







SeaTunnel开源数据同步平台
SeaTunnel简介
SeaTunnel is a very easy-to-use ultra-high-performance distributed data integration platform that supports real-time synchronization of massive data.
SeaTunnel是一个简单易用且高效的开源数据集成平台(前身是WaterDrop),支持离线和实时数据同步。支持多种Source、Output、Filter组件以及自行开发输入输出插件和过滤器插件。SeaTunnel配置简单,基于已有的Spark、Flink环境几分钟就可以部署完成。因其有各种灵活的插件支持,只需要花几分钟编写一个配置文件即可完成一个数据同步任务的开发。
SeaTunnel架构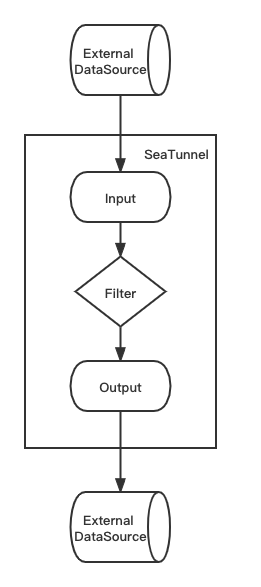
SeaTunnel特性:
- 简单易用,配置灵活,低代码
- 支持实时数据流和离线数据同步
- 高性能分布式、海量数据处理能力
- 模块化、插件化,易于扩展
- 支持通过SQL做ETL操作
SeaTunnel支持的组件:
Input plugin: Fake, File, HDFS, Kafka, S3, Hive, Kudu, MongoDB, JDBC, Alluxio, Socket, self-developed Input plugin
Filter plugin: Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, Self-developed Filter plugin
Output plugin: Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3, Stdout, self-developed Output plugin
支持的所有组件可以参考SeaTunnel通用配置
使用SeaTunnel
安装部署SeaTunnel
使用SeaTunnel将Kudu数据导入ClickHouse
下载SeaTunnel:SeaTunnel二进制包
unzip seatunnel-1.5.5.zip
cd seatunnel-1.5.5
# 修改seatunnel环境配置
vim config/seatunnel-env.sh
SPARK_HOME=/hadoop/bigdata/spark/spark-2.3.2-bin-hadoop2.6SeaTunnel将Kudu表导入ClickHouse
准备kudu表
Kudu表kudu_db.kudu_table(在KuduWebUI中表名为impala::kudu_db.kudu_table)
预先创建目标ClickHouse表
CREATE TABLE test.ch_table
(
`cust_no` String,
`tag_code` String,
`update_datetime` DateTime
)
ENGINE = MergeTree
ORDER BY cust_no;参考seatunnel-docs-configuration 配置数据抽取任务
vim config/kudu2ch.batch.conf内容如下
spark {
spark.app.name = "kudu2ch"
# executor的数量
spark.executor.instances = 2
# 每个excutor核数 (并行度,数据量大可以适当增大到ClickHouse服务器核数一半以下,尽量不要影响ClickHouse)
spark.executor.cores = 1
# 每个excutor内存
spark.executor.memory = "1g"
}
input {
kudu{
kudu_master="kudu_master1_ip:7051,kudu_master2_ip:7051,kudu_master3_ip:7051"
kudu_table="impala::kudu_db.kudu_table"
# 对应输出中需要指定source_table_name="kudu_table_source"
result_table_name="kudu_table_source"
}
}
filter {
}
output {
clickhouse {
# 指定从哪个源抽取数据
source_table_name="kudu_table_source"
host = "ch_jdbc_ip:8123"
clickhouse.socket_timeout = 50000
database = "test"
table = "ch_table"
fields = ["cust_no","tag_code","update_datetime"]
username = "default"
password = "123456"
# 每批次写入ClickHouse数据条数
bulk_size = 20000
}
}执行抽取任务:
/opt/seatunnel-1.5.5/bin/start-seatunnel.sh --master local[3] --deploy-mode client --config /opt/seatunnel-1.5.5/config/kudu2ch.batch.conf排错1:
Caused by: ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 210, host: ch_jdbc_ip, port: 8123; Connect to ch_jdbc_ip:8123 [/ch_jdbc_ip] failed: Connection refused (Connection refused)原因:CH Server端未开启远程访问权限
解决:开启CH Server支持远程访问的权限
排错2:
2021-12-22 15:23:47 ERROR TaskSetManager:70 - Task 2 in stage 0.0 failed 1 times; aborting job
Exception in thread "main" java.lang.Exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 2 in stage 0.0 failed 1 times, most recent failure: Lost task 2.0 in stage 0.0 (TID 2, localhost, executor driver): java.lang.ClassCastException: java.sql.Timestamp cannot be cast to java.lang.String
at io.github.interestinglab.waterdrop.output.batch.Clickhouse.renderBaseTypeStatement(Clickhouse.scala:351)
at io.github.interestinglab.waterdrop.output.batch.Clickhouse.io$github$interestinglab$waterdrop$output$batch$Clickhouse$$renderStatementEntry(Clickhouse.scala:373)
at io.github.interestinglab.waterdrop.output.batch.Clickhouse$$anonfun$io$github$interestinglab$waterdrop$output$batch$Clickhouse$$renderStatement$1.apply$mcVI$sp(Clickhouse.scala:403)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:160)
at io.github.interestinglab.waterdrop.output.batch.Clickhouse.io$github$interestinglab$waterdrop$output$batch$Clickhouse$$renderStatement(Clickhouse.scala:391)
at io.github.interestinglab.waterdrop.output.batch.Clickhouse$$anonfun$process$2.apply(Clickhouse.scala:187)
at io.github.interestinglab.waterdrop.output.batch.Clickhouse$$anonfun$process$2.apply(Clickhouse.scala:162)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:935)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:935)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2074)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2074)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:109)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)原因:如果Kudu中表字段格式为Timestamp,需要在写入ClickHouse前先将Timestamp类型数据转换为字符串格式否则会写入错误。
相关Git Issue: SeaTunnel-848
相关文档:ClickHouse类型对照表
解决:写入ClickHouse之前需要通过SeaTunnel中的 Filter插件 中的 SQL 或者 Convert 插件将各字段转换为对应格式,否则会产生报错
注意:若配置中有filter插件且需要filter生效,则不要在output指定source_table_name这个选项,若指定了source_table_name的值等于input中result_table_name的值,则会绕过filter(filter不生效)
修改配置
vim config/kudu2ch.batch.conf内容如下
spark {
spark.app.name = "kudu2ch"
# executor的数量
spark.executor.instances = 2
# 每个excutor核数 (并行度,数据量大可以适当增大到ClickHouse服务器核数一半以下,尽量不要影响ClickHouse)
spark.executor.cores = 1
# 每个excutor内存
spark.executor.memory = "1g"
}
input {
kudu{
kudu_master="kudu_master1_ip:7051,kudu_master2_ip:7051,kudu_master3_ip:7051"
kudu_table="impala::kudu_db.kudu_table"
# 对应输出中需要指定source_table_name="kudu_table_source"
result_table_name="kudu_table_source"
}
}
filter {
sql {
sql = "select cust_no,tag_code,date_format(update_datetime, 'yyyy-MM-dd') as update_datetime from kudu_table_source"
}
}
output {
clickhouse {
# 指定从哪个源抽取数据
# source_table_name="kudu_table_source"
host = "ch_jdbc_ip:8123"
clickhouse.socket_timeout = 50000
database = "test"
table = "ch_table"
fields = ["cust_no","tag_code","update_datetime"]
username = "default"
password = "123456"
# 每批次写入ClickHouse数据条数
bulk_size = 20000
}
}若使用Convert模块,Filter中内容
filter {
date{
source_field = "update_datetime"
target_field = "update_datetime"
source_time_format = "UNIX"
target_time_format = "yyyy-MM-dd HH:mm:ss"
}
}执行抽取任务:
/opt/seatunnel-1.5.5/bin/start-seatunnel.sh --master local[3] --deploy-mode client --config /opt/seatunnel-1.5.5/config/kudu2ch.batch.conf数据验证:
Kudu:
+———-+
| count(1) |
+———-+
| 714218 |
+———-+
Fetched 1 row(s) in 2.39s
ClickHouse:
Query id: 8d6bc13d-c49d-408a-8e07-3d2691e3ebbb
┌─count()─┐
│ 714218 │
└─────────┘
1 rows in set. Elapsed: 0.003 sec.
但DateTime类型相差8小时,因为ClickHouse的DateTime时区问题,故可以在sql中对update_datetime字段值减去8*3600秒
filter {
sql {
sql = "select cust_no, tag_code, date_format(cast(cast(update_datetime as int) - 8*3600 as timestamp), 'yyyy-MM-dd HH:mm:ss') as update_datetime from kudu_table_source"
}
}一开始想设置ClickHouse中DateTime时区为DateTime(‘Asia/Hong_Kong’),但SeaTunnel不支持这格式,只能用默认的DateTime格式
注意:SeaTunnel抽取Kudu的SparkTask数等于Kudu表的Tablet数,建议给定Spark程序并行度为Tablet数的三分之一或二分之一。
SeaTunnel将Impala表导入ClickHouse
SeaTunnel支持Input类型没有Impala但有JDBC,支持任何JDBC数据源,Impala也属于JDBC数据源。
通过SeaTunnel可以将Impala管理的Kudu表、Hive表数据导出到其他存储引擎。
准备Impala Hive表
Impala表 default.qjj_test
+——+——–+———+
| name | type | comment |
+——+——–+———+
| id | int | |
| name | string | |
+——+——–+———+
创建对应目标ClickHouse表
CREATE TABLE default.qjj_test
(
`id` int,
`name` String
)
ENGINE = MergeTree
ORDER BY id;参考SeaTunnel-docs-JDBC编写任务配置文件
配置文件/opt/seatunnel-1.5.5/config/impala2ch.batch.conf如下:
spark {
spark.app.name = "impala-jdbc-2-clickhouse-jdbc"
spark.executor.instances = 2
spark.executor.cores = 1
# 每个excutor内存
spark.executor.memory = "2g"
}
input {
jdbc {
driver = "com.cloudera.impala.jdbc41.Driver"
url = "jdbc:impala://impalad_ip:21050/default"
table = "(select * from qjj_test) as source_table"
# 或者直接写表名也可以table = "qjj_test"
result_table_name = "impala_table_source"
user = ""
password = ""
}
}
filter {
}
output {
clickhouse {
source_table_name="impala_table_source"
host = "ch_jdbc_ip:8123"
clickhouse.socket_timeout = 50000
database = "default"
table = "qjj_test"
username = "default"
password = "123456"
# 每批次写入ClickHouse数据条数
bulk_size = 20000
}
}将jdbc-jar放入seatunnel目录的plugins/my_plugins/lib目录
Impala-jdbc下载地址:Donwload ImpalaJDBC41.jar
cd seatunnel-1.5.6/
mkdir -p plugins/my_plugins/lib
cd plugins/my_plugins/lib
cp /hadoop/bigdata/common/lib/ImpalaJDBC41.jar .执行抽取任务:
/opt/seatunnel-1.5.5/bin/start-seatunnel.sh --master yarn --deploy-mode cluster --config /opt/seatunnel-1.5.5/config/impala2ch.batch.conf此时可以正常抽取数据了,但通过观察程序WebUI发现无论给了多少ExecutorCore,只有一个Task,这样低的并行度会极大影响数据抽取效率,所以需要在配置上做改进:
参考SeaTunnel-Spark-jdbc-string 得知SeaTunnel支持SparkJDBC的所有参数:spark-sql-data-sources-jdbc
配置修改思路是将原来的只有一个并行度增加到多个并行度
所以使用partitionColumn, lowerBound, upperBound和numPartitions这四个参数进行调优,注意要对分区字段值数据有一定了解,选择合适的分区字段和lowerBound, upperBound很关键。当然这样并行加载数据源也将并行初始化多个连接,Spark源码中提醒到不要并行度过大,否则容易把外部存储搞垮。
partitionColumn, lowerBound, upperBound和numPartitions这四个参数能决定Spark读取JDBC数据源的并行度及策略,lowerBound是分区字段取值的下限(包含),upperBound是上限(不包含),numPatitions是我们希望按照多少分区来加载JDBC。
注意第0个分区和最后一个分区加载的数据不被lowerBound, upperBound所限制,仍然会把所有数据加载出来。
具体实现逻辑可以看Spark中JdbcRelationProvider和JDBCRelation两个核心类。
根据配置样例SeaTunnel-JDBC-Example 修改配置如下:
spark {
spark.app.name = "impala-jdbc-2-clickhouse-jdbc"
spark.executor.instances = 5
spark.executor.cores = 2
# 每个excutor内存
spark.executor.memory = "2g"
}
input {
jdbc {
driver = "com.cloudera.impala.jdbc41.Driver"
url = "jdbc:impala://impalad_ip:21050/default"
table = "(select * from qjj_test) as source_table"
# 或者直接写表名也可以table = "qjj_test"
result_table_name = "impala_table_source"
user = ""
password = ""
jdbc.partitionColumn = "id"
jdbc.numPartitions = "20"
jdbc.lowerBound = 0
jdbc.upperBound = 2000000
}
}
filter {
}
output {
clickhouse {
source_table_name="impala_table_source"
host = "ch_jdbc_ip:8123"
clickhouse.socket_timeout = 50000
database = "default"
table = "qjj_test"
username = "default"
password = "123456"
# 每批次写入ClickHouse数据条数
bulk_size = 20000
}
}再次执行,观察WebUI发现并行度已经提高了,写入速度也变快了。
跑到后面发现有发生数据倾斜,可能是因partitionColumn参数设置不合理导致数据倾斜,要注意尽量选择不同范围数据分布均匀的字段作为分区字段,否则极易发生数据倾斜。但通过观察原表数据,发现没有数据在不同范围内分布均匀的字段,所以需要自己造一个分布均匀的字段。可以对字段做MOD(ASCII(SUBSTR(字段名,-1)), 分区数)操作。
修改配置如下:
spark {
spark.app.name = "impala-jdbc-2-clickhouse-jdbc"
# 提高了分区数 相应的在jdbc允许的jdbc连接数范围内调大executor核数 以更高的并行度跑数据
spark.executor.instances = 30
spark.executor.cores = 2
# 每个excutor内存
spark.executor.memory = "2g"
}
input {
jdbc {
driver = "com.cloudera.impala.jdbc41.Driver"
url = "jdbc:impala://impalad_ip:21050/default"
# 注意table的值是交给数据源jdbc去运行的而非Spark,不能使用SparkSQL函数,只能使用数据源支持的函数 次数将数据打散成300个区 可以使用不同的数据打散方式 最好先groupby测一下是否将数据均匀打散
table = "(select id,name,(cast(rand() * 300 as int)) as spark_partition_column from qjj_test) as source_table"
result_table_name = "impala_table_source"
user = ""
password = ""
jdbc.partitionColumn = "spark_partition_column"
jdbc.numPartitions = "300"
jdbc.lowerBound = 0
jdbc.upperBound = 300
}
}
filter {
sql {
# 上面处理后多出来个字段,忽略掉该字段
sql = "select id,name from impala_table_source"
}
}
output {
clickhouse {
# source_table_name="impala_table_source"
host = "ch_jdbc_ip:8123"
clickhouse.socket_timeout = 50000
database = "default"
table = "qjj_test"
username = "default"
password = "123456"
# 每批次写入ClickHouse数据条数
bulk_size = 20000
}
}对于使用Impala JDBC进行数据抽取的情况,查询的并行度需要根据服务器数量和资源情况设置,连接并行度不应过大,Impalad对单池内存大小有限制。并行度太高会报如下错误:
Caused by: java.sql.SQLException: [Cloudera][ImpalaJDBCDriver](500051) ERROR processing query/statement. Error Code: 0, SQL state: ExecQueryFInstances rpc query_id=42464c52f2e2c5dc:fe9ecfe800000000 failed: Failed to get minimum memory reservation of 272.00 MB on daemon data02.smycluster.sa:22000 for query 42464c52f2e2c5dc:fe9ecfe800000000 due to following error: Failed to increase reservation by 272.00 MB because it would exceed the applicable reservation limit for the "Process" ReservationTracker: reservation_limit=39.10 GB reservation=38.91 GB used_reservation=0 child_reservations=38.91 GB
The top 5 queries that allocated memory under this tracker are:
Query(8a4d40e3a6968443:7ae87ca100000000): Reservation=28.67 GB ReservationLimit=36.80 GB OtherMemory=21.24 MB Total=28.69 GB Peak=28.79 GB
Query(bb4dc7b08c698bc3:f4036eb000000000): Reservation=1.06 GB ReservationLimit=36.80 GB OtherMemory=93.62 MB Total=1.15 GB Peak=2.39 GB
Query(8a41df2c931faaec:ae30808c00000000): Reservation=1.06 GB ReservationLimit=36.80 GB OtherMemory=68.75 MB Total=1.13 GB Peak=1.37 GB
Query(604eddfbd1fd2de5:b7493a7400000000): Reservation=1.06 GB ReservationLimit=36.80 GB OtherMemory=66.37 MB Total=1.13 GB Peak=1.38 GB
Query(4c4ff283b5e12385:903c399c00000000): Reservation=1.06 GB ReservationLimit=36.80 GB OtherMemory=47.71 MB Total=1.11 GB Peak=1.39 GB
Memory is likely oversubscribed. Reducing query concurrency or configuring admission control may help avoid this error.在海量数据且资源配置不佳的情况下,使用Impala JDBC导出数据并不是很好的选择,Impala本身不适合跑批,跑批稳定性差,无容错机制。
对于这样的场景可以将Impala表数据导出成Parquet文件,再Load到ClickHouse。也可以导出Parquet表到HDFS,再使用ClickHouse映射HDFS引擎表从而获取数据。
org.apache.kudu.client.NonRecoverableException: Scanner 10150be3c0b944829d4eea1bc2251e24 not found (it may have expired)原因及解决:通常我们需要知道,当带宽占用接近总带宽的90%时,丢包情形就会发生。网络策略有问题或者带宽过低,对带宽做了限制,都会导致这样的问题,取消限制即可。若担心带宽问题,可以适当降低并行度抽取。
2022.1月-SeaTunnel正式进入Apache孵化器,我认为这是个比较优秀的项目,是个低代码实现数据抽取的高效平台,有兴趣可以多关注这个项目。
参考:
SeaTunnel-github
SeaTunnel-docs-configuration
使用WaterDrop将Kudu数据抽取到Clickhouse



