







MySQL索引原理深入
索引可以大大提高Mysql检索速度,为什么能提高,怎么做到的?这些细节必须深入学习和分析,才能对技术运用了如指掌。
今天来学习一下Mysql的索引原理与底层存储选型,为了能够对Mysql有更深入的了解。
索引
定义
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。
索引相当于我们看书的目录。
优点
1.快速检索数据
2.保证数据记录唯一性
3.实现表与表之间的参照完整性
4.使用ORDER BY/GROUP BY子句进行数据检索时,利用索引可以减少排序和分组的时间
缺点
1.索引需要占磁盘物理空间
2.增删改操作时索引也要动态地维护,有性能开销
3.创建索引耗时,数据量越大耗时也越大
分类
1.普通索引:无唯一性限制
2.唯一索引:UNIQUE,有唯一性限制
3.主键索引:唯一索引的特殊类型,在主键上创建索引
4.候选索引:唯一性,切决定记录的处理顺序
5.聚集索引:Clustered Index聚簇索引,索引列的键值的物理顺序与逻辑顺序相同
6.非聚集索引:Non-Clustered Index非聚簇索引,索引列的键值的物理顺序与逻辑顺序无关
7.全文索引:主要针对文本的内容进行分词,加快查询速度
8.联合索引:多列组成的索引,查询效率提升高于多个单列索引合并的效率
应用场景
1.在经常搜索的列上创建索引
2.在主键上创建索引
3.在用来JOIN的列上创建索引
4.在经常通过WHERE根据范围检索的列上创建索引
5.在经常GROUP BY/ORDER BY的列上创建索引
6.在经常DISTINCT的列上创建索引
索引字段要求
1.列值的唯一性太小不适合建索引
2.列值太长不适合建索引
3.更新频繁的列不适合建索引
索引失效
1.LIKE的使用(LIKE XXX%可以用索引,但LIKE %xxx不能)
2.部分操作符(**<,<=,=,>,>=,BETWEEN,IN可以用索引,但<>,not in,!=不能**)
3.判空操作(is null或is not null)
4.int类型字段(如手机号没用varchar存,查186开头的,不能)
5.联合索引(设置了col1和col2两个字段联合索引,WHERE col1=’xxx’或WHERE col1=’xxx’ AND col2=’xxx’或WHERE col2=’xxx’ AND col1=’xxx’都可用索引,但WHERE col2=’xxx’不能)
6.对索引列操作(计算、函数、自动类型转换、手动类型转换都会使索引失效)
7.SELECT *(尽量使用覆盖索引,尽量取用到的字段值而非使用星号,这样WHERE的时候覆盖索引效率高)
8.字符串不加单引号引起索引失效
9.尽量避免索引列有null值
Mysql索引数据结构选型
该部分会详细说明:
索引数据结构的选型过程以及各自的优缺点
B树与B+树的区别
为什么以B+树作为Mysql的索引数据结构
Innodb引擎和MyISAM引擎的区别以及索引实现和存储区别
聚簇索引与非聚簇索引区别
数据结构选型过程
过程:哈希表->二叉查找树->红黑树->二叉平衡树AVL->B树->B+树
哈希表
哈希算法把任意的key变换成固定长度的key地址。性能不错,但是有哈希冲突问题,一般用链地址法来解决(类似HashMap)。
这样查数据的时候先计算Hash,然后遍历链表,直到拿到key。
时间复杂度O(1),看来很理想。但是为什么没用哈希?
如果用哈希表做索引的数据结构,select * from tb where id > 1这样的范围查找场景,就要把索引数据全部加载到内存再筛选,太慢。虽然Hash做索引的数据结构可以快速定位key,但没法做到高效的范围查找。
ps:当然,如果业务是经常使用where条件单条查询数据,Hash索引效率更高复杂度O(1)。使用Hash索引,InnoDB和MyISAM不支持,可用MEMORY,NDB引擎。二叉查找树
BinarySearchTree(BST)是支持数据快速查找的数据结构,复杂度O(log2n)~O(n)之间,也可以高速检索数据
能不能解决范围查找呢?
能!比如我找id > 3,我只要找到比它大的根节点和右子树即可。
那为啥二叉查找树不能做索引的数据结构?
因为如果二叉排序树是平衡的,则n个节点的二叉排序树的高度为log2(n+1),其查找效率为O(log2n),近似于折半查找。如果二叉排序树完全不平衡,则其深度可达到n,查找效率为O(n),退化为顺序查找。而数据库中经常有以自增id为主键索引的场景,必然会线性查找,性能太低。红黑树
通过自动调整树形态让二叉树保持基本平衡,复杂度O(logn),因为基本平衡,查询效率不会明显降低,不存在O(n)的情况。
吃瓜群众:那就用这个做索引数据结构吧!
万万不可用红黑树做索引的数据结构!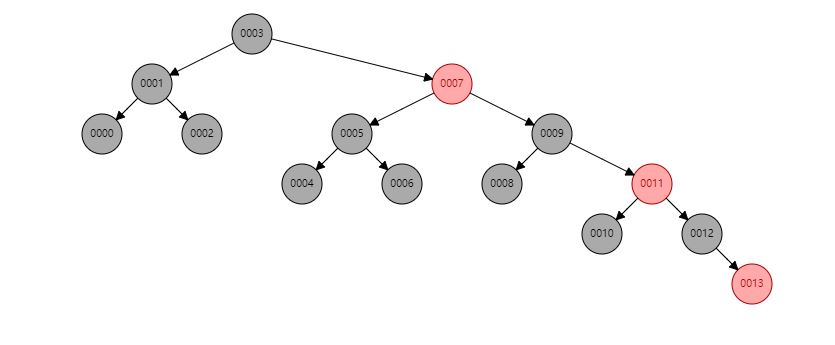
还是自增id为主键索引的情况,如果红黑树按顺序插入数据,整个红黑树会明显右倾,查询效率会明显降低。
像我这种数据结构渣渣,送自己一个宝贝:红黑树算法图形模拟AVL树
AVL树,也是通过调整形态保持二叉树平衡,它虽然在调整形态时会有更多性能开销,但它绝对平衡。它能根本解决红黑树的右倾问题。复杂度O(logn)。
那AVL树这么好,为啥还是不能用于索引数据结构?
AVL树每个节点只能存一个数据,每次比较只能加载一个数据到内存,查询较深的AVL树节点,就要有多次的磁盘IO开销,磁盘IO是数据库瓶颈,这样肯定不合理的呀!对磁盘IO的优化方案就是一次尽可能多读或者多写数据,读1b和读1kb速度基本一样的,希望磁盘能一次加载更多数据进内存,这就是B树,B+树原理了。
- B树与B+树
B树:
又名多路查找树,特点:
①节点数据递增,遵循左小右大
②M阶B树,每个节点最多可以有M个子节点
③根节点至少有两个儿子
④除根结点之外的所有非叶子结点至少有ceil(M/2)个子节点(ceil(2.1) = 3)
⑤所有叶子节点都在同一层次
B树代替AVL树:让每个节点存的key数目适当增加,即增加M(B树的阶数),磁盘读取次数大大降低,尽可能减少磁盘IO,加快检索速度,还能支持范围查找。
B+树:
与B树区别:
一是B树每个节点(包括非叶子节点)都存数据,B+树非叶子节点有索引作用,而数据存在叶子节点 –> B树的每个节点存不了太多数据,B+树每个叶子节点能存很多索引(地址)。所以B+树高度更低,减少了磁盘IO。
二是B树节点之间没索引,B+相邻叶子节点之间有索引指针 –> WHERE范围查询性能很好。
三是B+树的查询效率更稳定,因为数据都存在叶子节点,查数据的操作次数相同。
综上,Mysql基于B+树实现的索引。
InnoDB与MyISAM的区别
| InnoDB | MyISAM |
|---|---|
| 默认支持ACID | 不支持ACID |
| 支持外键 | 不支持外键 |
| 性能好 | 性能好于Innodb |
| 必须有主键 | 可没有主键 |
| 数据与索引存放在一起 | 数据与索引分开存放 |
| 聚集索引方式 | 非聚集索引方式 |
| 支持表级、行级(默认)锁 | 支持表级锁 |
| 崩溃易恢复 | 崩溃难恢复 |
聚集索引与非聚集索引(InnoDB与MyISAM实现索引的区别)
mysql> show global variables like "%datadir%";
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
mysql> create table innodb_table(id varchar(255) not null primary key,name varchar(255) not null)
-> ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.02 sec)
mysql> create table myisam_table(id varchar(255) not null primary key,name varchar(255) not null)
-> ENGINE=myisam DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.00 sec)
ll /var/lib/mysql/db_name/
总用量 128
-rw-rw----. 1 mysql mysql 65 3月 24 04:30 db.opt
-rw-rw----. 1 mysql mysql 8586 3月 24 04:31 innodb_table.frm
-rw-rw----. 1 mysql mysql 98304 3月 24 04:31 innodb_table.ibd
-rw-rw----. 1 mysql mysql 8586 3月 24 04:33 myisam_table.frm
-rw-rw----. 1 mysql mysql 0 3月 24 04:33 myisam_table.MYD
-rw-rw----. 1 mysql mysql 4096 3月 24 04:33 myisam_table.MYI从建表后生成的文件可看出,InnoDB生成frm(建表语句)和ibd(数据+索引),而MyISAM生成frm(建表语句),MYD(数据文件)和MYI(索引文件)。
MyISAM引擎把数据和索引分开成数据文件和索引文件两个文件,这叫做非聚集索引方式。
Innodb 引擎把数据和索引放在同一个文件里了,这叫做聚集索引方式。
更详细一点的解释:
聚集索引物理顺序与逻辑顺序一致,非聚集索引的物理顺序与逻辑顺序不一致。
非聚集索引的叶子节点存key和对应地址,不存数据;聚集索引的叶子节点存key和对应的value,value内存地址是连续的
为什么MyISAM比InnoDB快?
上面我们已经提到InnoDB使用聚集索引,MyISAM使用非聚集索引。两种引擎的数据组织方式不同。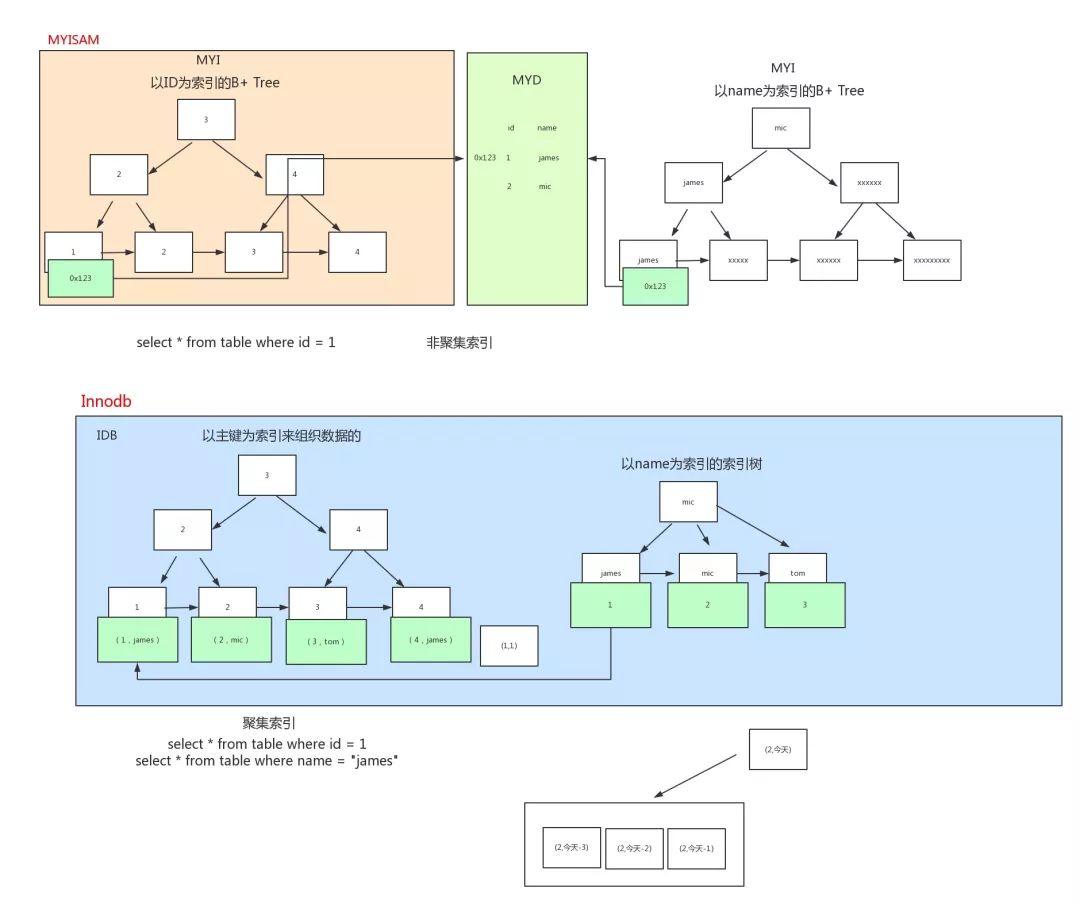
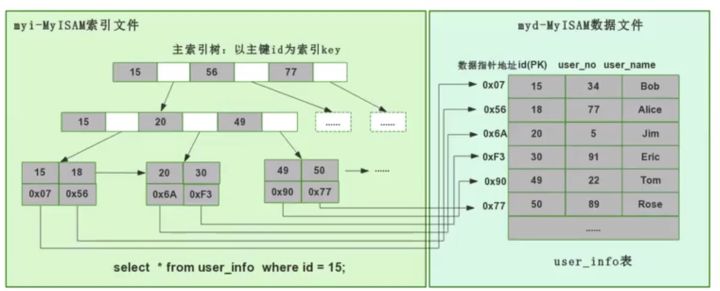
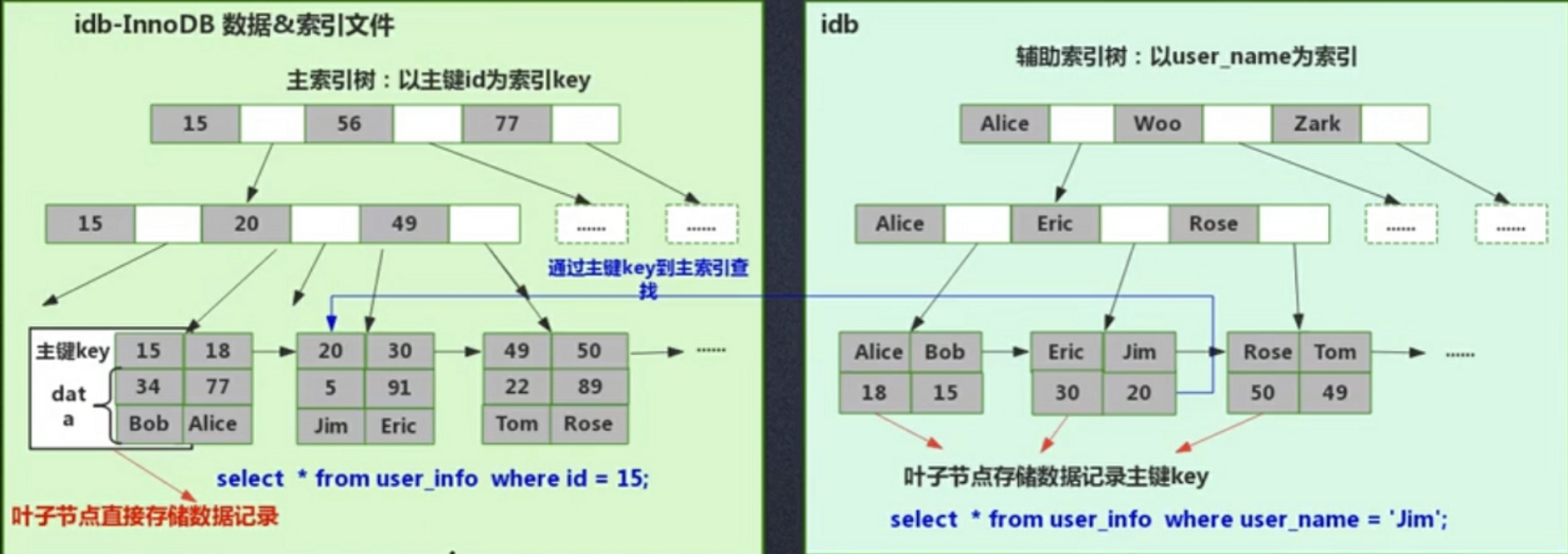
如图是两种引擎组织数据的方式
查询时InnoDB需要通过主键索引树先拿到主键值后再去辅助索引树拿到整条记录(建表的时候InnoDB就会自动建立好主键索引树),而MyISAM拿到数据的索引即可直接以Offset形式直接在数据文件中定位数据。而且InnoDB因为支持ACID,还要检查MVCC多版本并发控制,而MyISAM不支持事务,也是其快的原因。还有MyISAM维护了一个保存整表行数的变量,count(*)很快。
其他数据库索引数据结构
该部分会详细说明为什么Mysql用B+树索引而MongoDB用B树。
1.MongoDB本身很少有范围搜索操作,做单一查询比较多
2.Mysql关系型数据库,做范围检索的操作很多,如join,where x>1等,B+树叶子节点有指针,遍历效率高
参考资料
下面列出参考资料,我认为写得好的已加粗
深入理解 Mysql 索引底层原理
为什么Mongodb索引用B树,而Mysql用B+树?
Mysql—索引失效
磁盘IO概念及优化入门知识
MVCC多版本并发控制
Mysql索引
Mysql索引必须了解的几个重要问题
其他细节
1.ORDER BY与索引失效:当order by的字段出现在where条件中时,才会利用索引而不排序,更准确的说,order by中的字段在执行计划中利用了索引时,不用排序操作。这个结论不仅对order by有效,对其他需要排序的操作也有效。比如group by 、union 、distinct等。(出现在Order by 后的索引列都是用于排序的,不会用于查找,所以索引无效)
2.innodb引擎的4大特性:插入缓冲(insert buffer),二次写(double write),自适应哈希索引(ahi),预读(read ahead)
3.主键和唯一索引的区别:①唯一索引列允许空值,主键不允许空值 ②主键可以被其他表引用为外键,唯一索引不能 ③一个表只能一个主键但可有多个唯一索引



