







大数据平台常见异常处理汇总
本博客记录工作中遇到的,大数据相关各个组件的异常处理过程,养成良好的问题归纳总结习惯,累积问题解决经验与思路。
Spark相关
Shuffle异常导致任务失败
报错:org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 1
原因:
shuffle分为shuffle write和shuffle read两部分。
shuffle write的分区数由上一阶段的RDD分区数控制,shuffle read的分区数则是由Spark提供的一些参数控制。
shuffle write可以简单理解为类似于saveAsLocalDiskFile的操作,将计算的中间结果按某种规则临时放到各个executor所在的本地磁盘上。
shuffle read的时候数据的分区数则是由spark提供的一些参数控制。可以想到的是,如果这个参数值设置的很小,同时shuffle read的量很大,那么将会导致一个task需要处理的数据非常大。结果导致JVM crash,从而导致取shuffle数据失败,同时executor也丢失了,看到Failed to connect to host的错误,也就是executor lost的意思。有时候即使不会导致JVM crash也会造成长时间的gc。
解决思路:减少shuffle的数据量和增加处理shuffle数据的分区数
①spark.sql.shuffle.partitions控制分区数,默认为200,根据shuffle的量以及计算的复杂度提高这个值 shuffle并行度
②提高spark.executor.memory
③map side join或是broadcast join来规避shuffle的产生
④分析数据倾斜 解决数据倾斜
⑤增加失败的重试次数和重试的时间间隔
通过spark.shuffle.io.maxRetries控制重试次数,默认是3,可适当增加,例如10。
通过spark.shuffle.io.retryWait控制重试的时间间隔,默认是5s,可适当增加,例如10s。
⑥类似RemoteShuffleService的服务,解决Shuffle单台机器IO瓶颈,记录Shuffle状态,大批量提升Shuffle效率和稳定性。SparkSQL报awaitResult异常
报错:org.apache.spark.SparkException: Exception thrown in awaitResult
原因:广播数据超时
解决:spark.sql.broadcastTimeout=1200 默认大小300HiveOnSpark不能创建SparkClient及Return Code 1异常
报错:FAILED:SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create spark client.
Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask
原因:以上报错证明初始化Spark失败,而以前不会失败,所以大概率是资源问题而不是代码问题,查看Yarn队列发现所提交的队列已满且已超过能申请资源的上限(虚线部分),故任务启动失败
解决:CM界面->群集->动态资源池配置->提高队列的资源权重(上限也会响应提高)->刷新动态资源池配置ExecutorLost、Task Lost
报错:
1.[executor lost] WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local): ExecutorLostFailure (executor lost)
2.[task lost] WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217): java.io.IOException: Connection from /xx.xxx.xx.xxx:xxxxx closed
3.[timeout] java.util.concurrent.TimeoutException: Futures timed out after [120 second
ERROR TransportChannelHandler: Connection to /xxx.xxx.xx.xxx:xxxxx has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong
原因:节点资源不足、网络延迟波动、GC导致Executor运行慢等原因
解决:①spark.network.timeout的值(默认为120s,配置所有网络传输的延时),根据情况改成300(5min)或更高 ②分别增加各类超时参数
spark.core.connection.ack.wait.timeout
spark.akka.timeout
spark.storage.blockManagerSlaveTimeoutMs
spark.shuffle.io.connectionTimeout
spark.rpc.askTimeout or spark.rpc.lookupTimeoutSparkThriftServer无法链接jdbc,后台报错Task has been rejected by ExecutorService
报错:
2021-08-01 02:26:32.028 WARN [Thread-43] [10.139.53.62] org.apache.thrift.server.TThreadPoolServer.serve(TThreadPoolServer.java:185) :- Task has been rejected by ExecutorService 9 times till timedout, reason: java.util.concurrent.RejectedExecutionException: Task org.apache.thrift.server.TThreadPoolServer$WorkerProcess@6b4f8abf rejected from java.util.concurrent.ThreadPoolExecutor@48ca75d3[Running, pool size = 500, active threads = 500, queued tasks = 0, completed tasks = 917]
原因:每次连接都是一个socket连接,都会提交一个Runnable对象到ExecutorService线程池,线程池默认最大500,连接不使用且未关闭就会占用一个线程,占满就无法再连接
解决:hive-site.xml调整:
hive.server2.session.check.interval 6h->1h
hive.server2.idle.session.timeout 7d->1d
hive.server2.thrift.max.worker.threads (500->800) (根据用户量大概估,一个用户可能多个Socket/JDBC连接)
目的:避免因socket连接对象线程池被占满导致无法连接jdbc<property> <name>hive.server2.session.check.interval</name> <value>1h</value> </property> <property> <name>hive.server2.idle.session.timeout</name> <value>1d</value> </property> <property> <name>hive.server2.thrift.max.worker.threads</name> <value>800</value> </property>注意:hive.server2.session.check.interval < hive.server2.idle.operation.timeout < hive.server2.idle.session.timeout
Spark SQL解析错误unresolved object, tree: ArrayBuffer(a).*
Error executing query, currentState RUNNING, org.apache.spark.sql.catalyst.analysis.UnresolvedException: Invalid call to toAttribute on unresolved object, tree: ArrayBuffer(a).* at org.apache.spark.sql.catalyst.analysis.Star.toAttribute(unresolved.scala:245) at org.apache.spark.sql.catalyst.plans.logical.Project$$anonfun$output$1.apply(basicLogicalOperators.scala:52) at org.apache.spark.sql.catalyst.plans.logical.Project$$anonfun$output$1.apply(basicLogicalOperators.scala:52) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.immutable.List.map(List.scala:296) ......SQL:
select xxx from table_a a LEFT JOIN table_b b ON a.cust_no = b.cust_no LEFT JOIN table_e e ON a.cust_no = e.cust_no LEFT JOIN table_f f ON a.cust_no = f.cust_no LEFT JOIN table_g g ON a.cust_no = g.cust_no ... ... LEFT JOIN table_n n ON a.cust_no = n.cust_no;
原因:Spark2.4版本Catalyse模块的一个Bug,table_b ~ table_n 中但凡有一张表不存在都会抛该异常,而非NoSuchTableException。底层表不存在,就无法将“unresolved object”转换为“resolved object”,于是报了该错误。
解决:确保table_b~table_n中每个表都存在即可解决。
- SparkSQL建表报路径已存在
问题发生在spark2.3迁移到spark2.4及以上版本
原因:Spark2.3迁移到Spark2.4后,Spark2.4默认不支持在非空或者是已存在的HDFS路径上创建内部表org.apache.spark.sql.AnalysisException: Can not create the managed table xxxx. The associated location hdfs://ns1/user/hive/warehouse/xxxx already exists
解决:
设置spark.sql.legacy.allowCreatingManagedTableUsingNonemptyLocation=true参数
或代码里设置参数spark.conf.set(“spark.sql.legacy.allowCreatingManagedTableUsingNonemptyLocation”,”true”)
影响版本: 2.4.0 <= spark.version < 3.0.0
参考:https://spark.apache.org/docs/2.4.0/sql-migration-guide-upgrade.html
参考:https://stackoverflow.com/questions/63837289/apache-spark-sql-table-overwrite-issue
HDFS相关
数据块丢失且命令无法修复
起因:多张表查询发现如下报错,提示块丢失
分析:CM界面看HDFS丢失块,发现有2500多,大批量块丢失可能的原因:
1.DataNode与NameNode未通信,DataNode进程未启动
2.DataNode数据磁盘损坏,数据丢失
3.一个文件的全部副本丢失
解决过程:
尝试修复丢失块:hdfs debug recoverLease -path-retries
显示修复成功,但使用hadoop fs -text还是报MissingBlock无法读取
使用fsck检测坏块 hdfs fsck /user/hive/warehouse
发现绝大多数block名称都带有172.xxx.xxx.11 定位到可能是172.xxx.xxx.11节点的DataNode可能存在问题
通过CM日志和机器上进程状态判断172.xxx.xxx.11的DataNode已与NameNode保持心跳,运行正常,进而怀疑磁盘坏了(概率太小)
查看CM配置和机器磁盘,发现少配置了些硬盘路径,原因是在配置新节点磁盘路径时误修改整个配置组的磁盘路径,导致该配置组中所有DataNode缺少磁盘,进而出现块丢失且无法修复的问题。
解决:还原磁盘配置,滚动重启该配置组中的DataNode,将不同机器配置分成多个配置组,重新修改配置
重启过程中丢失块数一直在减少:
最终恢复正常
总结:
1.CM上修改配置一定要慎重,注意修改配置组中某台节点的配置会影响整个配置组中所有节点的配置
2.CM显示DataNode重启成功只是进程启动成功,但日志出现“Total time to add all replicas to map”字眼才是真正完成启动
3.https://hdfs-site/dfshealth.html#tab-overview 从HDFS WebUI获取更多信息(丢失块的信息一目了然)Win开发Hadoop环境winutils
错误:Could not locate executable null\bin\winutils.exe in the Hadoop binaries
解决:将winutils.exe放在HADOOP_HOME\bin下,然后代码里System.setProperty(“hadoop.home.dir”, “D:\Programming\Env\Hadoop\hadoop-2.7.2\“)或设置环境变量HADOOP_HOME和PATH后重启电脑
winutils.exe下载地址:winutils-masterNamenode is not formatted
错误Namenode is not formatted
分析:一般新部署的HDFS才会提示需要格式化(hadoop namenode -format),而生产环境Namenode一旦有异常,也可能出现这样的问题,但我不能格式化生产环境啊!
NN日志如下: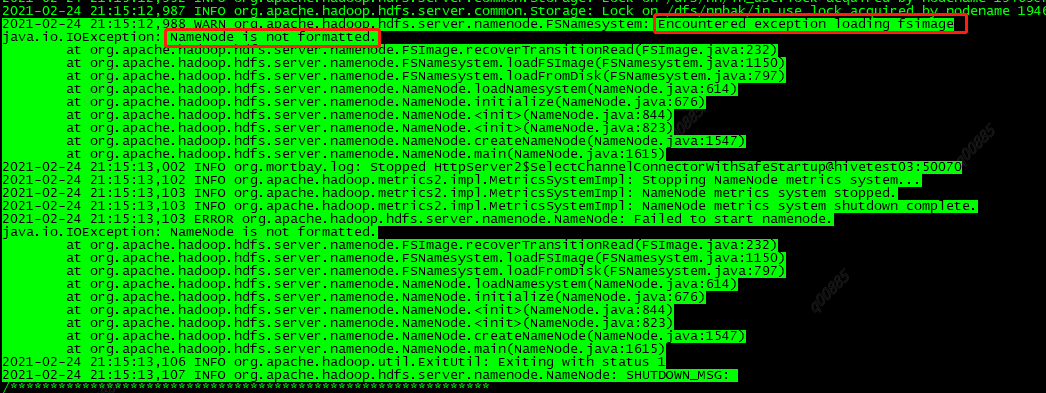
可知识由于加载fsimage异常,去NameNode的存储路径/dfs/nn/发现没有文件,而其他节点/dfs/nn目录下有current目录,current目录下有fsimage。所以可以判定该Namenode无法启动就是因为fsimage丢失。
解决:scp这个current目录,权限与之前的一致(一般为hdfs:hdfs权限)修复HDFS坏块
查看坏块可通过hdfs fsck / hadoop dfsadmin -report修复坏块除了上面讲过的hdfs debug recoverLease -path
-retries 两个NN均为Standby,重启后过一会又都Standby
NN均报错:
java.util.concurrent.ExecutionException: java.io.IOException: Cannot find any valid remote NN to service request!
Caused by: java.io.IOException: Cannot find any valid remote NN to service request!
Exception from remote name node RemoteNameNodeInfo [nnId=namenode37, ipcAddress=xxxx, httpAddress=xxxx], try next.
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category JOURNAL is not supported in state standby. Visit https://s.apache.org/sbnn-error
解决:强制切换主备sudo -uhdfs hdfs haadmin -transitionToActive –forcemanual namenode37(nnId在hdfs-site有配) 切换后重启Failover Controller或ZKFC。基于Sentry认证的HDFS集群NN启动异常
NN进程启动成功但是一直处于忙碌状态,查看NN的日志晚上9点53:24.664分 INFO SentryAuthorizationInfo Refresh interval [500]ms, retry wait [30000] 晚上9点53:24.664分 INFO SentryAuthorizationInfo stale threshold [60000]ms 晚上9点53:24.669分 INFO HMSPaths HMSPaths:[/user/hive/warehouse, /user/hive/xxxx] Initialized 晚上9点53:24.681分 INFO SentryTransportPool Creating pool for xxx:8038,xxx:8038 with default port 8038 晚上9点53:24.683分 INFO SentryTransportPool Adding endpoint xxx:8038 晚上9点53:24.683分 INFO SentryTransportPool Adding endpoint xxx:8038 晚上9点53:24.683分 INFO SentryTransportPool Connection pooling is disabled 日志卡在这不继续了,卡在这与此同时两个SentryServer有一台发生OOM,不稳定
原因:由于基于Sentry认证,HDFS的NN在启动时,Sentry会全量收集HMSPaths下的ACL信息,会驻留在Sentry内存中,如果Sentry内存不足容易OOM,需要通过增加堆内存的方式解决。两个SentryServer虽然可以负载均衡高可用,当一个SentryServer宕掉请求才会转移到另一个节点,而OOM时,请求会一直卡住,不会自动转移,导致NN启动异常。
解决:增加Sentry堆内存,不盲目加,根据当前Hive服务器数、库数、表数、分区数、列数及视图数进行评估,具体评估标准如下: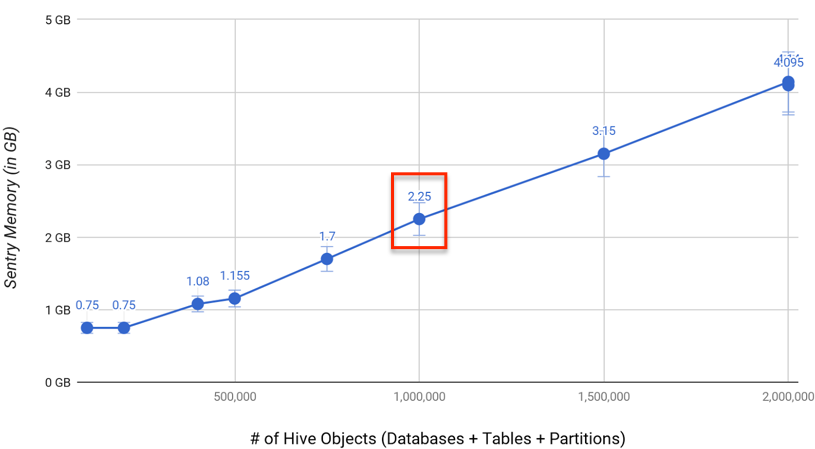
如图推算:每百万个Hive对象(库、表、分区数)需要配置2.25G的Sentry最大堆内存distcp数据拷贝报错
distcp报错file might have been written to during copy, consider enabling HDFS Snapshots to avoid this error.
hdfs-site.xml里增加dfs.namenode.snapshot.capture.openfiles 值为true 开启Immutable Snapshot,保证快照目录里所有文件的状态都是关闭的,文件大小都是创建快照时的状态,解决同步hdfs数据报错文件不存在,或者报不能复制一个打开的或正在写入的文件这些问题。NameNode启动后无法RPC和切换状态并一直FullGC,几乎80%以上时间都在FullGC
2021-07-14 09:38:35,803 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 47892ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=48186ms 2021-07-14 09:39:25,780 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 47976ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=48428ms 2021-07-14 09:40:15,526 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 47744ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=47840ms 2021-07-14 09:41:04,652 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 47126ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=47437ms 2021-07-14 09:41:55,106 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 48452ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=48767ms 2021-07-14 09:42:48,440 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 51332ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=51719ms 2021-07-14 09:43:40,527 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 50086ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=50450ms 2021-07-14 09:44:34,750 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 52222ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=52462ms 2021-07-14 09:45:30,759 WARN org.apache.hadoop.util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 53999ms GC pool 'ConcurrentMarkSweep' had collection(s): count=1 time=54179ms原因:加载FSImage到堆内存的过程中由于堆内存不足导致无法启动。
解决:
①增加NameNode堆内存,启动后查看HDFS WebUI->Overview->Summary查看主NN堆内存使用情况和目前Blocks数量,对NN内存需求重新做评估,调整合适的堆大小。根据Block数量和增量精细化计算NN的堆内存,避免再次OOM。
②如果可能,可以减小HDFS垃圾回收时间。
③查看HDFS WebUI->Snaoshot栏,删除无用的快照,避免快照变化文件占用大量空间和Blocks。HDFS DataNode磁盘切换
停止DN、JN -> 将/dfs目录移至目标磁盘,并修改hdfs对应的磁盘为目标路径(对应节点的dfs.journalnode.edits.dir和dfs.datanode.data.dir) -> 启动DN、JNHDFS远程Kerberos客户端连接非Kerberos集群报错:
hdfs dfs -ls hdfs://remote_nn_ip:8020/user/hive/warehouse/ls: Failed on local exception: java.io.IOException: Server asks us to fall back to SIMPLE auth, but this client is configured to only allow secure connections.; Host Details : local host is: "client_host/client_ip"; destination host is: "remote_nn_ip":8020;原因:本地客户端采用Kerberos认证,但远程Server未开启Kerberos认证,远程为SIMPLE认证
解决:
设置ipc.client.fallback-to-simple-auth-allowed=true参数即可 参数加在dfs后面 如下hdfs dfs -D ipc.client.fallback-to-simple-auth-allowed=true -ls hdfs://remote_nn_ip:8020/user/hive/warehouse/HDFS无法上传文件
# hdfs dfs -copyFromLocal xxx /tmp/ 22/05/16 18:10:05 WARN hdfs.DataStreamer: DataStreamer Exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /tmp/qjj._COPYING_ could only be written to 0 of the 1 minReplication nodes. There are 4 datanode(s) running and 4 node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2102) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2673) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:872) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:550) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:523) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:991) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:869) at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:815) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1875) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2675) at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1499) at org.apache.hadoop.ipc.Client.call(Client.java:1445) at org.apache.hadoop.ipc.Client.call(Client.java:1355) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116) at com.sun.proxy.$Proxy9.addBlock(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:497) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157) at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359) at com.sun.proxy.$Proxy10.addBlock(Unknown Source) at org.apache.hadoop.hdfs.DFSOutputStream.addBlock(DFSOutputStream.java:1085) at org.apache.hadoop.hdfs.DataStreamer.locateFollowingBlock(DataStreamer.java:1865) at org.apache.hadoop.hdfs.DataStreamer.nextBlockOutputStream(DataStreamer.java:1668) at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:716) copyFromLocal: File /tmp/qjj._COPYING_ could only be written to 0 of the 1 minReplication nodes. There are 4 datanode(s) running and 4 node(s) are excluded in this operation. # 服务端日志 上午10点15:18.249分 INFO BlockPlacementPolicy Not enough replicas was chosen. Reason:{NOT_ENOUGH_STORAGE_SPACE=3} 上午10点15:18.249分 WARN BlockPlacementPolicy Failed to place enough replicas, still in need of 2 to reach 3 (unavailableStorages=[], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy and org.apache.hadoop.net.NetworkTopology 上午10点15:18.250分 WARN BlockPlacementPolicy Failed to place enough replicas, still in need of 2 to reach 3 (unavailableStorages=[DISK], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy and org.apache.hadoop.net.NetworkTopology 上午10点15:18.250分 WARN BlockStoragePolicy Failed to place enough replicas: expected size is 2 but only 0 storage types can be selected (replication=3, selected=[], unavailable=[DISK, ARCHIVE], removed=[DISK, DISK], policy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}) 上午10点15:18.250分 WARN BlockPlacementPolicy Failed to place enough replicas, still in need of 2 to reach 3 (unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=false) All required storage types are unavailable: unavailableStorages=[DISK, ARCHIVE], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}执行hdfs dfsadmin -report结果发现DFS Used%超过了100%
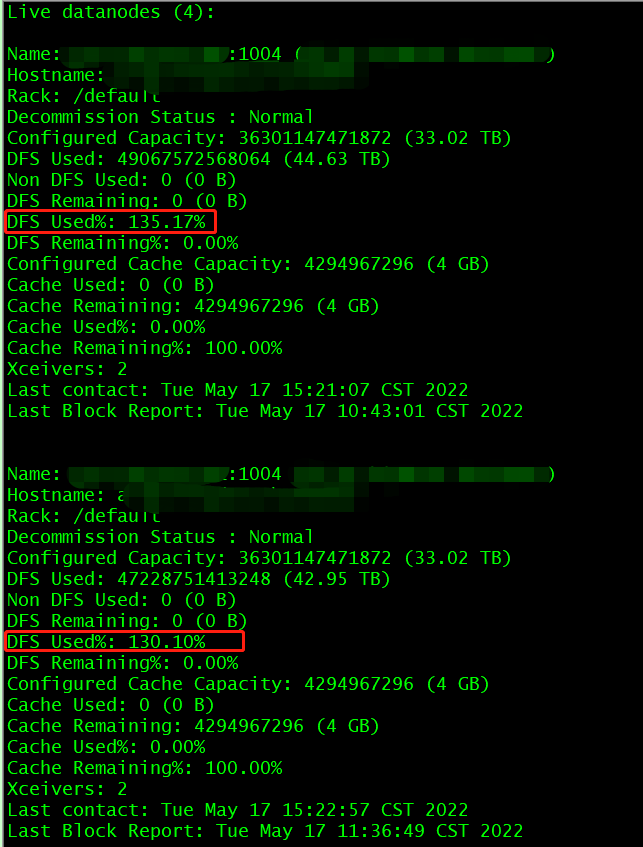
原因:dfs.datanode.du.reserved参数被同事修改成了3072GB,这个参数是指该DataNode上单个数据盘预留的空间,单节点上有8块盘,每块少3T,总共少了24T,DN节点存储容量也随之下降。修改后,磁盘剩余空间不足3072G,则该DataNode无法写入。
解决:降低dfs.datanode.du.reserved,重启DN节点。HDFS无法上传文件,报错DataNode被排除
22/08/15 18:05:53 WARN hdfs.DataStreamer: DataStreamer Exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /tmp/hive-e.log._COPYING_ could only be written to 0 of the 1 minReplication nodes. There are 3 datanode(s) running and 3 node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:2219) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.chooseTargetForNewBlock(FSDirWriteFileOp.java:294) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:2789) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:892) 22/08/15 19:40:38 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted =false, remoteHostTrusted = false 22/08/15 19:40:38 INFO hdfs.DataStreamer: Exception in createBlockOutputStream blk_1074772338_1031527 ...... java.io.IOException: Invalid token in javax.security.sasl.qop: at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.DataTransferSaslUtil.readSaslMessage(DataTransferSaslUtil.java:220)之前遇到过因DataNode无可用空间导致的DataNode被排除进而无法写入数据,但这次不同,这次多了”not support SASL data transfer”
2022-08-15 17:59:47,338 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Failed to read expected SASL data transfer protection handshake from client at /client-ip:42960. Perhaps the client is running an older version of Hadoop which does not support SASL data transfer protec tion org.apache.hadoop.hdfs.protocol.datatransfer.sasl.InvalidMagicNumberException: Received 1c50ed instead of deadbeef from client. at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferServer.doSaslHandshake(SaslDataTransferServer.java:372) at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferServer.getSaslStreams(SaslDataTransferServer.java:306) at org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferServer.receive(SaslDataTransferServer.java:133) at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:234) at java.lang.Thread.run(Thread.java:748) 2022-08-15 18:00:20,122 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Failed to read expected SASL data transfer protection handshake from client at /client-ip:43638. Perhaps the client is running an older version of Hadoop which does not support SASL data transfer protec tion org.apache.hadoop.hdfs.protocol.datatransfer.sasl.InvalidMagicNumberException: Received 1c50ed instead of deadbeef from client.原因:As of version 2.6.0, SASL can be used to authenticate the data transfer protocol. In this configuration, it is no longer required for secured clusters to start the DataNode as root using jsvc and bind to privileged ports. To enable SASL on data transfer protocol, set dfs.data.transfer.protection in hdfs-site.xml, set a non-privileged port for dfs.datanode.address, set dfs.http.policy to HTTPS_ONLY and make sure the HADOOP_SECURE_DN_USER environment variable is not defined. Note that it is not possible to use SASL on data transfer protocol if dfs.datanode.address is set to a privileged port. This is required for backwards-compatibility reasons.
解决:hdfs-site.xml增加dfs.data.transfer.protection=integrity
Hive相关
HiveMetaStore状态不良导DDLSQL耗时200s以上
HMS进程报错:hive metastore server Failed to sync requested HMS notifications up to the event ID xxx
原因分析:查看sentry异常CounterWait源码发现传递的id比currentid大导致一直等待超时,超时时间默认为200s(sentry.notification.sync.timeout.ms)。
开启了hdfs-sentry acl同步后,hdfs,sentry,HMS三者间权限同步的消息处理。当突然大批量的目录权限消息需要处理,后台线程处理不过来,消息积压滞后就会出现这个异常。这个异常不影响集群使用,只是会导致create,drop table慢需要等200s,这样等待也是为了追上最新的id。我们这次同时出现了HMS参与同步消息处理的线程被异常退出,导致sentry的sentry_hms_notification_id表数据一直没更新,需要重启HMS。如果积压了太多消息,让它慢慢消费处理需要的时间太长,可能一直追不上,这时可以选择丢掉这些消息。
解决:
①可以通过设置sentry.notification.sync.timeout.ms参数调小超时时间,减小等待时间,积压不多的话可以让它自行消费处理掉。
②丢掉未处理的消息,在sentry的sentry_hms_notification_id表中插入一条最大值(等于当前消息的id,从notification_sequence表中获取) ,重启sentry服务。(notification_log 表存储了消息日志信息)HBase外部表报Unexpected end-of-input
起因:使用Hive创建HBase外部表时正常,但使用HBase外部表时报Unexpected end-of-input: was expecting closing
分析过程:翻阅源码部分发现异常是在解析外部表创建JSON时发生,于是对比建表语句和Hive元数据库中的TABLE_PARAMS表信息得到原因
原因:创建hbase外部表catalog太长导致schema太长,而hive元数据表mysql里的table_params字段param_value字段类型是varchar(4000)建表时由于schema太长,超过4000字符的部分被截断。而使用该表的时候会读元数据,但因为元数据不完整而报错。
解决:
①分多次建表
②改varchar(4000)为longtext然后重建表(影响无法评估,没尝试)Hive和Spark查询Hive表报java.net.UnknownHostException: nameservice1
分析:由于机器HDFS HA配置发生变动,关掉了高可用,所以nameservice变成了ip:8020,报这个错,首先检查了/etc/hadoop/conf/hdfs-site.xml里面无dfs.nameservices配置,证明配置文件没问题。使用hivecli,desc formatted某几张表,发现表的LOCATION均为hdfs://nameservice1/xx 找到了问题的原因,元数据错误,所以需要去Hive元数据库批量修改元数据。
解决:连接到Hive metastore元数据库,批量修改LOCATION:
update hive.SDS set LOCATION=concat(“hdfs://ip:8020”,substring(LOCATION,20,length(LOCATION)-19)) where LOCATION like “hdfs://nameservice1%”;
update hive.DBS set DB_LOCATION_URI=concat(“hdfs://ip:8020”,substring(DB_LOCATION_URI,20,length(DB_LOCATION_URI)-19)) where DB_LOCATION_URI like “hdfs://nameservice1%”;
无需重启服务即可生效,问题解决。SIMPLE authentication is not enabled. Available:[TOKEN, KERBEROS]
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security.AccessControlException: SIMPLE authentication is not enabled. Available:[TOKEN, KERBEROS] at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:651) at org.apache.hadoop.hive.ql.session.SessionState.beginStart(SessionState.java:591)增加如下几个参数:
<property> <name>hive.server2.authentication</name> <value>KERBEROS</value> </property> <name>hive.metastore.kerberos.principal</name> <name>hive.metastore.kerberos.keytab.file</name> <name>hive.server2.authentication.kerberos.principal</name> <name>hive.server2.authentication.kerberos.keytab</name>Kerberos集群Hive客户端无法连接集群org.apache.thrift.transport.TTransportException: null
2022-07-25T19:24:37,992 WARN [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it. org.apache.thrift.transport.TTransportException: null at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readStringBody(TBinaryProtocol.java:380) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:230) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_set_ugi(ThriftHiveMetastore.java:4787) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.set_ugi(ThriftHiveMetastore.java:4773) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:534) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:224) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.<init>(SessionHiveMetaStoreClient.java:94) ~[hive-exec-3.1.2.jar:3.1.2] at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[?:1.8.0_252] at java.lang.reflect.Constructor.newInstance(Constructor.java:423) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.utils.JavaUtils.newInstance(JavaUtils.java:84) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:95) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:148) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:119) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactory.createMetaStoreClient(SessionHiveMetaStoreClientFactory.java:49) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:4324) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:4390) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:4370) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4626) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.<init>(Hive.java:437) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.create(Hive.java:377) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getInternal(Hive.java:357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.get(Hive.java:333) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.HiveMaterializedViewsRegistry.init(HiveMaterializedViewsRegistry.java:133) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:755) ~[hive-cli-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) ~[hive-cli-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.util.RunJar.run(RunJar.java:323) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.util.RunJar.main(RunJar.java:236) ~[hadoop-common-3.2.1.jar:?] 2022-07-25T19:24:37,993 INFO [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: Connected to metastore. 2022-07-25T19:24:37,993 INFO [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.RetryingMetaStoreClient: RetryingMetaStoreClient proxy=class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient ugi=xxx@REALM_NAME (auth:KERBEROS) retries=1 delay=1 lifetime=0 2022-07-25T19:24:38,217 WARN [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 1s. getAllFunctions org.apache.thrift.transport.TTransportException: null at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:429) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:318) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:219) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_all_functions(ThriftHiveMetastore.java:4357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_all_functions(ThriftHiveMetastore.java:4345) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.getAllFunctions(HiveMetaStoreClient.java:2861) ~[hive-exec-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:212) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2773) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4626) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.<init>(Hive.java:437) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.create(Hive.java:377) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getInternal(Hive.java:357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.get(Hive.java:333) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.HiveMaterializedViewsRegistry.init(HiveMaterializedViewsRegistry.java:133) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:755) ~[hive-cli-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) ~[hive-cli-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.util.RunJar.run(RunJar.java:323) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.util.RunJar.main(RunJar.java:236) ~[hadoop-common-3.2.1.jar:?] 2022-07-25T19:24:39,217 INFO [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.RetryingMetaStoreClient: RetryingMetaStoreClient trying reconnect as xxx@REALM_NAME (auth:KERBEROS) 2022-07-25T19:24:39,221 DEBUG [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: Unable to shutdown metastore client. Will try closing transport directly. org.apache.thrift.transport.TTransportException: java.net.SocketException: Broken pipe (Write failed) at org.apache.thrift.transport.TIOStreamTransport.flush(TIOStreamTransport.java:161) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.TServiceClient.sendBase(TServiceClient.java:73) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.TServiceClient.sendBaseOneway(TServiceClient.java:66) ~[hive-exec-3.1.2.jar:3.1.2] at com.facebook.fb303.FacebookService$Client.send_shutdown(FacebookService.java:436) ~[libfb303-0.9.3.jar:?] at com.facebook.fb303.FacebookService$Client.shutdown(FacebookService.java:430) ~[libfb303-0.9.3.jar:?] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.close(HiveMetaStoreClient.java:591) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.reconnect(HiveMetaStoreClient.java:366) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient$1.run(RetryingMetaStoreClient.java:187) ~[hive-exec-3.1.2.jar:3.1.2] at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_252] at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_252] at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1732) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:183) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2773) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4626) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.<init>(Hive.java:437) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.create(Hive.java:377) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getInternal(Hive.java:357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.get(Hive.java:333) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.HiveMaterializedViewsRegistry.init(HiveMaterializedViewsRegistry.java:133) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:755) ~[hive-cli-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) ~[hive-cli-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.util.RunJar.run(RunJar.java:323) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.util.RunJar.main(RunJar.java:236) ~[hadoop-common-3.2.1.jar:?] Caused by: java.net.SocketException: Broken pipe (Write failed) at java.net.SocketOutputStream.socketWrite0(Native Method) ~[?:1.8.0_252] at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:111) ~[?:1.8.0_252] at java.net.SocketOutputStream.write(SocketOutputStream.java:155) ~[?:1.8.0_252] at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82) ~[?:1.8.0_252] at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140) ~[?:1.8.0_252] at org.apache.thrift.transport.TIOStreamTransport.flush(TIOStreamTransport.java:159) ~[hive-exec-3.1.2.jar:3.1.2] ... 34 more 2022-07-25T19:24:39,221 WARN [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] transport.TIOStreamTransport: Error closing output stream. java.net.SocketException: Socket closed at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:118) ~[?:1.8.0_252] at java.net.SocketOutputStream.write(SocketOutputStream.java:155) ~[?:1.8.0_252] at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82) ~[?:1.8.0_252] at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140) ~[?:1.8.0_252] at java.io.FilterOutputStream.close(FilterOutputStream.java:158) ~[?:1.8.0_252] at org.apache.thrift.transport.TIOStreamTransport.close(TIOStreamTransport.java:110) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.transport.TSocket.close(TSocket.java:235) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.close(HiveMetaStoreClient.java:599) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.reconnect(HiveMetaStoreClient.java:366) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient$1.run(RetryingMetaStoreClient.java:187) ~[hive-exec-3.1.2.jar:3.1.2] at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_252] at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_252] at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1732) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:183) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2773) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4626) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.<init>(Hive.java:437) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.create(Hive.java:377) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getInternal(Hive.java:357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.get(Hive.java:333) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.HiveMaterializedViewsRegistry.init(HiveMaterializedViewsRegistry.java:133) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:755) ~[hive-cli-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) ~[hive-cli-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.util.RunJar.run(RunJar.java:323) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.util.RunJar.main(RunJar.java:236) ~[hadoop-common-3.2.1.jar:?] 2022-07-25T19:24:39,221 INFO [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: Closed a connection to metastore, current connections: 0 2022-07-25T19:24:39,221 INFO [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: Trying to connect to metastore with URI thrift://xxxxxx:9083 2022-07-25T19:24:39,221 INFO [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: Opened a connection to metastore, current connections: 1 2022-07-25T19:24:39,230 WARN [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it. org.apache.thrift.transport.TTransportException: null at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readStringBody(TBinaryProtocol.java:380) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:230) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_set_ugi(ThriftHiveMetastore.java:4787) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.set_ugi(ThriftHiveMetastore.java:4773) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:534) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.reconnect(HiveMetaStoreClient.java:379) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient$1.run(RetryingMetaStoreClient.java:187) ~[hive-exec-3.1.2.jar:3.1.2] at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_252] at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_252] at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1732) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:183) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2773) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4626) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.<init>(Hive.java:437) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.create(Hive.java:377) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getInternal(Hive.java:357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.get(Hive.java:333) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.HiveMaterializedViewsRegistry.init(HiveMaterializedViewsRegistry.java:133) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:755) ~[hive-cli-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) ~[hive-cli-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.util.RunJar.run(RunJar.java:323) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.util.RunJar.main(RunJar.java:236) ~[hadoop-common-3.2.1.jar:?] 2022-07-25T19:24:39,231 INFO [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metastore.HiveMetaStoreClient: Connected to metastore. 2022-07-25T19:24:39,245 WARN [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4629) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.<init>(Hive.java:437) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.create(Hive.java:377) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getInternal(Hive.java:357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.get(Hive.java:333) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.HiveMaterializedViewsRegistry.init(HiveMaterializedViewsRegistry.java:133) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:755) ~[hive-cli-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) ~[hive-cli-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.util.RunJar.run(RunJar.java:323) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.util.RunJar.main(RunJar.java:236) ~[hadoop-common-3.2.1.jar:?] Caused by: org.apache.thrift.transport.TTransportException at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:429) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:318) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:219) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_all_functions(ThriftHiveMetastore.java:4357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_all_functions(ThriftHiveMetastore.java:4345) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.getAllFunctions(HiveMetaStoreClient.java:2861) ~[hive-exec-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:212) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2773) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4626) ~[hive-exec-3.1.2.jar:3.1.2] ... 15 more Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. 2022-07-25T19:24:39,245 ERROR [0824f8ba-8eaf-494d-9ca4-d430d4d0376f main] metadata.HiveMaterializedViewsRegistry: Problem connecting to the metastore when initializing the view registry org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:281) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.<init>(Hive.java:437) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.create(Hive.java:377) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.getInternal(Hive.java:357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.get(Hive.java:333) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.HiveMaterializedViewsRegistry.init(HiveMaterializedViewsRegistry.java:133) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:755) ~[hive-cli-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) ~[hive-cli-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.util.RunJar.run(RunJar.java:323) ~[hadoop-common-3.2.1.jar:?] at org.apache.hadoop.util.RunJar.main(RunJar.java:236) ~[hadoop-common-3.2.1.jar:?] Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4629) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] ... 13 more Caused by: org.apache.thrift.transport.TTransportException at org.apache.thrift.transport.TIOStreamTransport.read(TIOStreamTransport.java:132) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.transport.TTransport.readAll(TTransport.java:86) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readAll(TBinaryProtocol.java:429) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readI32(TBinaryProtocol.java:318) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.protocol.TBinaryProtocol.readMessageBegin(TBinaryProtocol.java:219) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:77) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_all_functions(ThriftHiveMetastore.java:4357) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_all_functions(ThriftHiveMetastore.java:4345) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.getAllFunctions(HiveMetaStoreClient.java:2861) ~[hive-exec-3.1.2.jar:3.1.2] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:212) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_252] at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_252] at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_252] at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_252] at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2773) ~[hive-exec-3.1.2.jar:3.1.2] at com.sun.proxy.$Proxy34.getAllFunctions(Unknown Source) ~[?:?] at org.apache.hadoop.hive.ql.metadata.Hive.getAllFunctions(Hive.java:4626) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.reloadFunctions(Hive.java:293) ~[hive-exec-3.1.2.jar:3.1.2] at org.apache.hadoop.hive.ql.metadata.Hive.registerAllFunctionsOnce(Hive.java:276) ~[hive-exec-3.1.2.jar:3.1.2] ... 13 more看到关键日志“Problem connecting to the metastore when initializing the view registry”,证明Metastore连接出现问题。
原因:hive.metastore.sasl.enabled参数未设置
解决方式:Hive客户端增加hive.metastore.sasl.enabled参数并设置为true,同时由于集群是Kerberos认证的,并且sasl开启后认证类型只能是Kerberos,所以为保证能正常连接Metastore,Hive客户端配置还需要这几个参数<property> <name>hive.server2.authentication</name> <value>KERBEROS</value> </property> <name>hive.metastore.kerberos.principal</name> <name>hive.metastore.kerberos.keytab.file</name> <!-- <name>hive.server2.authentication.kerberos.principal</name> --> <!-- <name>hive.server2.authentication.kerberos.keytab</name> -->HiveClient正常退出时,标准输出如下warn(会影响hive -e将结果导出文件的情况)
WARN: The method class org.apache.commons.logging.impl.SLF4JLogFactory#release() was invoked. WARN: Please see http://www.slf4j.org/codes.html#release for an explanation.原因: hive中引用了HBase的jar包jcl-over-slf4j-1.7.30.jar 会导致输出这个WARN
解决:
方法1:hive client启动去掉hbase classpath引入: 修改hiveclient启动脚本 vim $(which hive) 修改参数SKIP_HBASECP=true
方法2:如果必须引入HBASE的Classpath,则修改jcl-over-slf4j-1.7.30.jar源码去掉打印Map端聚合或MapJoin导致MR内存溢出
2023-03-28 08:49:01,202 Stage-1 map = 100%, reduce = 95%, Cumulative CPU 24417.19 sec 2023-03-28 08:49:02,228 Stage-1 map = 100%, reduce = 99%, Cumulative CPU 24506.89 sec 2023-03-28 08:49:04,275 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 24532.72 sec MapReduce Total cumulative CPU time: 0 days 6 hours 48 minutes 52 seconds 720 msec Ended Job = job_1676281359678_1134544 SLF4J: Found binding in [jar:file:/opt/apps/ecm/service/hive/3.1.2-hadoop3.1-1.3.1/package/apache-hive-3.1.2-hadoop3.1-1.3.1-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] 2023-03-28 08:49:18 Processing rows: 300000 Hashtable size: 299999 Memory usage: 242011504 percentage: 0.253 2023-03-28 08:49:19 Processing rows: 500000 Hashtable size: 499999 Memory usage: 307602344 percentage: 0.322 2023-03-28 08:49:20 Processing rows: 700000 Hashtable size: 699999 Memory usage: 504480144 percentage: 0.528 2023-03-28 08:49:22 Processing rows: 900000 Hashtable size: 899999 Memory usage: 691092576 percentage: 0.724 Execution failed with exit status: 3 Obtaining error information Task failed! Task ID: Stage-12 Logs: FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.mr.MapredLocalTask原因:开启了set hive.auto.convert.join=true; 开启自动mapjoin,右表写入内存,内存不足导致任务失败
解决:关闭自动mapjoin设置set hive.auto.convert.join=false;Hive开启自动获取表上次访问时间(lastAccessTime)
<property> <name>hive.security.authorization.sqlstd.confwhitelist.append</name> <!-- <value>hive\.exec\.pre\.hooks</value> --> <value>hive\.*</value> </property> <property> <name>hive.exec.pre.hooks</name> <value>org.apache.hadoop.hive.ql.hooks.UpdateInputAccessTimeHook$PreExec</value> </property>原理:Hive内部已实现相应hook,通过hook实现。
可能遇到的异常:2023-08-02T19:29:27,608 INFO [fee06e51-d86f-4686-acf1-d4be127aebab main] reexec.ReOptimizePlugin: ReOptimization: retryPossible: false 2023-08-02T19:29:27,609 ERROR [fee06e51-d86f-4686-acf1-d4be127aebab main] ql.Driver: FAILED: Hive Internal Error: org.apache.hadoop.hive.ql.metadata.InvalidTableException(Table not found _dummy_table) org.apache.hadoop.hive.ql.metadata.InvalidTableException: Table not found _dummy_table at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java:1135) at org.apache.hadoop.hive.ql.metadata.Hive.getTable(Hive.java:1105) at org.apache.hadoop.hive.ql.hooks.UpdateInputAccessTimeHook$PreExec.run(UpdateInputAccessTimeHook.java:64) at org.apache.hadoop.hive.ql.HookRunner.invokeGeneralHook(HookRunner.java:296) at org.apache.hadoop.hive.ql.HookRunner.runPreHooks(HookRunner.java:273) at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:2364) at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:2099) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1797) at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1791) at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:157) at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:218) at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:239) at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:188) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:402) at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:335) at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:787) at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759) at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:683) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:323) at org.apache.hadoop.util.RunJar.main(RunJar.java:236) 2023-08-02T19:29:27,609 INFO [fee06e51-d86f-4686-acf1-d4be127aebab main] ql.Driver: Completed executing command(queryId=user_20230802192923_daf65682-5164-45ce-80f4-51e79c094973); Time taken: 1.045 seconds解决:单独提取源码中的org.apache.hadoop.hive.ql.hooks.UpdateInputAccessTimeHook类,增加异常处理逻辑,修改后代码(使用方法在注释):UpdateInputAccessTimeHook.java
- Hive开启表统计信息
hive.stats.autogather=true则会开启表统计信息如下
不建议在全局参数设置该参数,会影响写入性能,但可以针对部分表单独设置last_modified_by xxxxx last_modified_time 1690965029 numFiles 11 numRows 10 rawDataSize 34 totalSize 2433 transient_lastDdlTime 1690965096ALTER TABLE table_name SET TBLPROPERTIES ('hive.stats.autogather'='true');
Yarn相关
应用提交报Retrying connect to server 0.0.0.0
原因:应用没有认到yarn-site.xml或者yarn-site.xml配置不正确
解决:①指定HADOOP_CONF_DIR ②确认yarn-site.xml<property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property>内存不足Container退出
报错:Diagnostics: Container [pid=91869,containerID=container_e23_1574819880505_43157_01_000001] is running beyond physical memory limits. Current usage: 9.0 GB of 9 GB physical memory used; 12.8 GB of 18.9 GB virtual memory used. Killing container.Dump of the process-tree for container_e23_1574819880505_43157_01_000001
分析:”physical memory used”为物理内存占用(应用已占满9G),”virtual memory used”为虚拟内存占用,18.9GB是取决于yarn.nodemanager.vmem-pmem-ratio(yarn-site.xml中设置的虚拟内存和物理内存比例,默认2.1),报错是因为物理内存不足,是任务设置的内存少了
解决思路:
①如果资源充足,增加任务并行度分担任务负载
②增大任务可用资源(注意不要超过单台NM可分配上限yarn.scheduler.maximum-allocation-mb的值)
③适当增大yarn.nodemanager.vmem-pmem-ratio,适当调高虚拟内存比例
④[不建议]取消内存的检查:在yarn-site.xml或者程序中中设置yarn.nodemanager.vmem-check-enabled为falseyarn logs无法正常输出日志

原因:yarn.nodemanager.remote-app-log-dir要设置为/tmp/logs 不能修改为其他盘
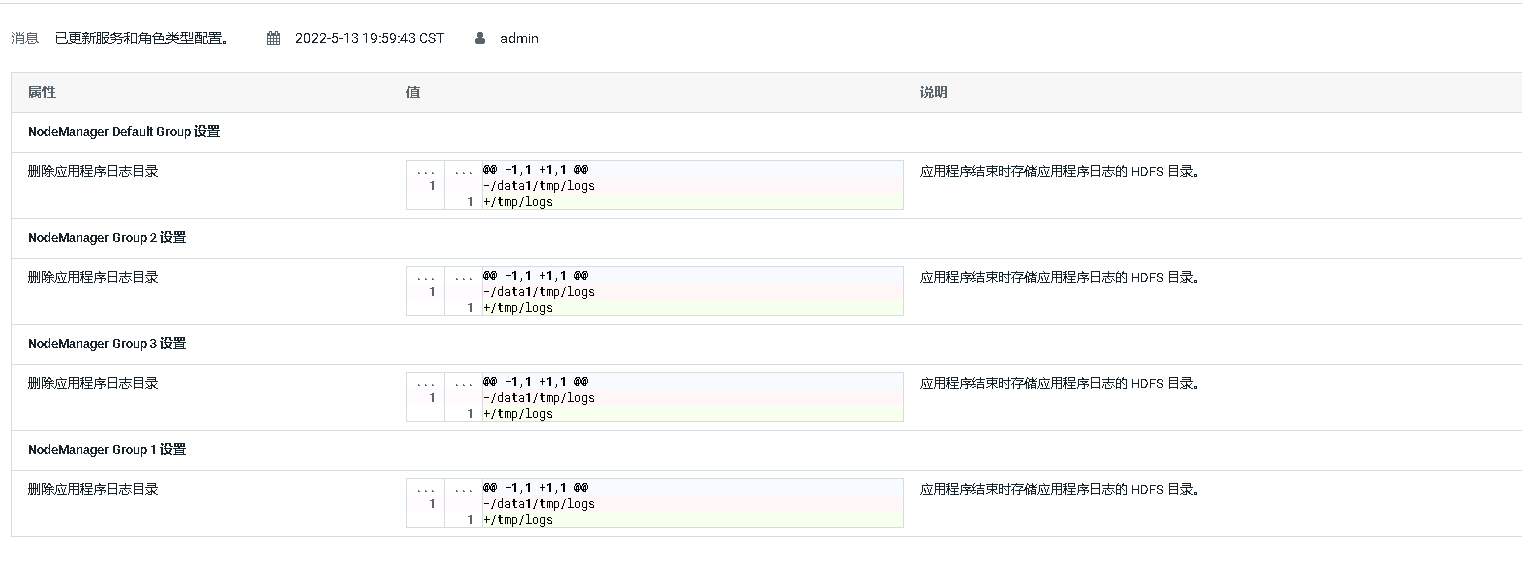
修改后历史Application查看日志恢复正常。CapacityScheduler新增队列
参考YARN-CapacityScheduler
新增队列root.analyse<property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,analyse</value> <description>The queues at the this level (root is the root queue).</description> </property> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>40</value> <description>Default queue target capacity.</description> </property> <property> <name>yarn.scheduler.capacity.root.analyse.capacity</name> <value>60</value> <description>analyse queue target capacity.</description> </property> <property> <name>yarn.scheduler.capacity.root.default.user-limit-factor</name> <value>0.8</value> <description>Default queue user limit a percentage from 0.0 to 1.0.</description> </property> <property> <name>yarn.scheduler.capacity.root.analyse.user-limit-factor</name> <value>1.5</value> <description>The multiple of the queue capacity which can be configured to allow a single user to acquire more resources. Default is 1,it can be more than 1</description> <!-- user-limit-factor是限制单个用户可以占用这个队列资源的倍数 可以大于1--> </property> <property> <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> <value>40</value> <description>The maximum capacity of the default queue.</description> </property> <property> <name>yarn.scheduler.capacity.root.analyse.maximum-capacity</name> <value>-1</value> <description>The maximum capacity of the analyse queue is 100 percent.</description> </property> <property> <name>yarn.scheduler.capacity.root.default.state</name> <value>RUNNING</value> <description>The state of the default queue. State can be one of RUNNING or STOPPED.</description> </property> <property> <name>yarn.scheduler.capacity.root.analyse.state</name> <value>RUNNING</value> <description>The state of the analyse queue. State can be one of RUNNING or STOPPED.</description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_submit_applications</name> <value>*</value> <description>The ACL of who can submit jobs to the default queue.</description> </property> <property> <name>yarn.scheduler.capacity.root.analyse.acl_submit_applications</name> <value>*</value> <description>The ACL of who can submit jobs to the default queue.</description> </property> <property> <name>yarn.scheduler.capacity.root.default.acl_administer_queue</name> <value>*</value> <description>The ACL of who can administer jobs on the default queue.</description> </property> <property> <name>yarn.scheduler.capacity.root.analyse.acl_administer_queue</name> <value>*</value> <description>The ACL of who can administer jobs on the default queue.</description> </property> <property> <name>yarn.scheduler.capacity.root.analyse.ordering-policy</name> <value>fair</value> <description>要基于每个队列指定排序策略,请将以下属性设置为 fifo或fair。默认设置为 fifo。</description> </property>设置使用的资源分配算法,该算法会同时考虑CPU以及内存资源,让所有Application的“主要资源占比”资源尽可能的均等。
<property> <name>yarn.scheduler.capacity.resource-calculator</name> <value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value> </property>刷新Queue,hive客户端指定队列analyse
yarn rmadmin -refreshQueues hive --hiveconf mapreduce.job.queuename=analyseYarn WebUI显示有LostNodes且这些LostNodes同时也在ActiveNodes中
原因: 未固定NodeManager端口,而是采用默认的随即端口,导致一个节点的NM可能有多种状态(LOST/Active).
解决: yarn-site.xml中添加配置yarn.nodemanager.address=${yarn.nodemanager.hostname}:8041,固定NM端口为8041
HBase相关
Couldn’t read snapshot info from hdfs:xx/hbase/.hbase-snapshot/xxx导致Master不可用
hbase shell执行list命令报ERROR: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
跟进Master日志看到Couldn’t read snapshot info from hdfs:xx/hbase/.hbase-snapshot/xxx,Master状态不可用
分析:由于HDFS的原因导致HBase的Snapshot文件丢失,详细看了一下,其他snapshot目录下有.snapshot以及data.manifest,而这个没有
操作:删除这个snapshot目录 重启HMaster
修复后scan操作又报Unknown table xxx,而且几乎所有表都不能scan
操作:首先想到的就是修复HBase元数据hbase hbck -fixMeta
修复后继续scan,报错ERROR: No server address listed in hbase:meta for region t1,,1536659773616.09db0b8b3b7f8cd81dde86c9f1e41306. containing row rowkey001: 1 time…
分析:查询hbase:meta表scan ‘hbase:meta’,{LIMIT=>10,FILTER=>”PrefixFilter(‘test_ray’)”}
发现表元数据中都没有regionserver的信息,正常情况是这样的: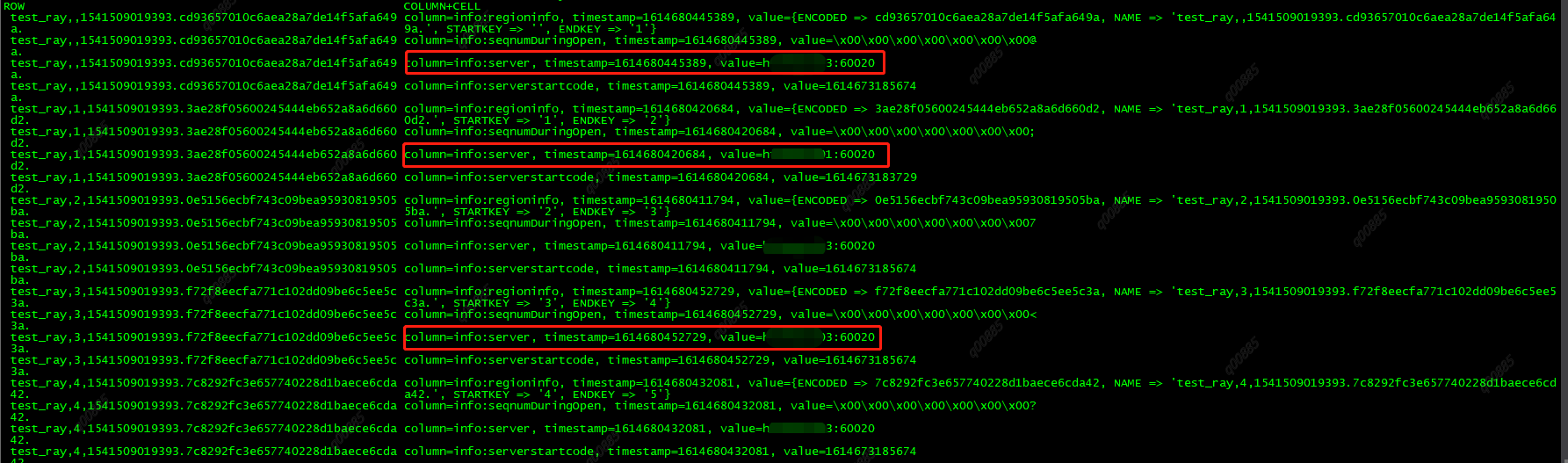
解决:重新对region分区:hbase hbck -fixAssignments 最终服务和数据均恢复正常HBaseRS节点宕机后服务受到很大影响,无法恢复服务
正常情况下,Zookeeper感知到RegionServer宕机之后,第一时间通知Master,Master首先会将这台RegionServer上所有Region关闭并移到其他RegionServer上(Region先重新分配),分配好后的Region要在各个节点逐渐初始化,Region在各个节点Open后可以读但暂时不能写入,OpenRegion后将HLog分发给其他RegionServer进行回放,整个过程通常不会很慢。完成之后再修改路由,客户端的读写才会完全恢复正常。
- 13:20 节点底层组件出现兼容性问题,出现宕机现象
- 13:21分 因主机没有路由导致hbase04节点 RS开始异常终止。Master通知其他RS检测到宕机的RS节点ZNode失效,其他节点开始获取到SplitWAL任务,开始进行WAL切分,为WAL重播做准备。
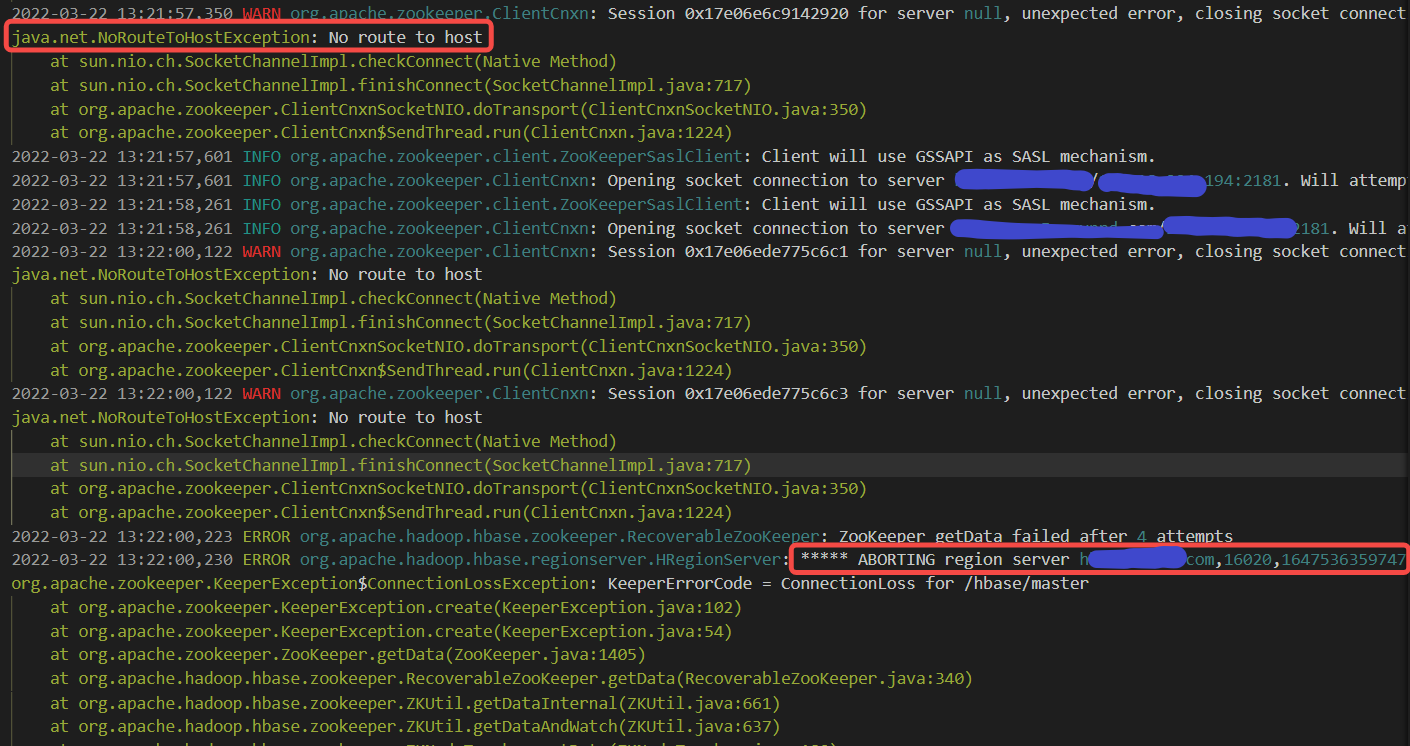

- 13:22开始 有表数据文件相关的Block丢失,访问超时后会放弃读取当前Block副本,转而读取该Block的其他副本元数据,再到对应的其他DN上读取数据,这也相应增加了HBase访问耗时,但影响不大。
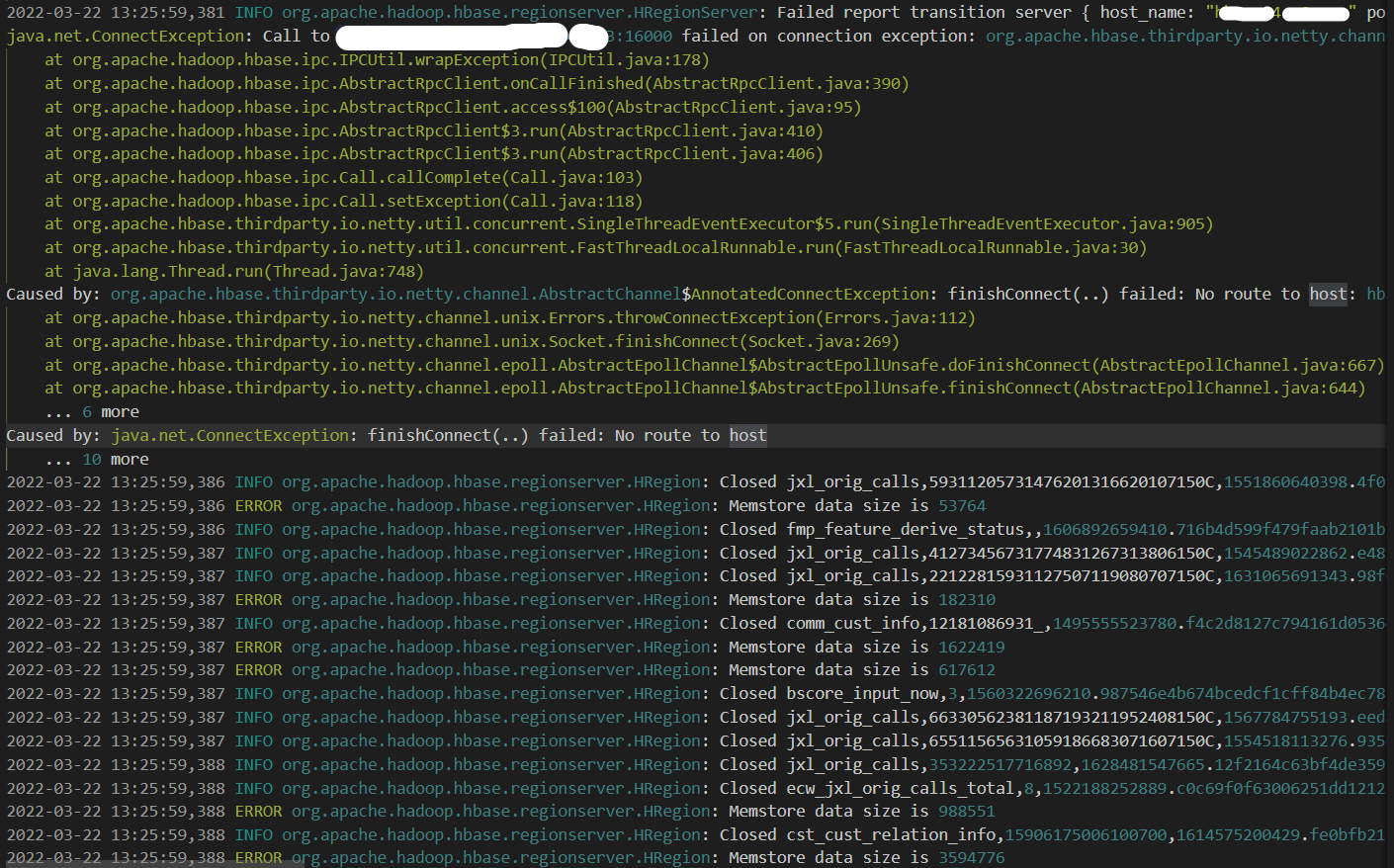
2022-03-22 13:21:19,967 WARN org.apache.hadoop.hdfs.DFSClient: Connection failure: Failed to connect to /xxx.xx.xxx.196:1004 for file /hbase/data/default/table_name/45e41a518ec793f5eef56e0e2ff7d37d/cri/4347398d03a84cfda88cd821d2ffe957_SeqId_8465_ for block BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1141233866_67493375:org.apache.hadoop.net.ConnectTimeoutException: 60000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=/xxx.xx.xxx.196:1004] org.apache.hadoop.net.ConnectTimeoutException: 60000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=/xxx.xx.xxx.196:1004] at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:534) at org.apache.hadoop.hdfs.DFSClient.newConnectedPeer(DFSClient.java:2854) ...... 2022-03-22 13:21:28,560 WARN org.apache.hadoop.hdfs.DataStreamer: Abandoning BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1141323985_67583494 2022-03-22 13:21:28,564 WARN org.apache.hadoop.hdfs.DataStreamer: Excluding datanode DatanodeInfoWithStorage[xxx.xx.xxx.196:1004,DS-e9e8ac9e-58a0-497f-9045-7e1a8eaa8fdb,DISK] - 13:25 宕机RS完成所有Region关闭下线。
从监控上看,宕机后,各RegionServer中的总区域暂时下降五分之一,13:40左右Region总数恢复到原始数量,而读写请求有大量失败,且读写吞吐量很低。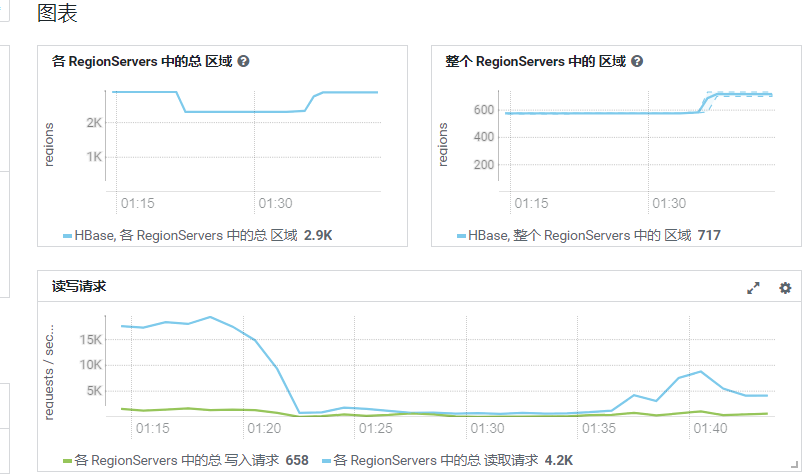
磁盘IO情况,各个节点都有一波高峰,原因是WAL重播:HBase写MemStore前先写WAL,WAL保存在HDFS,RS挂了,WAL会从HDFS读取,在RS各个节点进行重播,并写入到HFile,这也就是以上监控图表中磁盘IO出现峰值以及I、O峰值大小相近的原因。由于使用SSD作为存储,以上节点IO峰值不会对HBase服务的读写造成很大影响(以上IO读取量未达到SSD的读写速率上限),所以IO不是造成HBase阻塞和超时的根本原因。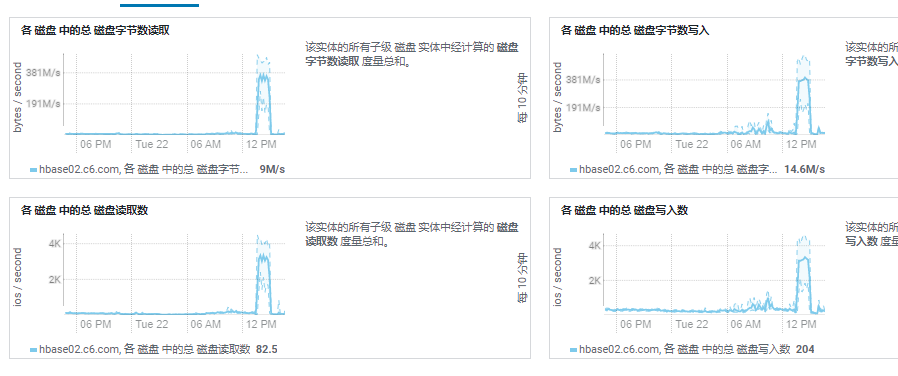
- 13:22各个节点开始有大量超时的客户端请求。
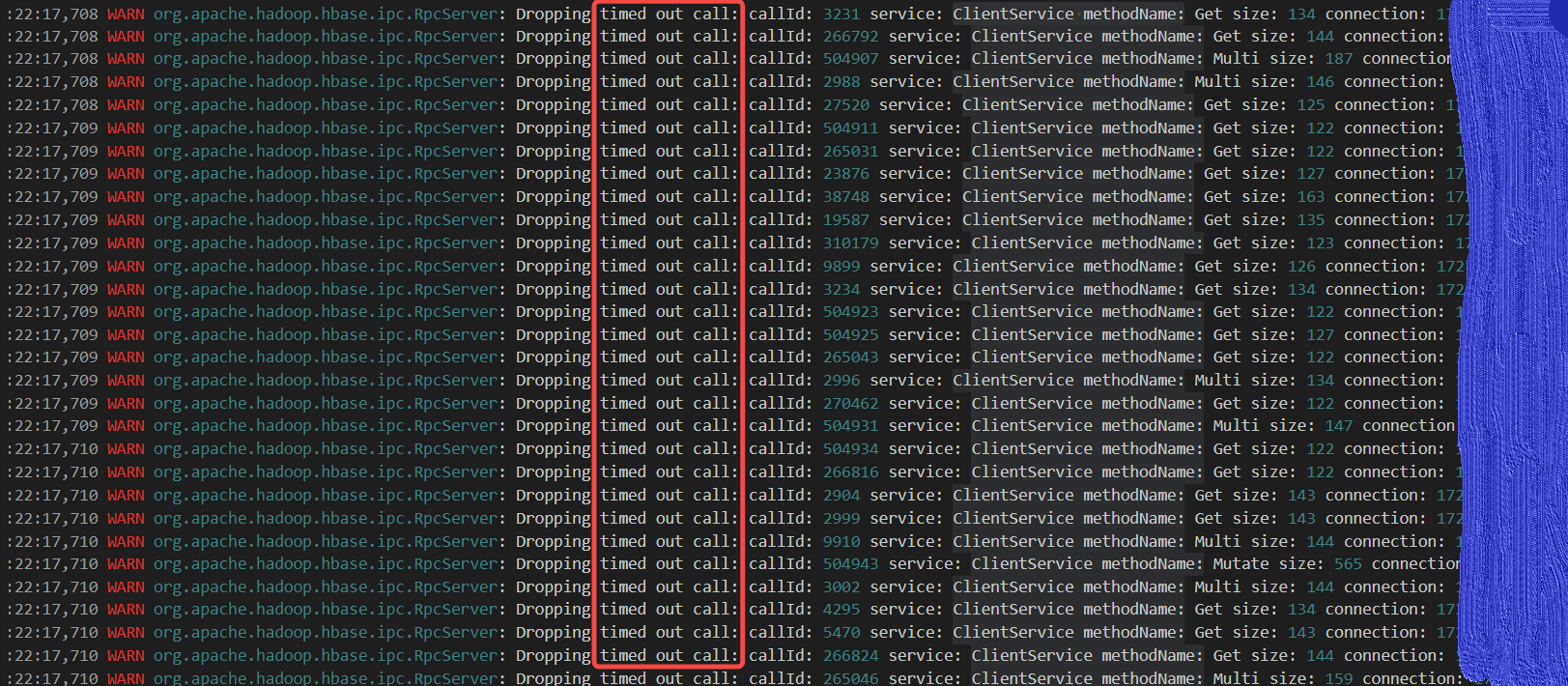
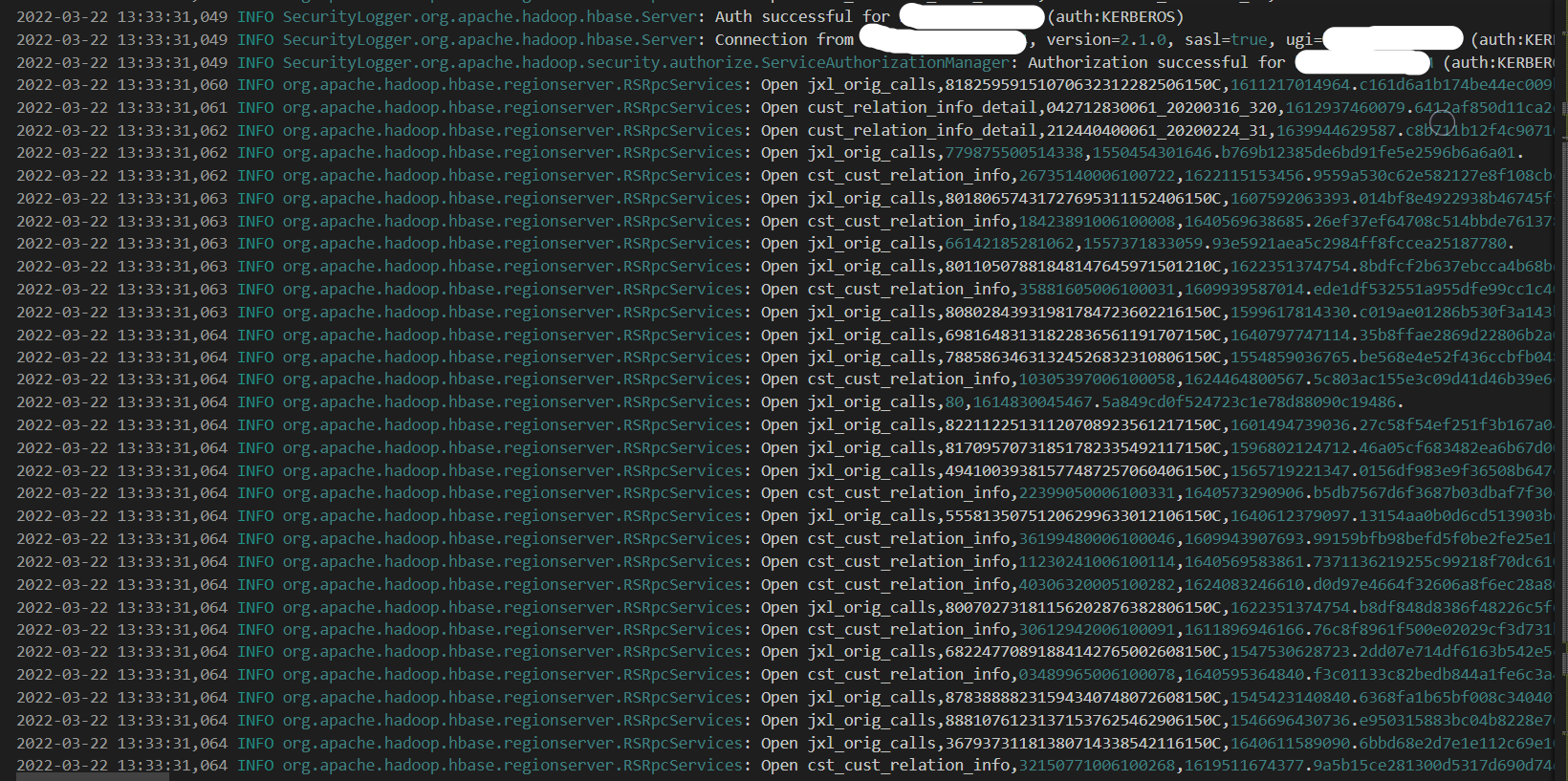
客户端开始频繁抛出org.apache.hadoop.hbase.NotServingRegionException - 13:33:31 其他节点开始打开hbase04下线的Region
由于HBase服务端Region无法提供服务,导致客户端出现请求队列积压: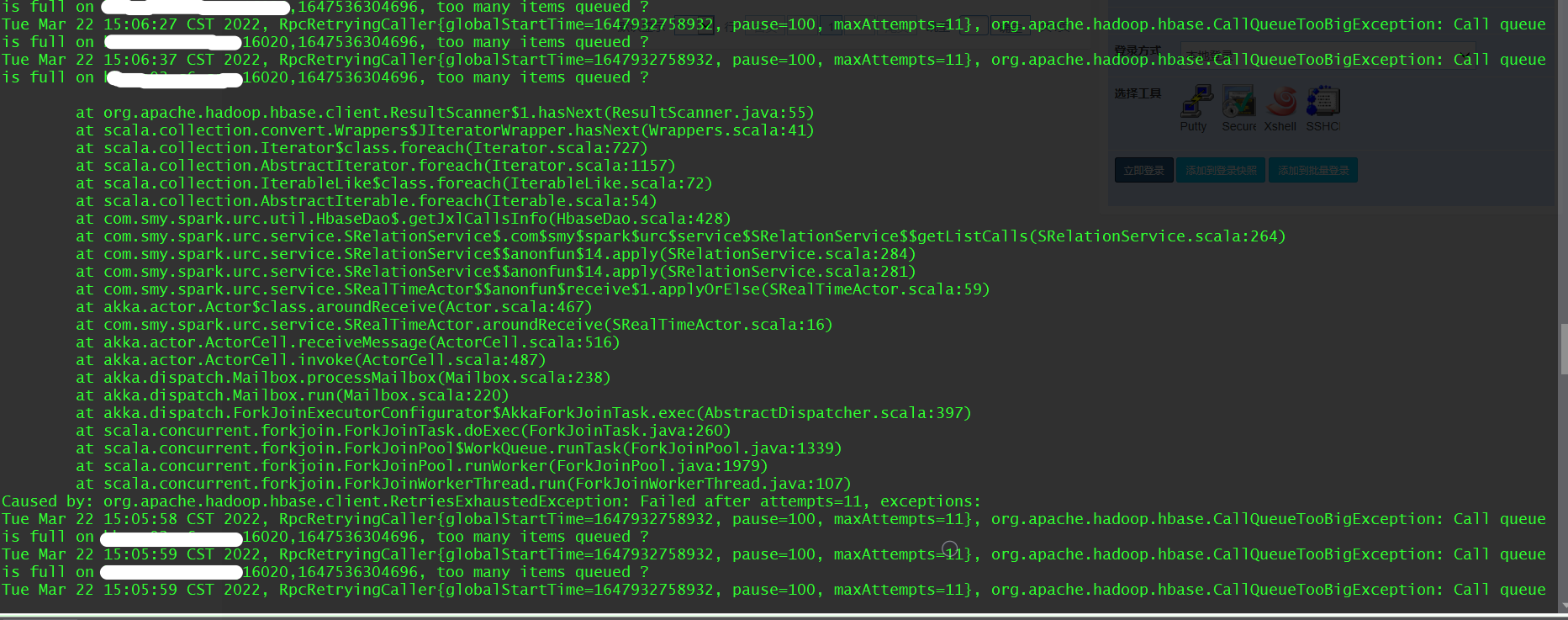
非高峰期(RS压力不是特别大的情况下)不需要调整call queue,如果进行调优可以适当增大hbase.regionserver.handler.count的值不超CPU Core数的2倍。
hbase.ipc.server.max.callqueue.length默认为10*hbase.regionserver.handler.count大小,可以适当增加callqueue大小,但对于本次事故的情况,增大callqueue治标不治本。 - 13:40 观察发现WEBUI上出现了长时间的RIT状态
- *RIT(Region-In-Transition):Region在进入Open,Close,Splitting,rebalance等操作前的一种状态**
同时发现RS WebUI上有大量Region初始化失败(Exception during region xxx initialization),但也有少部分正常Running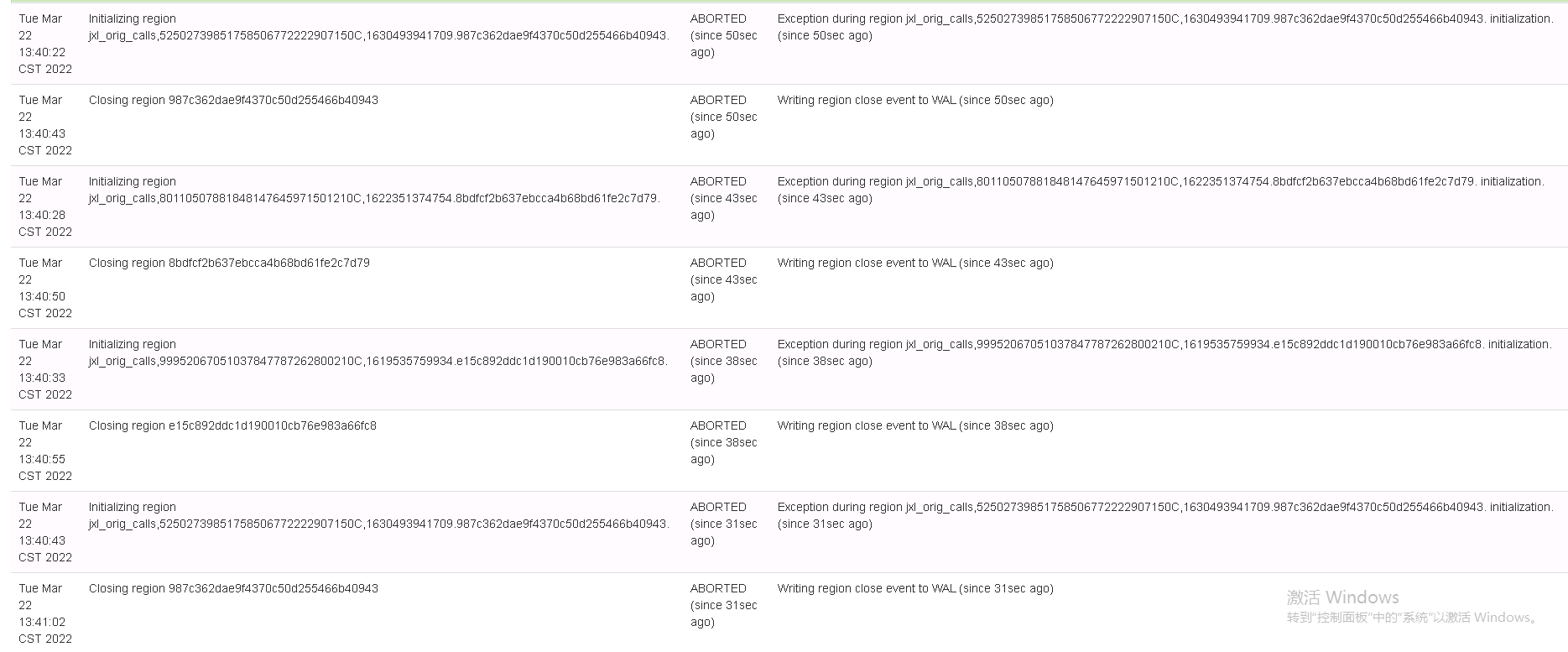
HLog组成:sequenceid是一个Store级别的自增序列号,非常重要,Region的数据恢复、WAL有序重播和HLog过期清除都要依赖sequenceid。2022-03-22 13:47:58,640 ERROR org.apache.hadoop.hbase.regionserver.HRegion: Could not initialize all stores for the region=jxl_orig_calls,77160950131161443142060106150C,1551868600765.249e28a92e9e4bc23b4adc1ce51fea03. 2022-03-22 13:47:58,640 WARN org.apache.hadoop.hbase.regionserver.HRegion: Failed initialize of region= jxl_orig_calls,77160950131161443142060106150C,1551868600765.249e28a92e9e4bc23b4adc1ce51fea03., starting to roll back memstore java.io.IOException: java.io.IOException: org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from file hdfs://nameservice1/hbase/archive/data/default/jxl_orig_calls/249e28a92e9e4bc23b4adc1ce51fea03/cri/a49f1498d37042e6b2c458ed8f25ebaa at org.apache.hadoop.hbase.regionserver.HRegion.initializeStores(HRegion.java:1095) at org.apache.hadoop.hbase.regionserver.HRegion.initializeRegionInternals(HRegion.java:943) at org.apache.hadoop.hbase.regionserver.HRegion.initialize(HRegion.java:899) Caused by: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074443230_702456 file=/hbase/archive/data/default/jxl_orig_calls/249e28a92e9e4bc23b4adc1ce51fea03/cri/a49f1498d37042e6b2c458ed8f25ebaa at org.apache.hadoop.hdfs.DFSInputStream.refetchLocations(DFSInputStream.java:880) ...... 2022-03-22 13:52:49,773 INFO org.apache.hadoop.hbase.regionserver.RSRpcServices: Open cst_cust_relation_info,30612942006100091,1611896946166.76c8f8961f500e02029cf3d731b8cdb5. 2022-03-22 13:52:49,792 WARN org.apache.hadoop.hdfs.DFSClient: No live nodes contain block BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074490423_749649 after checking nodes = [], ignoredNodes = null 2022-03-22 13:52:49,792 INFO org.apache.hadoop.hdfs.DFSClient: No node available for BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074490423_749649 file=/hbase/archive/data/default/cst_cust_relation_info/76c8f8961f500e02029cf3d731b8cdb5/cri/b9f57338b8ff42f891727ca1ef9ca378 2022-03-22 13:52:49,792 INFO org.apache.hadoop.hdfs.DFSClient: Could not obtain BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074490423_749649 from any node: No live nodes contain current block Block locations: Dead nodes: . Will get new block locations from namenode and retry... 2022-03-22 13:52:49,792 WARN org.apache.hadoop.hdfs.DFSClient: DFS chooseDataNode: got # 1 IOException, will wait for 1121.4412474110932 msec. 2022-03-22 13:52:50,914 INFO org.apache.hadoop.hdfs.DFSClient: No node available for BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074490423_749649 file=/hbase/archive/data/default/cst_cust_relation_info/76c8f8961f500e02029cf3d731b8cdb5/cri/b9f57338b8ff42f891727ca1ef9ca378 2022-03-22 13:52:50,914 INFO org.apache.hadoop.hdfs.DFSClient: Could not obtain BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074490423_749649 from any node: No live nodes contain current block Block locations: Dead nodes: . Will get new block locations from namenode and retry... org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074490423_749649 file=/hbase/archive/data/default/cst_cust_relation_info/76c8f8961f500e02029cf3d731b8cdb5/cri/b9f57338b8ff42f891727ca1ef9ca378 2022-03-22 13:53:05,772 ERROR org.apache.hadoop.hbase.regionserver.HRegion: Could not initialize all stores for the region=cst_cust_relation_info,30612942006100091,1611896946166.76c8f8961f500e02029cf3d731b8cdb5. 2022-03-22 13:53:05,772 WARN org.apache.hadoop.hbase.regionserver.HRegion: Failed initialize of region= cst_cust_relation_info,30612942006100091,1611896946166.76c8f8961f500e02029cf3d731b8cdb5., starting to roll back memstore java.io.IOException: java.io.IOException: org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from file hdfs://nameservice1/hbase/archive/data/default/cst_cust_relation_info/76c8f8961f500e02029cf3d731b8cdb5/cri/b9f57338b8ff42f891727ca1ef9ca378 Caused by: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1701342213-xxx.xx.xxx.193-1622692928774:blk_1074490423_749649 file=/hbase/archive/data/default/cst_cust_relation_info/76c8f8961f500e02029cf3d731b8cdb5/cri/b9f57338b8ff42f891727ca1ef9ca378 at org.apache.hadoop.hdfs.DFSInputStream.refetchLocations(DFSInputStream.java:880) 2022-03-22 13:53:05,777 ERROR org.apache.hadoop.hbase.regionserver.handler.OpenRegionHandler: Failed open of region=cst_cust_relation_info,30612942006100091,1611896946166.76c8f8961f500e02029cf3d731b8cdb5. java.io.IOException: The new max sequence id 1 is less than the old max sequence id 2380665 at org.apache.hadoop.hbase.wal.WALSplitter.writeRegionSequenceIdFile(WALSplitter.java:697) ……… 2022-03-22 14:26:30,302 ERROR org.apache.hadoop.hbase.regionserver.HRegion: Could not initialize all stores for the region=cst_cust_relation_info,30612942006100091,1611896946166.76c8f8961f500e02029cf3d731b8cdb5. 2022-03-22 14:26:30,302 WARN org.apache.hadoop.hbase.regionserver.HRegion: Failed initialize of region= cst_cust_relation_info,30612942006100091,1611896946166.76c8f8961f500e02029cf3d731b8cdb5., starting to roll back memstore java.io.IOException: java.io.IOException: org.apache.hadoop.hbase.io.hfile.CorruptHFileException: Problem reading HFile Trailer from file hdfs://nameservice1/hbase/archive/data/default/cst_cust_relation_info/76c8f8961f500e02029cf3d731b8cdb5/cri/b9f57338b8ff42f891727ca1ef9ca378 at org.apache.hadoop.hbase.regionserver.HRegion.initializeStores(HRegion.java:1095) 2022-03-22 14:26:30,308 ERROR org.apache.hadoop.hbase.regionserver.handler.OpenRegionHandler: Failed open of region=cst_cust_relation_info,30612942006100091,1611896946166.76c8f8961f500e02029cf3d731b8cdb5. java.io.IOException: The new max sequence id 1 is less than the old max sequence id 2380665 2022-03-22 14:20:43,278 INFO org.apache.hadoop.hbase.regionserver.HRegionServer: Failed report transition server { host_name: "hbase01.c6.com" port: 16020 start_code: 1647536118456 } transition { transition_code: FAILED_OPEN region_info { region_id: 1611896946166 table_name { namespace: "default" qualifier: "cst_cust_relation_info" } start_key: "30612942006100091" end_key: "309204000051869584160052106171C" offline: false split: false replica_id: 0 } }; retry (#0) after 1006ms delay (Master is coming online...).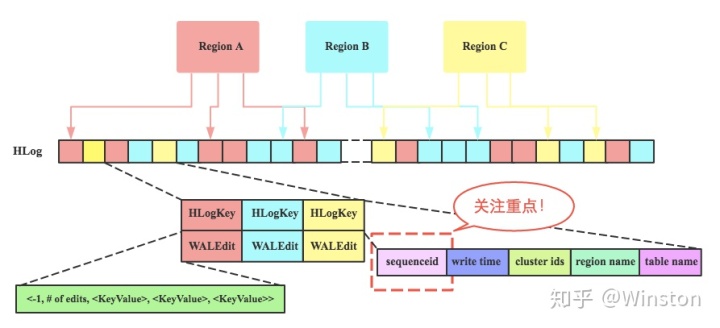
而以上报错“The new max sequence id 1 is less than the old max sequence id 2380665”,newMaxSeqId = 1L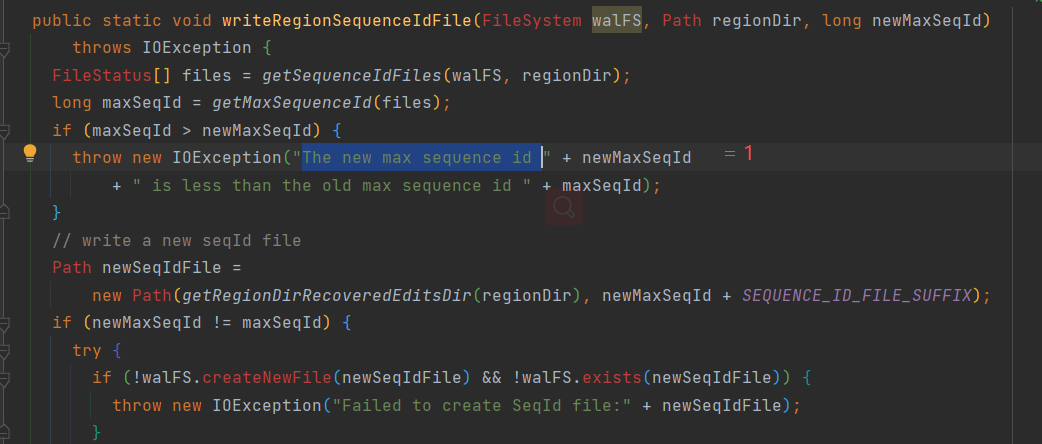
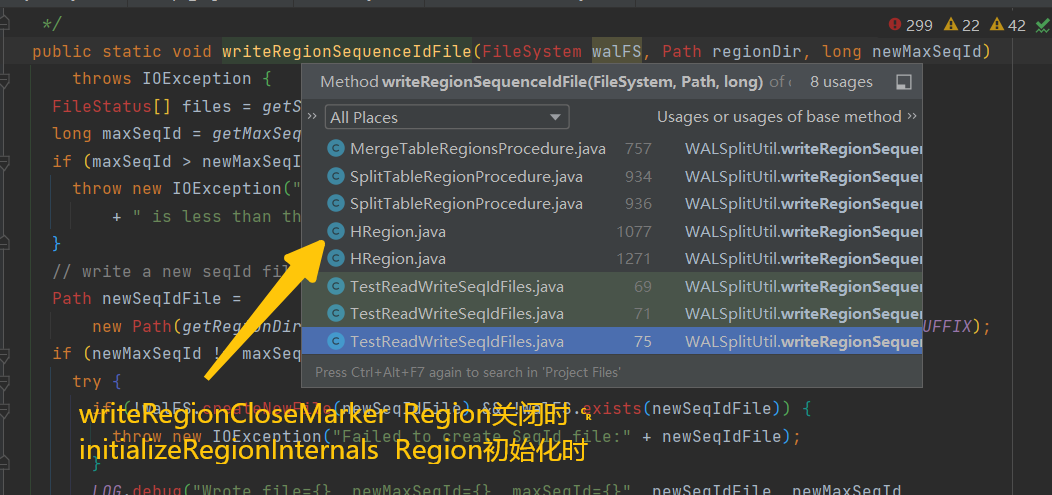
根据日志 报错主要发生在OpenRegion的过程,证明initializeRegionInternals方法运行异常,nextSeqId = -1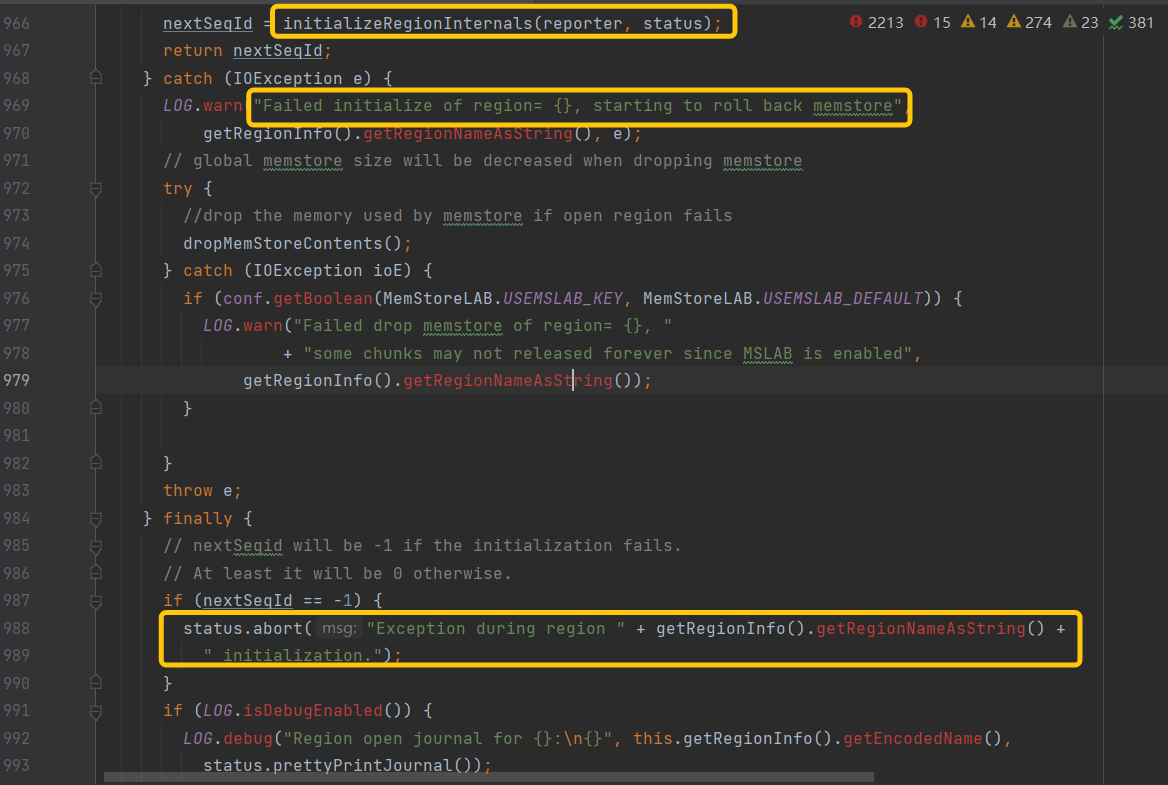
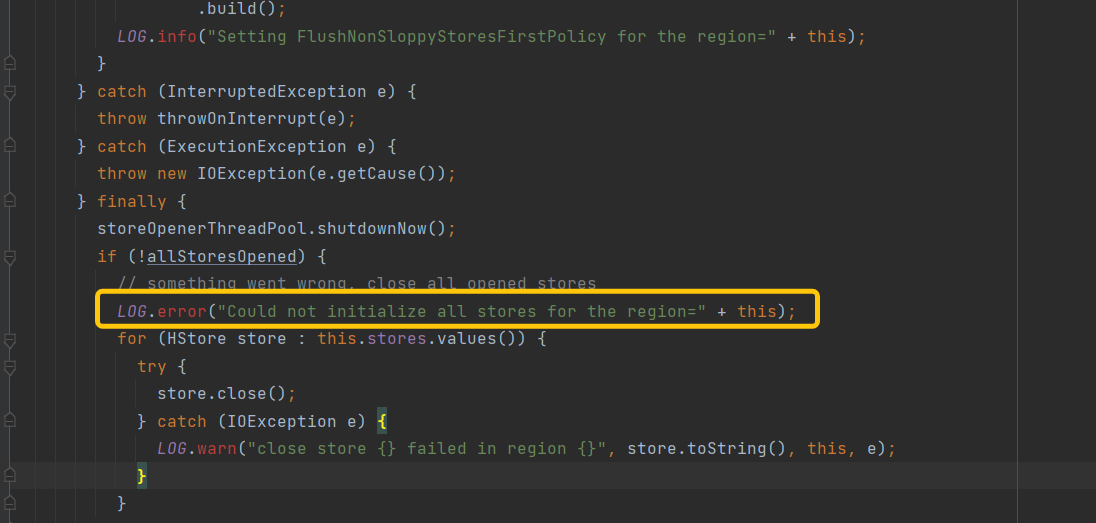
继续追溯ERROR: Could not initialize all stores for the region=xxx,xxx,xxx.76c8f8961f500e02029cf3d731b8cdb5.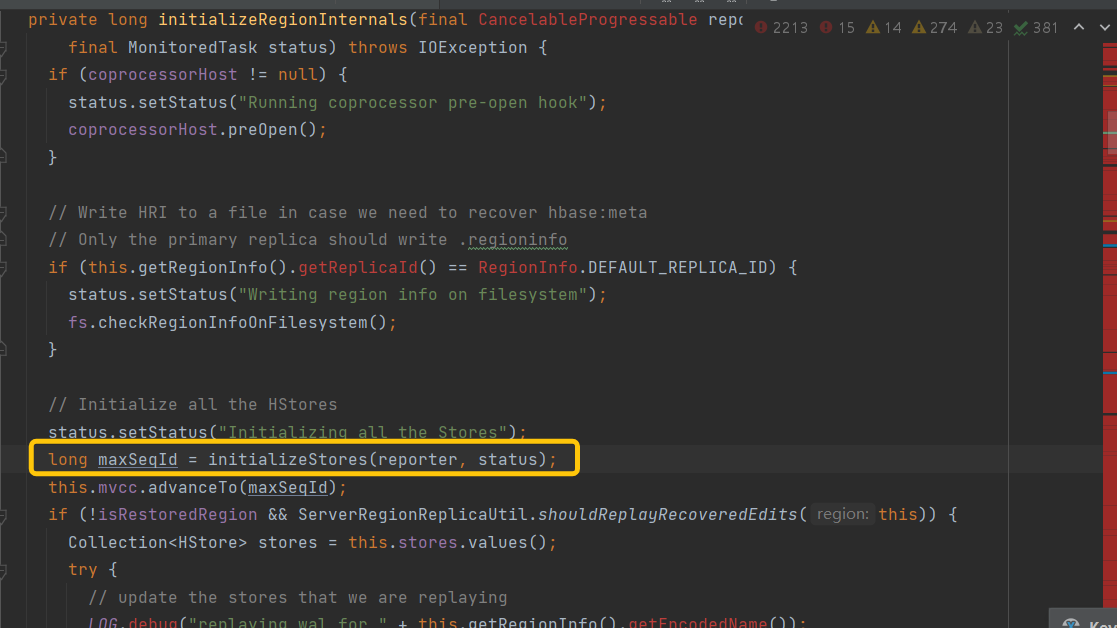
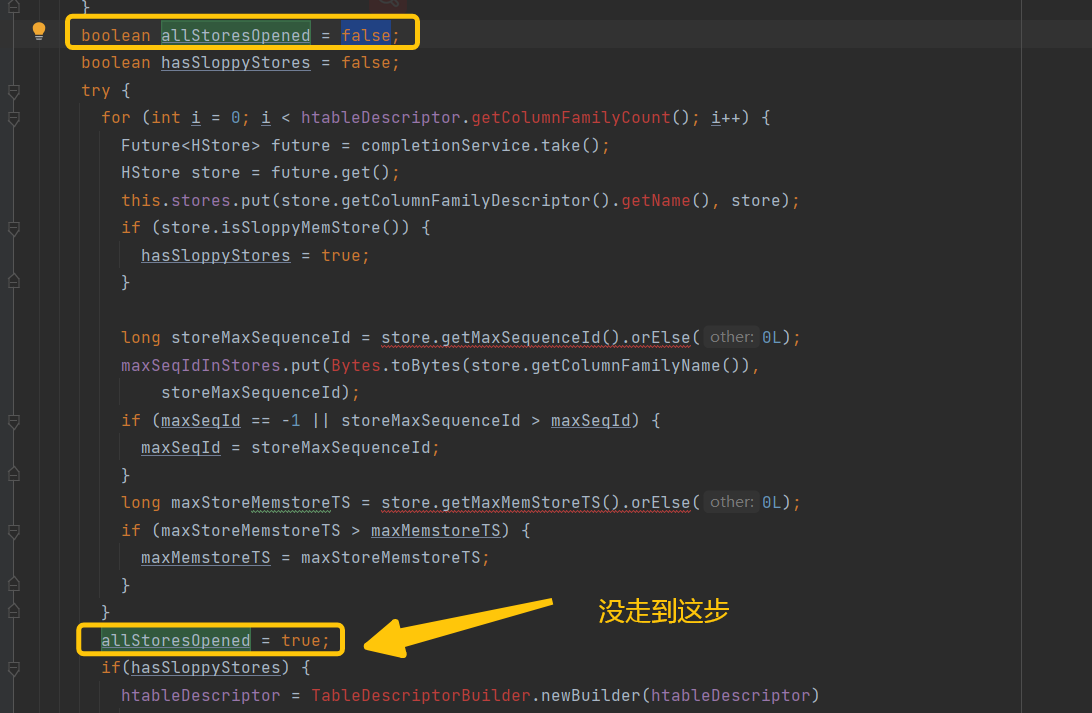
继续追溯getMaxSequenceId方法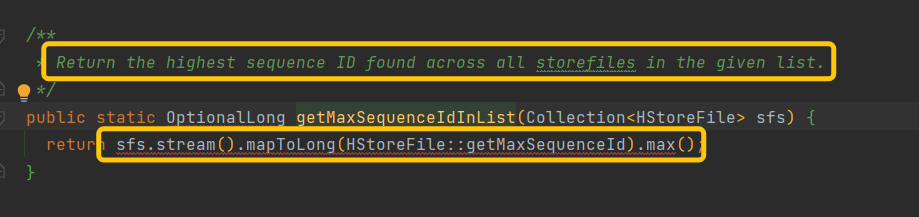
继续追溯Collectionsfs 看看到底获取了哪些HStoreFile,为何会去/hbase/archive读取文件(正常情况下/hbase/archive只存放过期Hfile和Snapshot数据),追溯到HStore.getStorefiles()方法 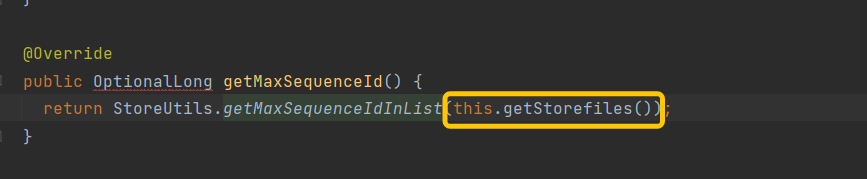
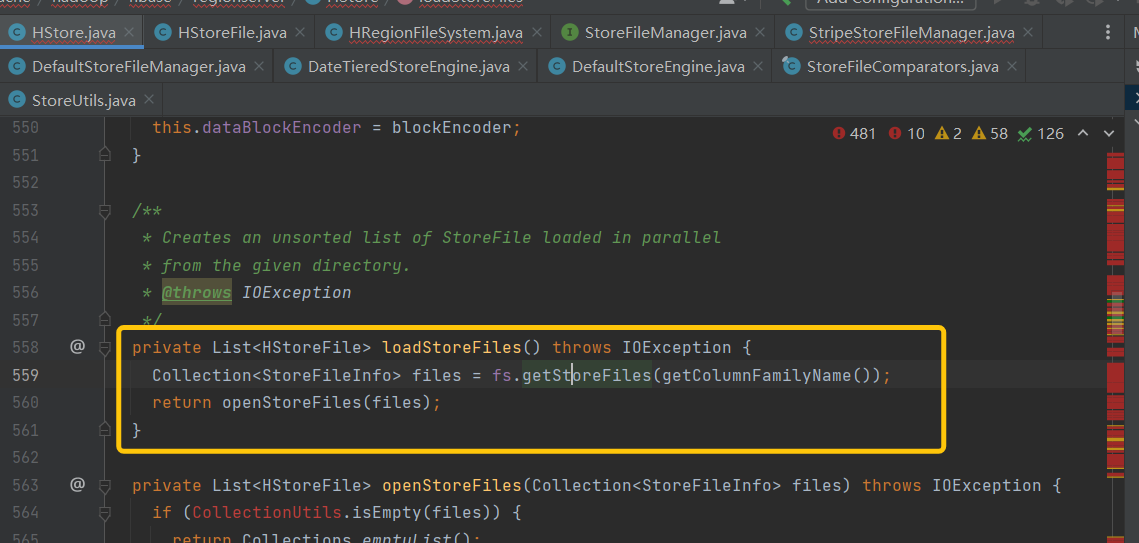

通过源码确认了实际上读取的TableDir并非archive而是data目录。
分析:没有读/hbase/archive目录,Open Region仍然失败是因为HBase的Snapshot机制。Snapshot机制并不会物理拷贝数据,而是原始数据的一份指针(链接),我们的新集群是通过创建快照+ExportSnapshot+restore_snapshot三个步骤将全量历史数据迁移至云展集群的,而restore_snapshot前,表的真实数据就存在/hbase/archive中,restore_snapshot操作几乎瞬间完成,不会真实移动数据,而是创建一份元数据链接(link),HBase在Compcat时也会将数据复制到archive目录下再进行Compact,包括Open Region时读取/hbase/data实际读取的是LinkFile(这也能解释为何新集群/hbase/data普遍比旧集群小,但表数据量一致),所以如果archive中原始文件的Block因机器宕机而丢失,则读取/hbase/data也会失败,Open Region就会失败。
HBase的HDFS默认三副本,但archive目录只有单个副本,原因是在集群迁移时为了降低集群IO,设置了单副本迁移
hbase org.hadoop.hbase.dataExport.ExportSnapshot -D dfs.replication=1 -snapshot snap_name -copy-from hdfs://nameservice1/hbase -copy-to hdfs://xxx.xx.xxx.194/hbase -mappers 10 -bandwidth 100
所以archive目录只有单副本。
总结:Region State无法由ClOSED及时成功转换为OPEN是导致HBase无法及时恢复读写的主要原因。造成Region Open失败的主要原因是archive目录中文件Block丢失、单副本。HBase是通过分散Region的方式分散请求,达到在廉价PC上达到几十至百毫秒内返回数据的效率,故Region有问题会直接影响整体的请求效率,有问题的Region越少,对请求的影响越小。应当尽量控制每台RS上Region的个数,若每台RS上的Region数量较多,宕机导致Region迁移(Region迁移过程中也会导致Region下线,Region下线不可服务)需要花费的时间越长,影响也越大。
补救措施:在集群IO较为空闲时修改/hbase/archive为三副本(以下操作为异步操作,操作后监控显示集群有丢失的Block,丢失Block数逐渐减少归零)
设置archive三副本后,进行宕机演练hadoop fs -setrep -R 3 /hbase/archive
宕机后,Region迅速迁移,上线正常。Open Region时可以拿到正确的SequenceId,未出现打开Region失败的问题,读写请求也随着Region恢复而恢复正常
机器启动 其他节点关闭Region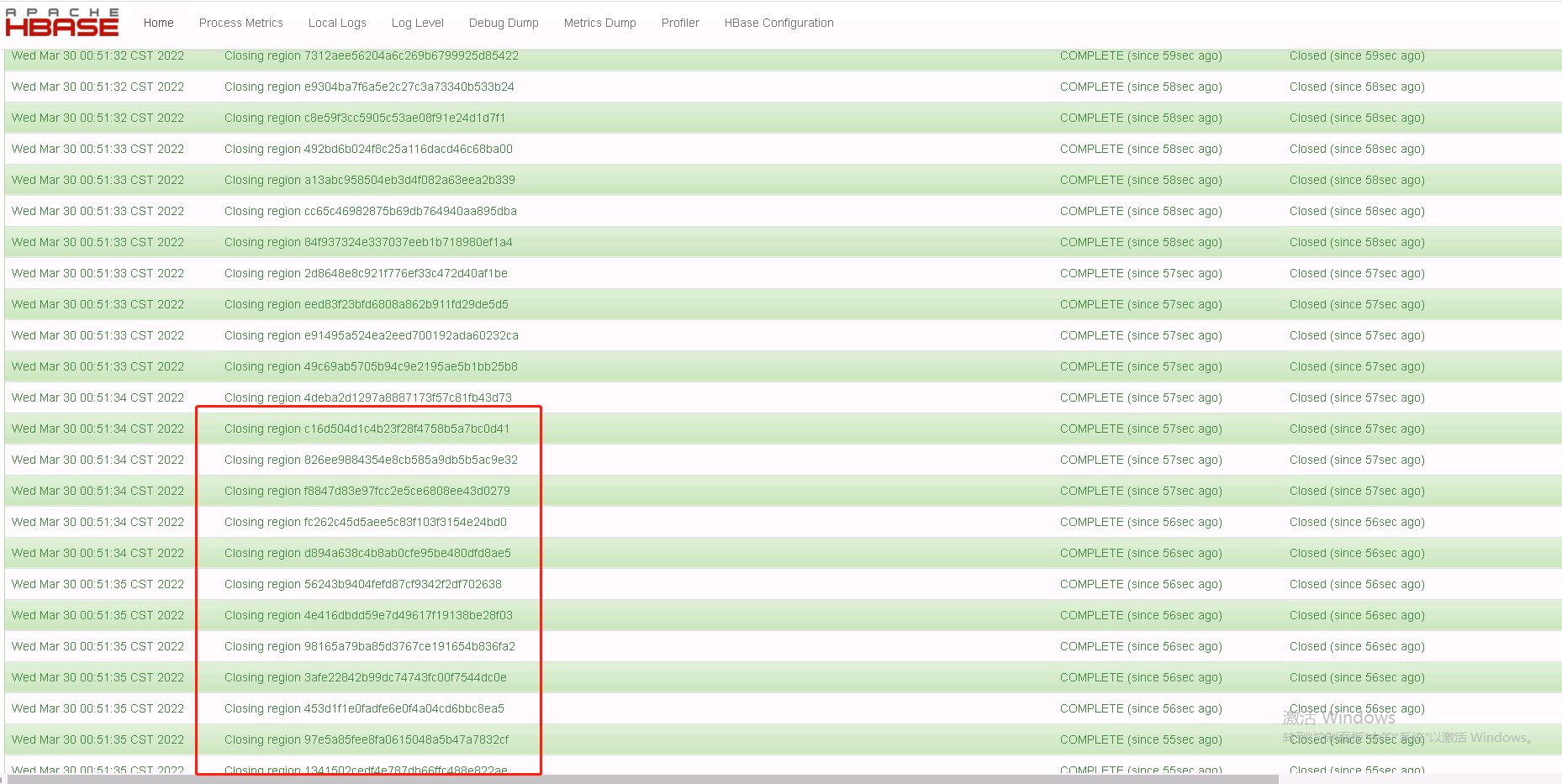
RS平均Region数下降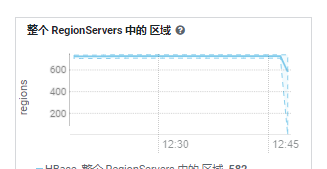
宕机恢复的节点,Region初始化正常
过一会儿在宕机恢复的节点Region Open成功,Region均匀分配过来
- 集群新增RS致另一RS异常退出
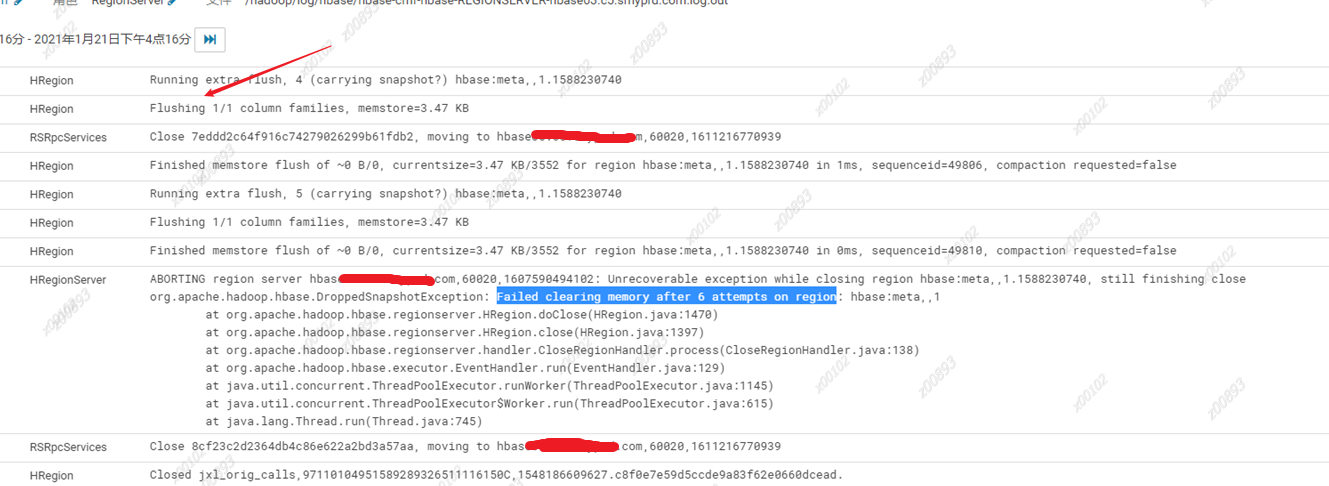
上线的RegionServer会触发Region移动,报错前有Flush操作,因为Region移动前会先Flush Region
异常相关源码: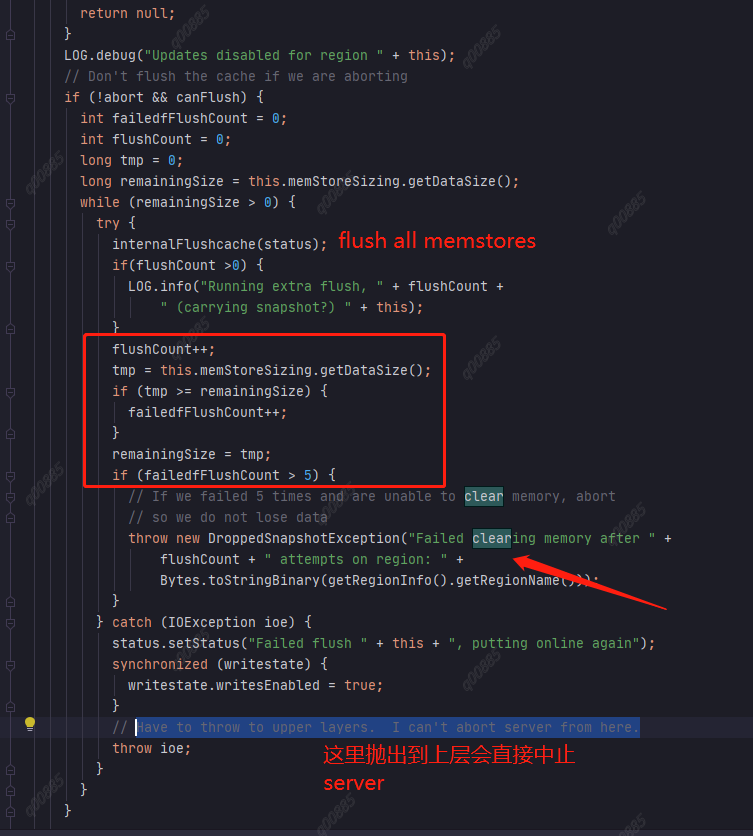
Flush Memstore到HFile这个过程未发生异常,但Flush一个Memstore后跟踪Memstore总大小未发生变化,即内存清理失败 超过5次就中止这个RS
分析:版本BUG
Kafka相关
ConsumerRebalanceFailedException异常解决
报错:kafka.common.ConsumerRebalanceFailedException: group_xxx-1446432618163-2746a209 can’t rebalance after 5 retries
分析:官网给出了异常的相关说明和解决方案
consumer rebalancing fails (you will see ConsumerRebalanceFailedException): This is due to conflicts when two consumers are trying to own the same topic partition. The log will show you what caused the conflict (search for “conflict in “).
If your consumer subscribes to many topics and your ZK server is busy, this could be caused by consumers not having enough time to see a consistent view of all consumers in the same group. If this is the case, try Increasing rebalance.max.retries and rebalance.backoff.ms.
Another reason could be that one of the consumers is hard killed. Other consumers during rebalancing won’t realize that consumer is gone after zookeeper.session.timeout.ms time. In the case, make sure that rebalance.max.retries * rebalance.backoff.ms > zookeeper.session.timeout.ms.
简单来说就是同一个topic的同一个分区被多个消费者消费,发生冲突
解决:
①增加相关topic的partition数
②提高kafka的consumer如下两项配置
rebalance.backoff.ms=2000
rebalance.max.retries=10MirrorMaker无故挂掉
# MirrorMaker挂掉且无法重启,通过日志无法明确原因 上午10点27:04.393分 ERROR MirrorMaker$MirrorMakerThread [mirrormaker-thread-0] Mirror maker thread failure due to java.lang.IllegalStateException: Unexpected error code 2 while fetching data at org.apache.kafka.clients.consumer.internals.Fetcher.parseCompletedFetch(Fetcher.java:998) at org.apache.kafka.clients.consumer.internals.Fetcher.fetchedRecords(Fetcher.java:491) at org.apache.kafka.clients.consumer.KafkaConsumer.pollForFetches(KafkaConsumer.java:1238) at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1200) at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1176) at kafka.tools.MirrorMaker$ConsumerWrapper.receive(MirrorMaker.scala:332) at kafka.tools.MirrorMaker$MirrorMakerThread.run(MirrorMaker.scala:221) ... 上午10点27:04.697分 ERROR MirrorMaker$MirrorMakerThread [mirrormaker-thread-1] Mirror maker thread exited abnormally, stopping the whole mirror maker. 上午10点27:04.697分 ERROR MirrorMaker$MirrorMakerThread [mirrormaker-thread-0] Mirror maker thread exited abnormally, stopping the whole mirror maker. # 发现source端Kafka Broker错误日志 [ReplicaManager broker=30] Error processing fetch with max size 10485760 from replica [31] on partition event-topic-2: (fetchOffset=27000304654, logStartOffset=26879257739, maxBytes=11534336, CurrentLeaderEpoch=Optional.empty) org.apache.kafka.common.errors.CorruptRecordException: Found record size 0 smaller than minimum record overhead (14) in file /xxx/xxx/0000000000xxxxx.log怀疑副本或ISR损坏,查看topic状态
kafka-topics –topic event_topic –describe –bootstrap-server s1:9092,s2:9092,s3:9092
原因:ISR缺失,ISR无法自动恢复和修复,系统磁盘存在坏道,需要更换磁盘解决;虽然Leader副本是可用的,但MirrorMaker可能卡在坏道处的Offset,尝试跳过Offset消费。如果允许数据丢失一段时间,可以使用新的消费组,从最新的Offset开始消费。
解决:换新的MirrorMaker消费组,消费正常,启动正常。后续补充丢失数据。消费Kafka时报错
org.apache.kafka.clients.consumer.OffsetOutOfRangeException: Offsets out of range with no configured reset policy for partitions: {topic_name-7=5741542729}
原因:当前消费者消费的Offset大于或小于当前Kafka集群的Offset时会报此错误。
可能情况:①消息一直积压,当前消费的offset已经小于Kafka某一个或多个分区中最老的offset,这部分数据已被Kafka删除,故无法被消费,报此错误 ②消费不均衡,部分分区积压lag较多,这些分区消费的offset对应数据已过期,被kafka删除,无法消费。
解决:提高消费速率,解决分区消费不均衡的问题,将offset重置到一定值以保证程序启动(已经丢失的offset无法恢复),根据需求调整Topic的消息保留时间(retention.ms=86400000)。
Flink相关
Checkpoint expired before completing.
org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint expired before completing.
原因: 可能设置Checkpoint时间间隔过短或代码问题.
解决: 设置更长的checkpoint interval;检查代码中是否有影响checkpoint成功执行的逻辑.Exceeded checkpoint tolerable failure threshold.
原因: 检查点任务失败次数超阈值;在达到检查点失败次数阈值(execution.checkpointing.tolerable-failed-checkpoints)前,Flink会统计检查点失败的次数,如果中间有一次检查点成功,则之前统计的失败数归零,若达到最大阈值则触发Job重启.
解决: 如果偶尔失败一次,可以容忍,则调高检查点失败数阈值execution.checkpointing.tolerable-failed-checkpointsFlink Checkpoint目录无chk-xxx目录,无法从该CP恢复
原因:如果该Flink任务不涉及状态的保存,则默认情况下,execution.checkpointing.externalized-checkpoint-retention=NO_EXTERNALIZED_CHECKPOINTS,参考Retained Checkpoints,Flink将会在程序退出时清理所有CP,故chk-xxx目录不存在。如果该Flink任务的算子是有状态的,则CheckPoint目录chk-xxx不会被删除。
解决:若需要强行保留无状态任务的CP目录,可以通过设置-Dexecution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION来使得程序不清理chk-xxx目录,以便能从该CP恢复任务。
其他
Zookeeper日志和快照过大
解决1:cd $ZOOKEEPER_HOME;bin/zkCleanup.sh {dataDir} 5;bin/zkCleanup.sh {snapshotDir} 5 并设置成定时调度
解决2:从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置autopurge.snapRetainCount和autopurge.purgeInterval这两个参数能够实现定时清理了。这两个参数都是在zoo.cfg中配置的:
autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个。
原理:Zookeeper不会删除旧的快照和日志文件,zkCleanup.sh可以帮助合理清理当前节点的旧的日志和快照文件解决磁盘空间。其中dataDir是特定服务集合的znode存储的永久副本,对znode的所有更改会附加到log日志中,snapshotDir是永久快照。zkCleanup.sh将保留最后一个快照和相关的log日志,清除其他的快照和日志。注意最后一个参数值要大于等于3,日志损坏的情况下保证有3个以上备份。
参考:zookeeperAdmin.html#sc_maintenanceZookeeper服务报错java.io.IOException: Unreasonable length 无法启动
2022-07-25 15:38:56,652 [myid:3] - INFO [main:QuorumPeer@2479] - QuorumPeer communication is not secured! (SASL auth disabled) 2022-07-25 15:38:56,652 [myid:3] - INFO [main:QuorumPeer@2504] - quorum.cnxn.threads.size set to 20 2022-07-25 15:38:56,653 [myid:3] - INFO [main:FileSnap@85] - Reading snapshot /mnt/disk1/zookeeper/version-2/snapshot.2000c6082 2022-07-25 15:38:56,900 [myid:3] - INFO [main:DataTree@1730] - The digest in the snapshot has digest version of 2, , with zxid as 0x2000c6082, and digest value as 117449458451566 2022-07-25 15:38:57,044 [myid:3] - ERROR [main:QuorumPeer@1148] - Unable to load database on disk java.io.IOException: Unreasonable length = 2573749 at org.apache.jute.BinaryInputArchive.checkLength(BinaryInputArchive.java:166) at org.apache.jute.BinaryInputArchive.readBuffer(BinaryInputArchive.java:127) at org.apache.zookeeper.server.persistence.Util.readTxnBytes(Util.java:159) at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:768) at org.apache.zookeeper.server.persistence.FileTxnSnapLog.fastForwardFromEdits(FileTxnSnapLog.java:352) at org.apache.zookeeper.server.persistence.FileTxnSnapLog.lambda$restore$0(FileTxnSnapLog.java:258) at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:303) at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:285) at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:1094) at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:1079) at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:227) at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:136) at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:90) 2022-07-25 15:38:57,046 [myid:3] - ERROR [main:QuorumPeerMain@113] - Unexpected exception, exiting abnormally java.lang.RuntimeException: Unable to run quorum server at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:1149) at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:1079) at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:227) at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:136) at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:90) Caused by: java.io.IOException: Unreasonable length = 2573749 at org.apache.jute.BinaryInputArchive.checkLength(BinaryInputArchive.java:166) at org.apache.jute.BinaryInputArchive.readBuffer(BinaryInputArchive.java:127) at org.apache.zookeeper.server.persistence.Util.readTxnBytes(Util.java:159) at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:768) at org.apache.zookeeper.server.persistence.FileTxnSnapLog.fastForwardFromEdits(FileTxnSnapLog.java:352) at org.apache.zookeeper.server.persistence.FileTxnSnapLog.lambda$restore$0(FileTxnSnapLog.java:258) at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:303) at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:285) at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:1094)原因:单个节点数据过大会导致性能问题,所以zookeeper服务端默认读取数据节点大小为1.01M,由参数程序参数jute.maxbuffer控制。当zookeeper客户端读取的节点大小超过该值时就会抛出该异常信息。
解决:在zkServer.sh启动脚本中添加SERVER_JVMFLAGS=”-Djute.maxbuffer=4194304”内容,重启zk,让zk启动时接收到新的jute.maxbuffer参数,允许数据节点大于1M,使得ZkServer可以启动。PrestoServer启动报node.environment: is malformed
```error
022-08-04T11:39:33.380+0800 ERROR main com.facebook.presto.server.PrestoServer Unable to create injector, see the following errors:
Error: Invalid configuration property node.environment: is malformed (for class com.facebook.airlift.node.NodeConfig.environment)
1 error
com.google.inject.CreationException: Unable to create injector, see the following errors:Error: Invalid configuration property node.environment: is malformed (for class com.facebook.airlift.node.NodeConfig.environment)
1 errorat com.google.inject.internal.Errors.throwCreationExceptionIfErrorsExist(Errors.java:543) at com.google.inject.internal.InternalInjectorCreator.initializeStatically(InternalInjectorCreator.java:159) at com.google.inject.internal.InternalInjectorCreator.build(InternalInjectorCreator.java:106) at com.google.inject.Guice.createInjector(Guice.java:87) at com.facebook.airlift.bootstrap.Bootstrap.initialize(Bootstrap.java:251) at com.facebook.presto.server.PrestoServer.run(PrestoServer.java:143) at com.facebook.presto.server.PrestoServer.main(PrestoServer.java:85)原因: $PRESTO_HOME/etc/node.properties中node.environment不符合[a-z0-9][_a-z0-9]*命名规范 解决方法:重新修改所有该集群节点命名规范即可,如修改为presto_cdhTrinoServer无故挂掉,日志中无ERROR
检查/var/log/message发现如下日志Dec 7 16:56:49 emr-worker-10014 kernel: Out of memory: Kill process 7308 (trino-server) score 359 or sacrifice child Dec 7 16:56:49 emr-worker-10014 kernel: Killed process 7308 (trino-server) total-vm:68996464kB, anon-rss:46582532kB, file-rss:0kB, shmem-rss:0kB Dec 7 16:56:51 emr-worker-10014 kernel: oom_reaper: reaped process 7308 (trino-server), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB原因: 当系统资源不足时,系统OOM killer机制(监控那些占用内存过大,尤其是瞬间占用内存很快的进程,然后防止内存耗尽而自动把该进程杀掉)为保证系统稳定运行,将TrinoServer进程Kill掉了.日志会记录在/var/log/message.
解决: 自动拉起Kerberos相关-客户端请求服务端rest接口报错
请求的url地址是http://172.11.11.11:1111/aa 请求的是ip地址
且提供请求用的principal和keytab使用kinit认证是正常的.Service ticket not found in the subject Caused by: KrbException: Identifier doesn't match expected value (906) Negotiate support not initiated, will fallback to other scheme if allowed. Reason GSSException: No valid credentials provided (Mechanism level: No valid credentials provided (Mechanism level: Server not found in Kerberos database (7) - LOOKING_UP_SERVER)) error code is 7 error Message is Server not found in Kerberos database KrbException: Server not found in Kerberos database (7) - LOOKING_UP_SERVER原因: 为了追求极致安全性,Keberos要求访问的服务能通过dns反向解析,验证principal是否正确,若dns域名解析有问题,就会报此错误。故需要ip可以反向解析成正确域名(正确解析的域名是指hive/_HOST@REALM.COM中的_HOST通配符部分,域名可以从keytab中寻找)
解决: 改rest请求url的地址为域名;或者修正ip的dns解析,使ip可以正确反向解析出域名后即可认证成功.



