







前言
Pandas一直是非常受欢迎的数据分析利器,它基于Numpy,专为解决数据分析任务。因其基于Python,只能单节点单核心运行,所以在大数据分析场景下,瓶颈很明显。PySpark是基于Spark JavaClient的上层接口,可以结合Python语言以及Spark分布式运行的特点,来解决Pandas在大数据下的瓶颈。本篇文章主要对比Pandas API与PySparkAPI,总结一些Pandas应用场景下使用PySpark提高效率的方案。
本篇主要是对比Pandas和PySpark的API使用,但不能对它们众多API做一一对比介绍,所以对于PySpark的更多API使用请参考:**pyspark.sql官方使用文档**
对比
| 特点 | Pandas | PySpark |
|---|---|---|
| 运行方式 | 单机单核 | 分布式 |
| 并行机制 | 不支持 | 支持 |
| 数据位置 | 单机内存 | 多节点内存和磁盘 |
| 大数据支持 | 差 | 优 |
| 数据处理方式 | 无懒加载 | 懒加载+优化无用操作 |
| DataFrame | 可变 | 不可变 |
基本原则
- 需要对大量数据进行分析的场景下,在大数据处理的源头必须使用PySpark
- 数据经过一系列操作、聚合后数据量减少,且迫不得已用Pandas的情况下再使用Pandas(用Pandas处理的数据尽量更少)
- 如果可以,尽量全程使用PySpark进行分析操作
- 需要对计算复杂且耗时的Sparkdataframe进行cache避免重算提高效率
- 尽可能将一段处理逻辑写到一段SQL中,而非得到多个Dataframe然后进行join
数据创建
文中所有Spark Dataframe对象简称df,Pandas的Dataframe对象简称pd_df。
Pandas
pd_df = pd.read_csv('/datas/root/csv_data/csv_file.csv') # 1.读本地csv数据源 pd_df = spark.sql("select col1,col2 from table").to_pandas # 2.读Hive数据源 pd_df = spark.sql("select * from table").to_pandas # 3.读Hive整个表 # 4.读MySQL表数据 pd_df = pd.read_sql('select * from table', con=pymysql.connect(host="localhost",user=username,passwd=password,db=database_name,charset="utf8")) # 5.从list,set,dict创建dataftame pd_df = pd.DataFrame({"id":[1,2,3,4,5],"name":['qjj','zxw','zzz','abc',np.nan]}) # 6.读json pd_df = pd.read_json('/datas/root/csv_data/json_file') # zeros创建指定shape的带0的ndarray pd_df = np.zeros((5,3), dtype='int64') #5 行 3 列PySpark
df = spark.read.option('inferSchema',"true").option("header", "true").csv('/data/data_test/csv_file.csv') # 1.读HDFS上csv数据源 df = spark.read.csv("file:///a.csv") # 读本地csv 路径/a.csv df = spark.sql("select col1,col2 from table") # 2.读Hive数据源 df = spark.table('table') # 3.读Hive整个表 # 4.读MySQL表数据 conf = { "driver": "com.mysql.jdbc.Driver", "url": "jdbc:mysql://cdh101:3306/", "dbtable": 'test.a', "user": 'root', "password": '123456', } df = spark.read.format("jdbc").options(**conf).load() # 5.从list,set,dict创建dataftame df = spark.createDataFrame(pd.DataFrame({"id":[1,2,3,4,5],"name":['qjj','zxw','zzz','abc',None]})) 或 df = spark.createDataFrame([(1,'qjj'),(2,'zxw'),(3,'zzz'),(4,'abc')], ['id', 'name']) # 6.读json文件 df = spark.read.json('/datas/root/csv_data/json_file') # 7.从Parquet创建数据 df = spark.read.parquet("...") df = spark.read.format('parquet').load('parquet_file'),opt...) # 8.从ORC创建数据 df = spark.read.orc('...') # 9.从text创建数据 df = spark.read.text('...') # 10.创建指定shape的带0的dataframe df = spark.createDataFrame([[0 for i in range(3)] for i in range(5)]) #5 行 3 列 # 创建数据并指定字段名(Schema) from pyspark.sql.types import * schema = StructType().add('col1', StringType(), True).add('col2', IntegerType()) # True是否可以为空 df = spark.createDataFrame([('aaa', 1),('bbb', 2)], schema=schema)
数据结构
Pandas
index索引:自动创建
行结构:Series结构,属于Pandas DataFrame
列结构:Column结构,属于Pandas DataFramepd_df['col'] = 0 # 列添加 pd_df['col'] = 1 # 列修改 pd_df.rename(columns={'col':'new_col','xx':'xxx'}) # 重命名列名 pd_df.columns=['col1','col2','col3'] # 重命名列名 pd_df.dtypes # 查看字段和类型 pd_df.drop(columns=['col', 'name']) # 删除字段colPySpark
index索引:无
行结构:Row对象,属于Spark DataFrame
列结构:Column对象,属于Spark DataFramefrom pyspark.sql.functions import lit df = df.withColumn("col", lit(0)) # 列添加 df = df.withColumn("col", lit(1)) # 列修改 df = df.withColumnRenamed('col', 'new_col').withColumnRenamed('col1', 'new_col1') # 重命名列名 df.dtypes # 查看字段和类型 df.printSchema() # 打印字段和类型-树形 df.drop('col', 'name') # 删除字段col
数据显示
Pandas
pd.set_option('max_rows',1024) # 最多显示1024行不隐藏 pd.set_option('max_columns',1024) # 最多显示1024列不隐藏 pd_df或print(pd_df)PySpark
df.show() # 打印前20行且每个字段打印不超过20字符 df.show(30) # 打印前30行且每个字段打印不超过20字符 df.show(100,False) # 打印前100行且每个字段打印字符数不限(不隐藏)
数据排序
Pandas
pd_df.sort_index(by='score', ascending=False) # 按轴(字段score)进行倒序排序 pd_df.sort_index(by='score', ascending=False).reset_index() # 按轴(字段score)进行倒序排序,排序后index会乱序,重设index为顺序 pd_df.sort_values(by='score') # 在列中按值进行排序PySpark
df.sort('score', ascending=False) # 按列(score字段)倒序排序 df.orderBy('score') # 按列(score字段)顺序排序
交集并集差集
Pandas
pd.merge(pd_df1, pd_df2, on=['col1', 'col2', 'col3']) # 交集 pd.merge(pd_df1,pd_df2,on=['col1', 'col2', 'col3'], how='outer') # 并集 pd_df1=pd_df1.append(pd_df2);pd_df1=pd_df1.drop_duplicates(subset=['col1','col2','col3'],keep=False);pd_df1 # 差集PySpark
df = df1.intersect(df2) # 交集 df = df1.union(df2) # 并集 df = df1.subtract(df2) # 差集
数据选择或切片
Pandas
# 1.取一列 pd_df.col_name # 2.取多列 pd_df[['id','score']] # 3.取第一行 pd_df.ix[0] # 4.取前两行 pd_df.head(2) # 5.按条件取数据 pd_df.loc[pd_df.name=='qjj'] # 取pd_df的name字段值为qjj记录 pd_df.loc[pd_df.name=='qjj', 'col'] # 取pd_df的name字段值为qjj的记录中name字段和col字段的值 # 6.数据随机抽样 pd_df.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None) # n行数 frac抽取比例 replace=False无放回 ...PySpark
# 1.取一列 df.select('score').show() # 2.取多列 df.select('id','score').show() df.select(df['id'],df['score']).show() # 2.取多列 每个值加20 df.select(df['id'] + 20,df['score']).show() # 3.取第一行 df.first() # 4.取前两行 df.head(2) 或 df.take(2) # 5.按条件取数据 df.filter("name='qjj'") # 取df的name字段值为qjj记录 df.filter("name='qjj'").select('name', 'col') # 取df的name字段值为qjj的记录中name字段和col字段的值 # 6.数据随机抽样 df=df.sample(withReplacement=False, fraction=0.01) # withReplacement为False抽出数据不放回,fraction为抽取比例范围0-1,seed参数为随机数种子,默认即可
数据过滤
Pandas
pd_df[pd_df['score']>=60] pd_df[pd_df['score']>=60][pd_df['id']>=5] pd_df.query('score >= 60')PySpark
df.filter('score>=60') 或 df.where('score>=60') df.filter('score>=60 and id>=5') 或 df.where('score>=60 and id>=5')
数据去重
Pandas
pd_df.drop_duplicates('col')PySpark
df.drop_duplicates() # data中一行元素全部相同时才去除 df.drop_duplicates(['a','b']) # data根据’a','b'组合列删除重复项,默认保留第一个出现的值组合(first)。
取唯一值
Pandas
pd_df['col'].unique()PySpark
df.select('col').distinct().count() 或df.drop_duplicates(['col']).count()
分组聚合
Pandas
pd_df.groupby('col').mean()PySpark
df.groupBy('col').mean().show() df.groupBy('col').avg('score').show() from pyspark.sql import functions df.groupBy('col').agg(functions.avg('score'), functions.min('score'), functions.max('score')).show() # 使用SQL分组聚合 spark.sql("select name,first(col) as col,sum(score) from table group by name").show()
数据计算
- Pandas
pd_df['col'].apply(lambda x: round(math.log(7,2),2)) # 计算2为底7的log,精确小数点后2位 pd_df['col'].apply(lambda x: sum(x)) # 求和 - PySpark
spark.sql("select round(log(2,7),2) as r").show() # 计算2为底7的log,精确小数点后2位 spark.sql("select sum(col) from df").show() # 求和
数据统计
Pandas
pd_df.count() # 输出每一列的非空行数 pd_df.describe() # 描述某些列的count, mean, std, min, 25%, 50%, 75%, max pd_df['col'].value_counts() # 统计某列的数据量PySpark
df.count() # 输出总行数 df.describe().show() # 描述某些列的count, mean, stddev, min, max df.select('col').filter('col is null').count() # 统计某列的数据量
数据合并
TODO:待完善测试
Pandas
pd.concat([pd_df,pd_df1], axis=0) # 数据横向合并axis=0 纵向合并axis=1 Pandas下有merge方法,支持多列合并 同名列自动添加后缀,对应键仅保留一份副本 pd_df.join() 支持多列合并 pd_df.append() 支持多行合并 # 根据一定计算规则计算得到新增列PySpark
df.withColumn(新列名,df[列名]**2) # 数据简单操作后横向合并 df.union(df1) # 数据纵向合并-自动去除重复数据 df.unionAll(df1) # 数据纵向合并-不去除重复数据 # 可以使用sql实现concat、merge功能 df.join(df1,df.id==df1.id) # inner join df.join(df1,df.id==df1.id, 'left') # left join df.join(df1,df.id==df1.id, 'left') # right join df.join(df1,df.id==df1.id, 'outer') # full outer join 任何一边不存在填充null # 根据UDF计算得到新增列 udf+withColumn+闭包 from pyspark.sql.functions import udf from pyspark.sql.types import IntegerType l = ['a', 'b', 'c', 'd'] for i in l: my_udf = udf(lambda x: x.count(i) if x else 0, IntegerType()) df = df.withColumn('col_' + i, my_udf('array_type_col'))
数据修改
对应pd.apply(f)方法 即给df的每一列应用函数f
Pandas
pd_df.apply(f) # 可作用于Series或整个Dataframe,并对每个元素应用函数f pd_df.apply(f, axis=1) # axis=0 表示按列,axis=1 表示按行 pd_df.replace({1:10, 2:20}) # 将dataframe中值为1的都替换成10,2替换成20 pandas支持替换为不同类型PySpark
df.foreach(f) 或者 df.rdd.foreach(f) # 将df的每一列应用函数f df.foreachPartition(f) 或者 df.rdd.foreachPartition(f) # 将df的每一分区数据应用函数f pd_df.replace({1:10, 2:20}) # 将dataframe中值为1的都替换成10,2替换成20 spark不支持替换为不同类型注意:Spark的apply方法会触发全量数据Shuffle,如果数据量过大会有shuffle异常和ExecutorOOM等错误,任务失败概率会增加,而且需要消耗更多计算资源
空值处理
Pandas
# 对缺失数据自动添加NaNs pd_df.fillna(1) # fillna函数 将NaN的地方替换为1.0 pd_df.dropna() # dropna函数 将含有NaN的行删除 pd_df['col']=np.where(pd.isnull(pd_df['col'], "unknown", pd_df['col'])) # 某个字段出现空时替换为unknown pd_df['col']=np.where(pd_df['col']=='', "unknown", pd_df['col']) # 某个字段出现空字符串时替换为unknown pd_df.isna() # 非空值变为False,有空值变为TruePySpark
不自动添加NaNs,且不抛出错误 df.na.fill(1).show() # fillna函数 将null的地方替换为1.0 df.na.drop().show() # dropna函数 将含有null值字段的行删除 df.dropna(subset=['col1', 'col2']) # 扔掉col1或col2中任一一列包含null的行 df=df.na.fill(subset='col', value='unknown') # 某个字段出现空时替换为unknown select if(col='','unknown',col) as col # 某个字段出现空字符串时替换为unknown df.fillna('True') # 有空值变为True 还可使用case when或if处理空值
SQL支持
Pandas
import pymysql con = pymysql.connect(host="localhost", user="root", password="123456", database="test", charset='utf8', use_unicode=True) sql_cmd = "SELECT * FROM a" # a是test库下的表名 pd_df = pd.read_sql(sql_cmd, con)PySpark
# sql操作 df.registerTempTable('score_table') # 将已有数据注册成临时表(关闭SparkSession这个表就会消失) df.createOrReplaceTempView('score_table') # 与registerTempTable功能相同,是较新的API df.createOrReplaceGlobalTempView('score_table') # 上面两个是创建SparkSession级别的临时表 这个是Application级别的临时表 spark.sql("desc score_table").show() spark.sql("""select count(1) as count from score_table""").show() # UDF高级功能函数注册操作 from pyspark.sql.types import StringType # 引入返回值类型 spark.udf.register("get_length", lambda x: len(x), StringType()) # 注册UDF函数 spark.sql("select get_length('name') from score_table").show() # 使用UDF函数 # 对特征进行操作 df.selectExpr("a*2+b as a","b*3 as b") # a字段值改为原始值*2加b字段值 可以有多个运算操作 df = df.selectExpr("*","b*3 as b_3") # 原始字段不变,新增b_3字段值为b字段*3
互相转换
Pandas
df = spark.createDataFrame(pandas_df) # Pandas转Spark df df = spark.createDataFrame(pandas_df[['col1', 'col2']]) # Pandas某几个字段的df转Spark dfPySpark
pandas_df = spark_df.toPandas() # Spark转Pandas df pandas_df = spark_df.select('col1', 'col2').toPandas() # Spark某几个字段的df转Pandas df注:Spark转Pandas df会将Spark df全部数据拉到Driver端单机单节点运行,性能差且网络IO占用高,尽量避免将大量数据转成Pandas DataFrame。
透视表
透视表与逆透视表: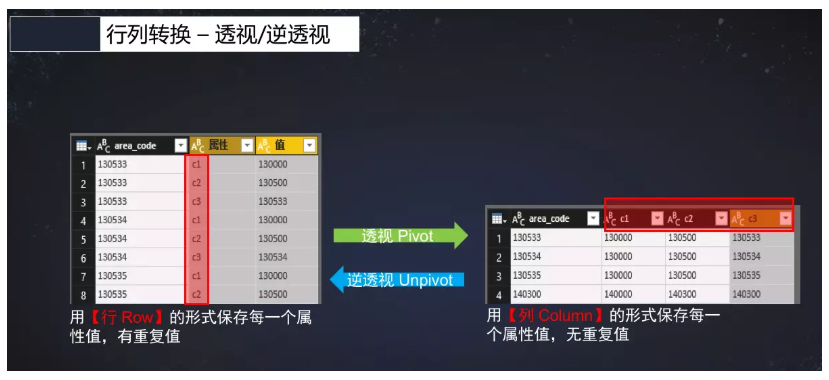
透视Pivot:
按不需要转换的字段分组(groupBy) -> pivot函数进行透视,可选第二个参数指定输出字段数据项 -> 聚合汇总数据项得到结果
逆透视unpivot:列形式且无重复值的数据转成行形式且有重复值得数据
Pandas
l = ['a', 'b', 'c', 'd', 'e'] for tag in l: pivot_table = pd.pivot_table(pd_df, index=['col1', 'col2'], values='list_type_col', aggfunc=lambda x: sum(tag==j for i in x for j in i)) # 统计数组值等于tag计数True个数 pivot_table.columns=[tag]PySpark
# 注意:pivot只能跟在groupBy之后 l = ['a', 'b', 'c', 'd', 'e'] pivot_table = df.selectExpr('*', 'explode(list_type_col)', '1 as tmp').groupBy('col1', 'col2').pivot("list_type_col", l).sum("tmp").fillna(0) # 注意:不指定pivot的第二个参数所需字段会降低效率 # 相关逻辑可以直接使用spark sql编写
diff操作
Pandas
pd_df.diff() # diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据PySpark
没有diff操作(Spark的上下行是相互独立,分布式存储的)
数据保存
pd_df.to_csv("/data/path_to_file") # 写本地csv文件- PySpark
df.write.csv("file:///data/path") # 数据写本地csv,可能写多个文件 df.coalesce(1).write.csv("file:///data/path") # 数据写本地,写1个csv文件 df.coalesce(1).mode("overwrite").option(header=True).csv('/data/hdfs_path',sep='\t') # 写一个csv文件到hdfs,带header,默认覆盖,分隔符为\t df.write.insertInto('exist_hive_table') # 追加写数据到已存在的hive表 字段与df中字段名称顺序类型要对应 df.write.insertInto('exist_hive_table', overwrite=True) # 覆盖写数据到已存在的hive表 字段与df中字段名称顺序类型要对应 df.write.jdbc(url="jdbc:mysql://xxx.xxx.xxx.xxx:3306/db_name", table="table_name", mode="overwrite", properties={"user": "root", "password": "123456"}) # 将数据overwrite到mysql 注意数据量不能太大且并行度不能太高,可能会把mysql搞垮,建议并行度不超过10==>NumExecutors*ExecutorCores <= 10 写表时观察mysql端的负载和压力:show status;和show processlist;
df.write.saveAsTable(“hive_table”, mode=”append”) # 直接写数据到hive表 无论表是否已经存在都可以 还有options,partitionBy,format等参数影响表结构
df.write.format(‘parquet’).bucketBy(100,’year’,’month’).sortBy(‘day’).mode(‘overwrite’).saveAsTable(‘sorted_bucketed_table’) # 数据排序分区存储成parquet
df.coalesce(1).write.save(path,format,mode,partitionBy,**Options) # 存储数据
df.coalesce(1).write.json(“file:///data/path”,mode=’overwrite’,) # 写数据到单个json文件
注:文件写到hdfs也不要紧,可以通过挂载NFS或者FUSE等方式将hdfs目录挂载到本地,同样方便后续处理
## 高级用法(优化)
* PySpark连续编写转换函数
```python
spark.table('ods_test.test').filter('age=22').where('dt="20200524"').groupBy('id').avg('age').registerTempTable('tmp')
for i in spark.sql("select id,'avg(age)' as avg_age from tmp").collect():
print(i[0], i[1])读取MySQL大表优化
partitionColumn:分区字段,需要是数值类的(partitionColumn must be a numeric column from the table in question.),经测试,除整型外,float、double、decimal都是可以的
lowerBound:下界,必须为整数,不能大于upperBound否则报错
upperBound:上界,必须为整数,与lowerBound一起确定分区数据量步长,lowerBound和upperBound并不会过滤数据。
numPartitions:最大分区数量,必须为整数,当为0或负整数时,实际的分区数为1;并不一定是最终的分区数量,例如“upperBound - lowerBound< numPartitions”时,实际的分区数量是“upperBound - lowerBound”;
以上四个参数必须同时制定否则报错。
在分区结果中,分区是连续的,虽然查看每条记录的分区,不是顺序的,但是将rdd保存为文件后,可以看出是顺序的。conf = { "driver": "com.mysql.jdbc.Driver", "url": "jdbc:mysql://cdh102:3306/", "dbtable": 'db_users.tb_user_records', "user": 'root', "password": '123456', "partitionColumn": "duration", # 这个字段为int类型 "lowerBound": "0", "upperBound": "10000", "numPartitions": "5" } df = spark.read.format("jdbc").options(**conf).load() df1.rdd.getNumPartitions() # 会得到5个分区该操作的目的是增加并行JDBC连接数,增加读取速度以及增加DataFrame的分区数从而增加计算的并发度。并发度即为Spark的Task数,这个数量一般根据总core数(executor_coresnum_executors)来计算:Task数≈总core数(2~3倍)
如果数据量较少,则不需要以这种方式读取,否则可能降低效率
伪代码,帮助理解原理:# 情况一: if partitionColumn || lowerBound || upperBound || numPartitions 有任意选项未指定,报错 # 情况二: if numPartitions == 1 忽略这些选项,直接读取,返回一个分区 # 情况三: if numPartitions > 1 && lowerBound > upperBound 报错 # 情况四: numPartitions = min(upperBound - lowerBound, numPartitions) if numPartitions == 1 同情况二 else 返回numPartitions个分区 delta = (upperBound - lowerBound) / numPartitions 分区1数据条件:partitionColumn <= lowerBound + delta || partitionColumn is null 分区2数据条件:partitionColumn > lowerBound + delta && partitionColumn <= lowerBound + 2 * delta ... 最后分区数据条件:partitionColumn > lowerBound + n*delta也就是说,需要合理设置numPartitions和upperBound和upperBound的值,避免某个分区数据量过大。
尽量使用范围基本确定且分区字段值分布相对均匀的Int类型字段做分区字段。多个UDF作用于同一列数据
Demo:multi_udf_one_col.py
其他
Python三方库:SparklingPandas
SparklingPandas
参考
PySpark.sql module
pandas与pyspark对比
Spark:使用partitionColumn选项读取数据库原理
PySpark-DataFrame操作指南



