Hive3.x新特性
新特性简述

- 执行引擎变更为**TEZ**,不使用MR
- 成熟的ACID大数据事务支持
- LLAP用于妙极,毫秒级查询访问
- 基于Apache Ranger的统一权限管理
- 默认开启HDFS ACLs
- Beeline代替Hive Cli,降低启动开销
- 不再支持内嵌Metastore
- Spark Catalog不与Hive Catalog集成,但可以互相访问
- 批处理使用TEZ,实时查询使用LLAP
- Hive3支持联邦查询
架构原理
- TEZ执行引擎
Apache TEZ**是一个针对Hadoop数据处理应用程序的分布式计算框架,基于Yarn且支持DAG作业的开源计算框架。Tez产生的主要原因是绕开MapReduce所施加的限制,逐步取代MR,提供更高的性能和灵活性。
Apache TEZ的核心思想是将Map和Reduce拆分成若干子过程,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,分解后可以灵活组合成一个大的DAG作业。
Apache TEZ兼容MR任务,不需要代码层面的改动。
Apache TEZ提供了较低级别的抽象,为了增强Hive/Pig的底层实现,而不是最终面向用户的。
Hive3的TEZ+内存查询结合**的性能据说是Hive2的50倍(也有文章说是100倍,这个数字是不是很熟悉,它到底能不能与Spark内存计算速度媲美呢)。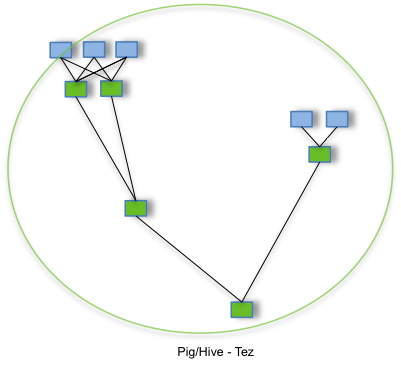
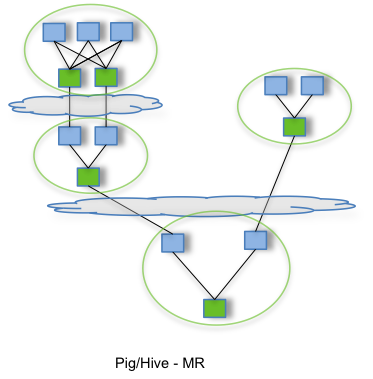
上图是Hive On MR和Hive On Tez执行任务流程对比图,解释:
| Hive On MR | Hive On Tez |
|---|---|
| 计算需要多个MR任务而且中间结果都要落盘 | 只有一个作业,只写一次HDFS |
| 没有资源重用 | 资源复用 |
| 处理完释放资源 | Applications Manager资源池启动若干Container,处理完不释放直接分配给未运行任务 |
| Map:Reduce = 1:1 | 不再是一个Map只对应一个Reduce |
| 在磁盘处理数据集 | 小的数据集完全在内存中处理以及内存Shuffle |
新的HiveQL执行流程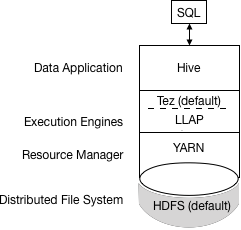
Hive编译查询->Tez执行查询->Yarn分配资源->Hive根据表类型更新HDFS或Hive仓库中的数据->Hive通过JDBC连接返回查询结果
- LLAP
LLAP(Live Long and Process)实时长期处理,是Hive3的一种查询模式,由一个守护进程和一个基于DAG的框架组成,LLAP不是执行引擎(MR/Tez),它用来保证Hive的可伸缩性和多功能性,增强现有的执行引擎。
LLAP的守护进程长期存在且与DataNode直接交互,缓存,预读取,某些查询处理和访问控制功能包含在这个守护程序中用于直接处理小的查询,而计算与IO较大的繁重任务会提交Yarn执行。守护程序不是必须的,没有它Hive仍能正常工作。对LLAP节点的请求都包含元数据信息和数据位置,所以LLAP节点无状态。
可以使用Hive on Tez use LLAP来加速OLAP场景(OnLine Analytical Processing联机分析处理)
LLAP为了避免JVM内存设置的限制,使用堆外内存缓存数据以及处理GROUP BY/JOIN等操作,而守护程序仅使用少量内存。
Hive3支持两种查询模式Container和LLAP
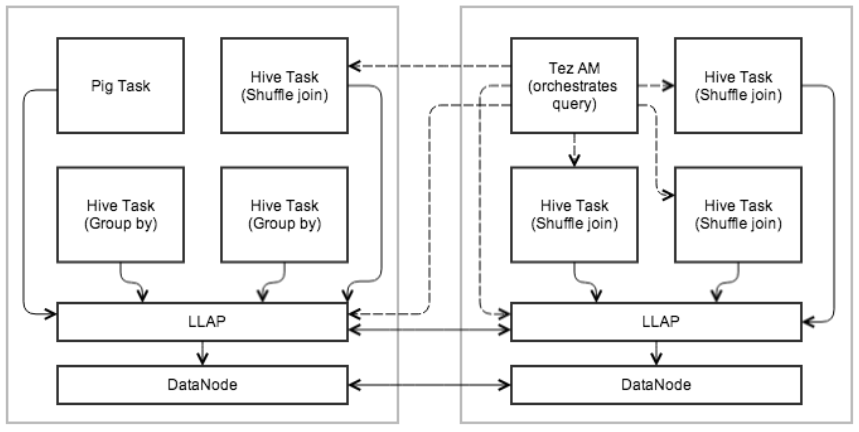
如图LLAP执行示例,TEZ作为执行引擎,初始阶段数据被推到LLAP,LLAP直接与DataNode交互。而在Reduce阶段,大的Shuffle数据在不同的Container容器中进行,多个查询和应用能同时访问LLAP。
更成熟的ACID支持
Hive的UPDATE一直是大数据仓库的一个问题,虽然在Hive3.x之前也支持UPDATE操作,但是性能很差,还需要进行分桶。
Hive3.x支持全新的更成熟的ACID。
Hive3默认对内部表支持事务和ACID特性。
默认情况下启用ACID不会导致性能或操作过载。物化视图重写和自动查询缓存
多个查询可能需要用到相同的中间表,可以通过预先计算和将中间表缓存到视图中来避免重复计算。查询优化器会自动利用预先计算的缓存来提高性能。例如加速仪表盘中的join数据查询速度。元数据映射表
Hive会从JDBC数据源创建两个数据库:information_schema和sys。所有Metastore表都映射到表空间,并在sys中可用。information_schema数据显示系统的状态。支持基于成本优化的智能下推
查询一个数据源时如果读取全部数据后再进行分析是很高成本的,通过JDBC获取过多数据导致资源浪费以及性能不佳,Hive依靠其storage handler接口和Apache Calcite支持的基于成本的优化器(CBO)实现了对其他系统的智能下推。特别是,Calcite提供与查询的逻辑表示中的运算符子集匹配的规则,然后生成在外部系统中等效的表示以执行更多操作。Hive在其查询计划器中将计算推送到外部系统,并且依靠Calcite生成外部系统支持的查询语言。storage handler的实现负责将生成的查询发送到外部系统,检索其结果,并将传入的数据转换为Hive内部表示,以便在需要时进一步处理。这不仅限于SQL系统:例如,Apache Hive也可以联邦Apache Druid或Apache Kafka进行查询,正如我们在最近的博文中所描述的,Druid可以非常高效的处理时序数据的汇总和过滤。因此,当对存储在Druid中的数据源执行查询时,Hive可以将过滤和聚合推送给Druid,生成并发送JSON查询到引擎暴露的REST API。另一方面,如果是查询Kafka上的数据,Hive可以在分区或offset上推送过滤器,从而根据条件读取topic中的数据。Hive 3.0其他特性
1、连接Kafka Topic,简化了对Kafka数据的查询
2、执行查询所需的少量守护进程简化了监视和调试
3、工作负载管理(会话资源限制):用户会话数,服务器会话数,每个服务器每个用户会话数等限制,防止资源争用导致资源不足
4、会话状态,内部数据结构,密码等驻留在客户端而不是服务器上
5、黑名单可以限制内存配置以防止HiveServer不稳定,可以使用不同的白名单和黑名单配置多个HiveServer实例,以建立不同级别的稳定性
联邦查询
支持Oracle、MySQL、Kafka、Druid、HDFS、PostgreSQL等多个数据源的联邦查询,可以对多个数据源统一访问。
联邦查询的优势:
1.单个SQL方言和API
2.集中统一的权限控制和审计跟踪(Hive支持表、行、列的访问控制)
3.统一治理
4.能够合并来自多个数据源的数据
优缺点
优点:
性能,安全性,对ACID事物的支持,对任务资源调度的优化。缺点:
目前最新的CDH6.3还不兼容Hive3,自己安装坑点多;目前相关文献较少,排错难。
实践
https://link.zhihu.com/?target=https%3A//hortonworks.com/tutorial/interactive-sql-on-hadoop-with-hive-llap/
https://link.zhihu.com/?target=https%3A//dzone.com/articles/3x-faster-interactive-query-with-apache-hive-llap
https://link.zhihu.com/?target=https%3A//community.hortonworks.com/articles/149486/llap-sizing-and-setup.html