 17:18:29.368057 (+ 1us) server_negotiation.cc:420] Received NEGOTIATE request from client
1203 17:18:29.368073 (+ 16us) server_negotiation.cc:349] Sending NEGOTIATE NegotiatePB response
1203 17:18:29.368090 (+ 17us) server_negotiation.cc:205] Negotiated authn=SASL
1203 17:18:29.527892 (+159802us) server_negotiation.cc:337] Received TLS_HANDSHAKE NegotiatePB request
1203 17:18:29.528938 (+ 1046us) server_negotiation.cc:349] Sending TLS_HANDSHAKE NegotiatePB response
1203 17:18:29.555620 (+ 26682us) server_negotiation.cc:337] Received TLS_HANDSHAKE NegotiatePB request
1203 17:18:29.555806 (+ 186us) server_negotiation.cc:349] Sending TLS_HANDSHAKE NegotiatePB response
1203 17:18:29.555827 (+ 21us) server_negotiation.cc:589] Negotiated TLSv1.2 with cipher ECDHE-RSA-AES256-GCM-SHA384 TLSv1.2 Kx=ECDH Au=RSA Enc=AESGCM(256) Mac=AEAD
1203 17:18:29.649572 (+ 93745us) negotiation.cc:304] Negotiation complete: Network error: Server connection negotiation failed: server connection from kudu_client_ip:41573: BlockingRecv error: failed to read from TLS socket (remote: kudu_client_ip:41573): Cannot send after transport endpoint shutdown (error 108)
Metrics: {"server-negotiator.queue_time_us":79,"thread_start_us":42,"threads_started":1}原因及解决
kudu-master_trusted_subnets
kudu-tserver_trusted_subnets
客户端所在机器不在默认信任子网内(白名单),导致连接无权限。如果不考虑安全性可以设置–trusted_subnets=0.0.0.0/0,如若考虑安全性,可以在默认值基础上增加新节点所在子网地址。
例:–trusted_subnets=127.0.0.0/8,10.0.0.0/8,172.16.0.0/12,192.168.0.0/16,169.254.0.0/16,172.17.0.0/8
注:需要设置在“gflagfile 的 Kudu 服务高级配置代码段(安全阀)”
HTAP混合事务分析处理
HTAP,即Hybrid Transactional Analytical Processing,我们知道OLAP、OLTP,而HTAP就是结合两者场景,既需要联机事务处理有需要联机分析处理,这也是Kudu的场景。
HTAP的场景举例:
- 管理层希望看到实时的数据汇总报表
- 客服人员希望能够尽快访问某设备的最新数据以便尽快排除故障
- 乘车线路拥堵立刻感知并立刻规划线路
- 车联网,物联网
总结
Kudu–Fast Analytics on Fast Data.一个Kudu实现了整个大数据技术栈中诸多组件的功能,有分布式文件系统(好比HDFS),有一致性算法(好比Zookeeper),有Table(好比Hive表),有Tablet(好比Hive分区),有列式存储(如Parquet),有顺序和随机读取(如HBase),所以看起来kudu像一个轻量级的,结合了HDFS+Zookeeper+Hive+Parquet+HBase等组件功能并在性能上进行平衡的组件。它轻松地解决了随机读写+快速分析的业务场景,解决了实时数仓的诸多难点,同时降低了存储成本和运维成本。
学Kudu时让我想到曾经看过的终结者系列电影,万物互联,主角不小心被街边一个不起眼的监控探头拍到,就会立刻引来终结者的追杀,任何有网络的地方留下任何痕迹都会立刻被终结者感知…很明显,这就是在快速变化的数据上进行快速分析,如果没有Kudu,大量的物联网数据就只能批处理了,就没了时效性,主角就可以随便浪了。没准”天网”系统里就部署了Kudu节点呢?!哈哈哈!
在实时数仓、实时计算和物联网蓬勃发展的今天,你确定不学一下Kudu吗?
参考资料
1.《Kudu:构建高性能实时数据分析存储系统》
2.Apache Kudu - Fast Analytics on Fast Data
3.Kudu专注于大规模数据快速读写,同时进行快速分析的利器
4.Kudu基础入门
5.Kudu、Hudi和Delta Lake的比较
6.迟到的Kudu设计要点面面观
7.迟到的Kudu设计要点面面观-前篇
8.kudu-列式存储管理器-第四篇(原理篇)
9.Kudu configuration reference



