







Kyuubi原理与替代SparkThriftServer实践-基于CDH6

前言
Spark ThriftServer原生不支持多租户、权限管理、且稳定性一般,即使我们在源码基础上做了很多权限管控、SQL日志审计、数据脱敏以及性能优化,但由于它自身的稳定性和单点问题,仍然会经常造成调度、分析任务的失败。常见的一些问题有:
- Driver端单点故障导致整个调度失败
- 单个大Query占用大量并行度,导致后续任务缓慢或持续等待
- 单个Job发生数据倾斜时,会拖慢该Job的Task所在的Executor,影响其他Job
- 定期重启以避免Kerberos凭据过期
- 通过源码二次开发才能实现的用户权限管理、多租户管理
- 资源申请和释放粒度较粗,导致资源利用浪费或不充分
- 对不同负载任务启动多个Thrift实例,才能实现粗粒度的资源隔离,实例越多,维护起来越繁琐
针对以上痛点,网易贡献了Kyuubi这个项目,非常适合替换掉原有的SparkThriftServer服务,解决以上痛点的同时,还支持了异构计算引擎(Flink、Trino等)。当前(2022.5)该项目还在Apache孵化器进行孵化,在我看来是个比较有前景的项目。
Kyuubi是什么
网易数帆开源的一款支持多租户资源隔离、细粒度的行级、列级权限管理、支持高可用和负载均衡的统一分析引擎,可以通过SQL、Scala完成ETL、数据处理跑批、分析等多种任务负载。
Kyuubi的愿景是建立在Apache Spark和Data Lake技术之上,理想的统一数据湖管理平台。支持纯SQL方式处理数据,实现在同统一平台上使用一份数据副本和一个SQL接口,完成ETL、分析、BI……等工作。
Kyuubi对比SparkThriftServer的优势
| Kyuubi | SparkThriftServer | |
|---|---|---|
| 资源隔离 | 支持资源隔离 | STS是单个Application,只能提交到一个Yarn Queue;虽然Spark本身也具有一定资源共享能力——FairScheduler通过设置spark.scheduler.pool资源池优先级来为不同用户分配不同资源,但内存IO和CPU等资源的隔离本身应是资源调度系统Yarn或K8S该做的事儿 |
| 并发和扩展能力 | 支持无限水平扩展的多客户端并发能力,可自动扩展的查询并发能力,慢SQL影响小 | 单个STS并发查询能力有限、并发高时就会出现资源紧张,资源抢占,任务等待、卡死,且Driver单点瓶颈明显,慢SQL影响大 |
| 资源伸缩性 | 两级弹性资源管理(Kyuubi的资源弹性管理支持自动申请和释放Spark实例+Spark应用自身动态资源管理) | Spark自身动态资源管理 |
| 授权控制 | 支持数据和元数据的访问权限控制,支持基于Ranger细粒度授权,保证数据安全 | STS是单用户启动的,只有粗粒度授权,无法保证数据安全 |
| 实例管理 | 支持连接级别、用户级别、服务级别和组级别的SparkApplication实例申请 | 单个SparkApplication实例 |
| 执行引擎 | Spark、Flink、Trino(Presto) | Spark |
| 用户语言 | Scala+SQL灵活混合使用 | SQL |
| 存储引擎 | Hive+Kudu+DeltaLake+Azure+Presto | Hive+DeltaLake |
| 高可用性 | 原生基于ZK和Yarn的高可用,KyuubiServer本身支持水平扩展高可用 | 原生不支持,需要手动配置LoadBalancer,但发生切换时视图、hivevar变量、缓存等状态会丢失 |
| 系统架构 |  |
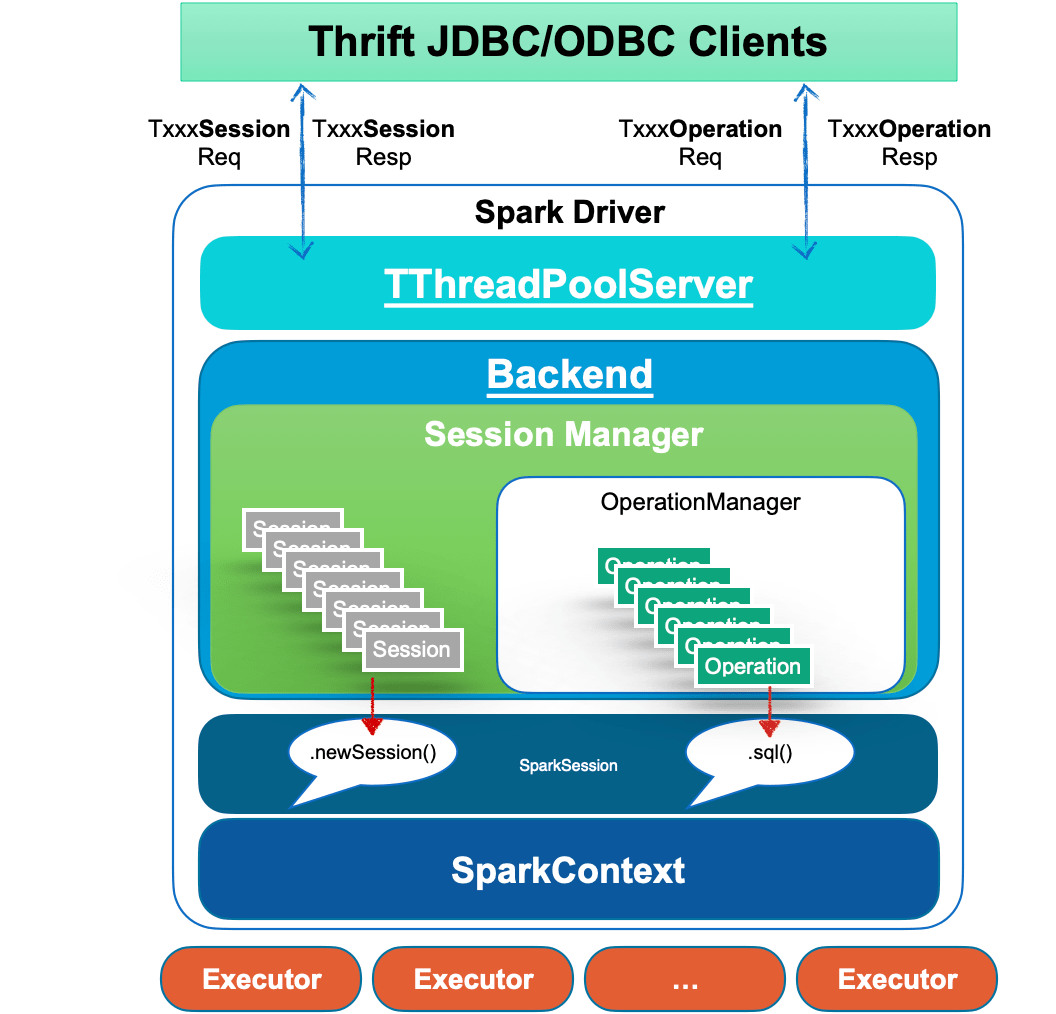 |
Kyuubi原理
Kyuubi架构图
在Kyuubi中,客户端的连接是作为KyuubiSession来维护的。
Kyuubi Session的创建可以分为轻量级和重量级两种情况。大多数会话创建都是轻量级、用户无感知的。唯一的重量级情况是用户的共享域中没有实例化或缓存的SparkContext,这种情况通常发生在用户第一次连接或长时间未连接时。这种一次性创建会话的成本,在多数AdHoc场景下也能接受。
Kyuubi维护SparkContext的方式是松散耦合的,这些SparkContext既可以是本地Client模式创建的,也可以是Yarn、K8S集群上的Cluster模式创建的。高可用模式下,SparkContext也可以由其他机器上的Kyuubi实例创建并共享出来。
Kyuubi可以创建和托管多个SparkContexts实例,它们有自己的生命周期,一定条件下会被自动创建和回收,如果一段时间没有任务负载,资源会全部释放。SparkContext的状态不受Kyuubi进程故障转移的影响。
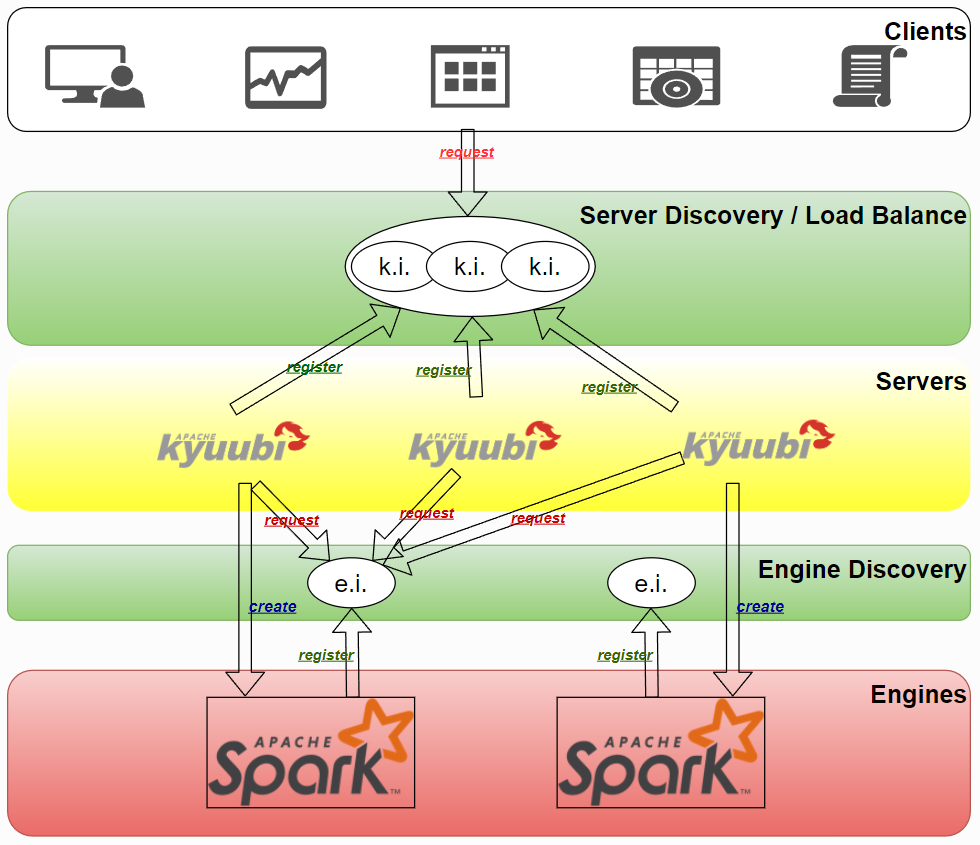
Kyuubi支持不同共享级别的引擎共享。如果设置了USER级别的share.level,同一用户与Kyuubi建立的多个连接会复用同一个Engine,实现用户级别的资源隔离。
Kyuubi资源隔离共享级别
| 共享级别 | 参数 | 图解 | 说明 |
|---|---|---|---|
| CONNECTION | kyuubi.engine.share.level=CONNECTION | 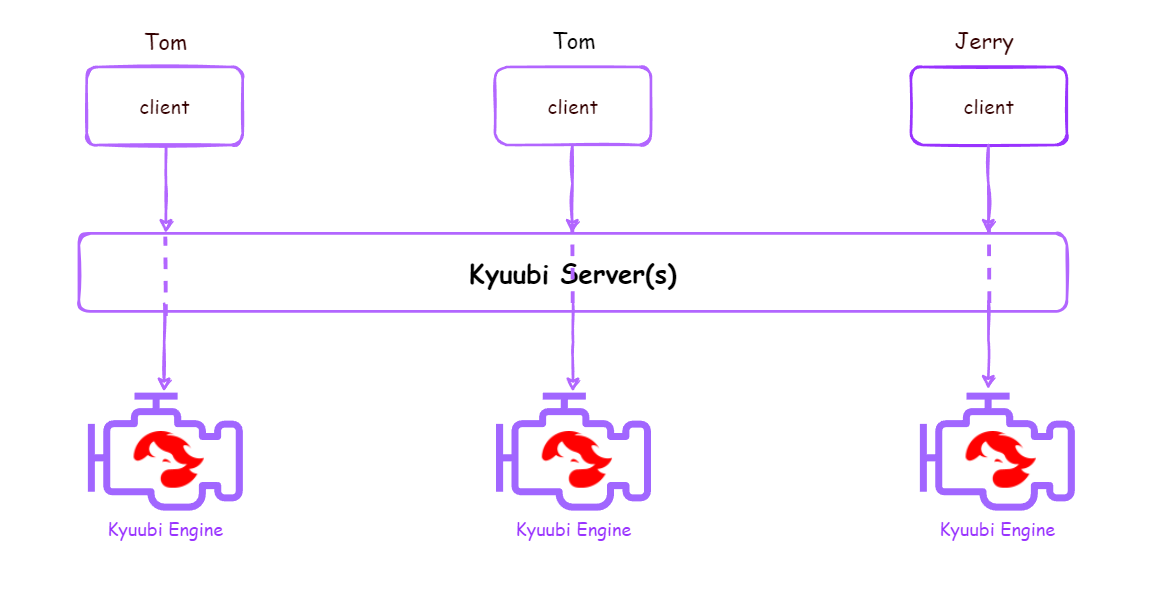 |
每个连接都创建一个独立的Engine,连接创建即申请Engine,连接关闭即释放Engine |
| USER | kyuubi.engine.share.level=USER | 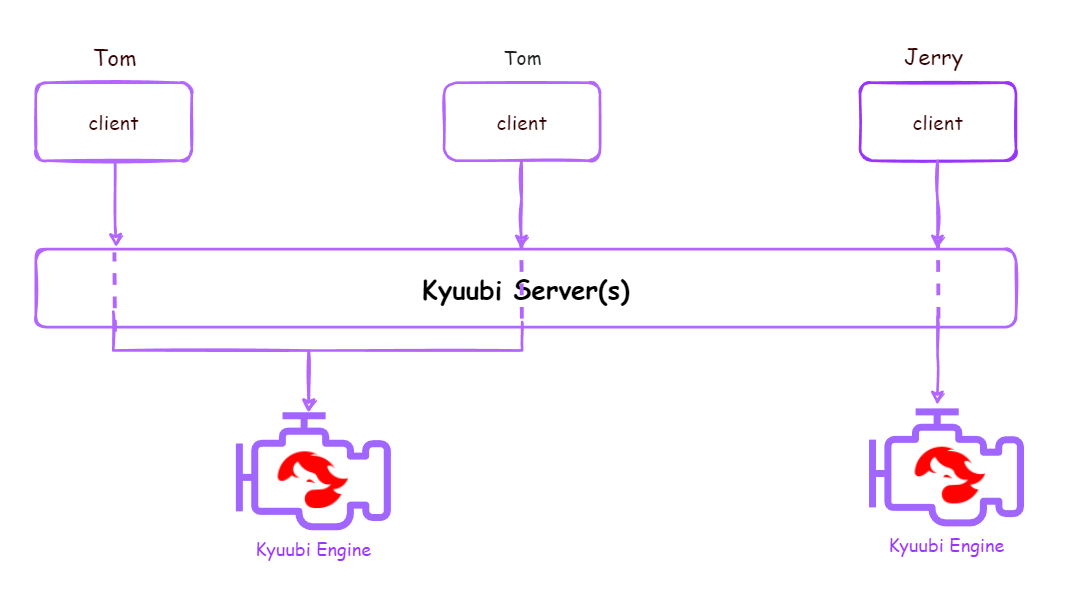 |
同一用户的多个连接共享一个Engine,一个用户对应一个Engine,用户连接关闭后不会立刻释放Engine,在无操作达到TTL后释放Engine |
| GROUP | kyuubi.engine.share.level=GROUP | 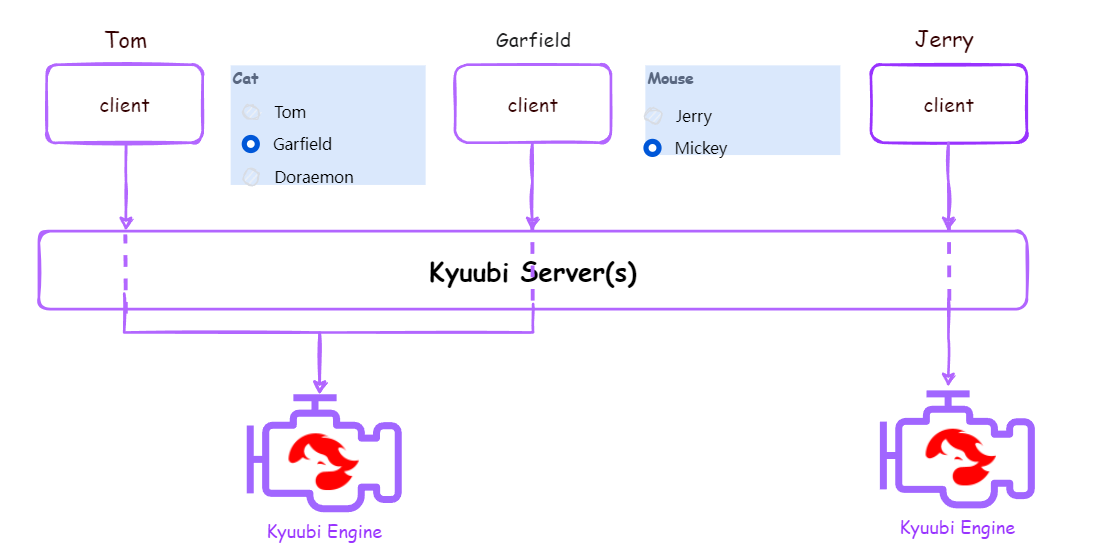 |
属于相同组的所有用户创建的所有连接共享同一个Engine,以组名作为启动Engine的用户名,数据权限按组进行管理,如果组名不存在,共享级别降级为USER,用户组遵循Hadoop Groups Mapping,可以通过配置把不同用户映射到一个组。相比USER级别给每个用户都创建引擎,GROUP级别可以减少引擎实例数,节约资源,但引擎是共享的,同组所有用户都复用这个引擎,访问权限控制若要做到细粒度,则需要结合Apache Ranger,资源控制的细粒度需要结合SparkFairScheduler |
| SERVER | kyuubi.engine.share.level=SERVER | 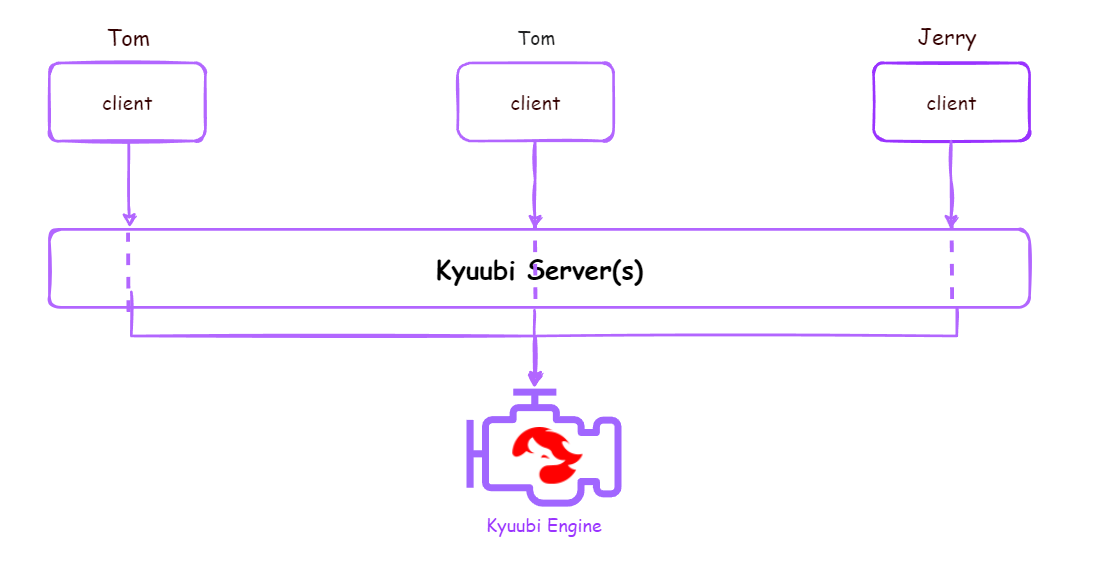 |
每个KyuubiServer中的连接共用一个Engine,类似原生ThriftServer的高可用版本 |
| 一个KyuubiServer中可以混用多种隔离级别。 |
比如正常情况下引擎共享级别设置为GROUP,同一个组下的用户只能申请一个引擎;当组里用户太多时,单个引擎也会出现并发瓶颈和资源抢占,针对这种问题,Kyuubi中引入了Subdomain的概念,引擎共享子域(kyuubi.engine.share.level.subdomain)是对引擎资源隔离共享级别的补充,能实现同一个用户、组创建多个引擎。
Kyuubi的JDBC连接串模板:jdbc:hive2://kyuubi-server-ip:10009/default;?conf1=val1;conf2=var2;…;confN=varN
Kyuubi的JDBC连接串示例:jdbc:hive2://kyuubi-server-ip:10009/default;?spark.driver.memory=5G;spark.app.name=qjj_kyuubi_application
Subdomain的使用:
beeline -u "jdbc:hive2://kyuubi-server-ip:10009/default;?spark.app.name=qjj_kyuubi_sd1;spark.driver.memory=4G;kyuubi.engine.share.level=USER;kyuubi.engine.share.level.subdomain=sd1" -nq00885 -p******
beeline -u "jdbc:hive2://kyuubi-server-ip:10009/default;?spark.app.name=qjj_kyuubi_sd2;spark.driver.memory=2G;kyuubi.engine.share.level=USER;kyuubi.engine.share.level.subdomain=sd2" -nq00885 -p******可以看到单个用户启动了两个Engine
如果我想创建一个连接复用之前的sd2这个Subdomain,就可以通过以下指定Subdomain的方式进行指定。
beeline -u "jdbc:hive2://kyuubi-server-ip:10009/default;?kyuubi.engine.share.level=USER;kyuubi.engine.share.level.subdomain=sd2" -nq00885 -p******Kyuubi HA
Kyuubi基于ZK实现高可用和负载均衡:
KyuubiServer启动会到ZK注册节点,实现KyuubiServer之间负载均衡和高可用
每个用户登录默认是default子域,每个子域注册一个永久节点,子域下面申请的Engine会注册临时节点,将Engine信息写入ZK。此外还通过ZK存放一些用户的锁和租约信息。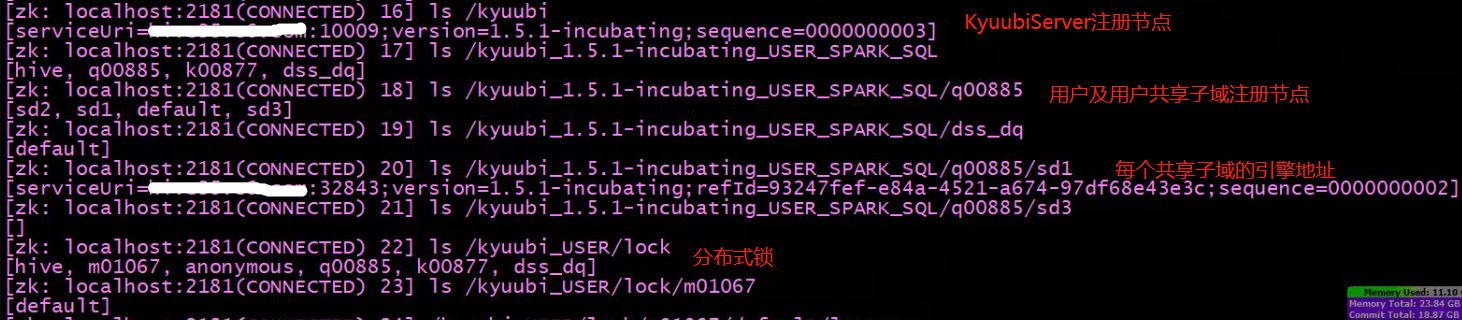
Kyuubi监控
Kyuubi本身支持监控,配置方法参考:Monitoring Kyuubi - Server Metrics
部署Kyuubi On CDH6.3.2
Spark 3.2.2 On CDH6.3.2编译与部署
源码准备
# Windows下进入wsl环境(Windows的Linux子系统)
wsl
# 下载Spark源码
git clone https://github.com/apache/spark.git
# 切换到spark3.2分支并创建新分支branch-3.2-cdh6.3.2
cd spark
git checkout branch-3.2
git checkout -b branch-3.2-cdh6.3.2pom修改
<!-- 增加Cloudera源 -->
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<name>Cloudera Repositories</name>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<pluginRepository>
<id>cloudera</id>
<name>Cloudera Repositories</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</pluginRepository>
<!-- 增加hadoop3 profile -->
<profile>
<id>hadoop-3.0</id>
<properties>
<hadoop.version>3.0.0-cdh6.3.2</hadoop.version>
</properties>
</profile>编译
# 转换/r/n为unix系统可正常运行的/n (CRLF转LF)
sudo apt install dos2unix
dos2unix ./dev/*.sh
dos2unix ./build/*
# 编译 看能否编译通过:
mvn -Pyarn -Dhadoop.version=3.0.0-cdh6.3.2 -Phadoop-3.0 -Phive-thriftserver -DskipTests clean package --settings "/mnt/d/Applications/apache-maven-3.6.3/conf/settings.xml" -Dmaven.repo.local="/mnt/e/Maven/Repository"
# 编译&打包 将源码编译为binary包 生成spark-3.2.2-SNAPSHOT-bin-hadoop-3.0.0-cdh6.3.2.tgz安装包:
./dev/make-distribution.sh --name hadoop-3.0.0-cdh6.3.2 --tgz -Phadoop-3.0 -Pyarn -Phive-thriftserver -DskipTests --settings "/mnt/d/Applications/apache-maven-3.6.3/conf/settings.xml" -Dmaven.repo.local="/mnt/e/Maven/Repository"部署
tar -zxvf spark-3.2.2-SNAPSHOT-bin-hadoop-3.0.0-cdh6.3.2.tgz -C ../../
mv spark-3.2.2-SNAPSHOT-bin-hadoop-3.0.0-cdh6.3.2 spark-3.2.2-bin-hadoop-3.0.0-cdh6.3.2
cd spark-3.2.2-bin-hadoop-3.0.0-cdh6.3.2
cd conf
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh
# 修改spark-defaults.conf (参数生效优先级: SparkConf > spark-submit Flags > spark-defaults.conf)
vim spark-defaults.conf
## Java设置
spark.executorEnv.JAVA_HOME /usr/java/jdk1.8.0_181
spark.yarn.appMasterEnv.JAVA_HOME /usr/java/jdk1.8.0_181
## 开启eventLog用于重构历史已完成任务的WebUI
spark.eventLog.enabled true
spark.eventLog.dir hdfs:///user/spark/applicationHistory
spark.eventLog.compress true
spark.driver.log.dfsDir /user/spark/driverLogs (持久化driver日志的路径)
spark.driver.log.persistToDfs.enabled true (持久化driver日志)
spark.history.fs.cleaner.enabled true (定期自动清理日志目录,默认一天清理一次,清理7天前的日志文件)
spark.history.fs.logDirectory hdfs:///user/spark/applicationHistory
spark.history.ui.port 18080 (访问Spark应用历史记录http://historyServerHost:18080/)
spark.history.retainedApplications 30 (缓存中保存的应用历史记录个数,超过会将旧的删除,读更早的日志去磁盘读会慢些)
spark.yarn.historyServer.address http://cdh101:18080 (Yarn Application页面Tracking URL链接可以直接进入HistoryServer查看日志)
spark.yarn.historyServer.allowTracking true (Yarn Application页面Tracking URL链接可以直接进入HistoryServer查看日志)
## local.dir设置为数据盘,避免使用系统分区
spark.local.dir /tmp/spark_temp_data
## 优化设置
spark.kryoserializer.buffer.max 512m
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.authenticate false (关闭数据块传输服务SASL加密认证)
spark.io.encryption.enabled false (关闭I/O加密)
spark.network.crypto.enabled false (关闭基于AES算法的RPC加密)
spark.shuffle.service.enabled true (启用外部ShuffleService提高Shuffle稳定性)
spark.shuffle.service.port 7337 (这个外部ShuffleService由YarnNodeManager提供,默认端口7337)
spark.shuffle.useOldFetchProtocol true (兼容旧的Shuffle协议避免报错)
spark.sql.cbo.enabled true (启用CBO基于代价的优化-代替RBO基于规则的优化-Optimizer)
spark.sql.cbo.starSchemaDetection true (星型模型探测,判断列是否是表的主键)
spark.sql.datetime.java8API.enabled false
spark.sql.sources.partitionOverwriteMode dynamic
spark.sql.orc.mergeSchema true (ORC格式Schema加载时从所有数据文件收集)
spark.sql.parquet.mergeSchema false (根据情况设置,我们集群大多数都是parquet,从所有文件收集Schema会影响性能,所以从随机一个Parquet文件收集Schema)
spark.sql.parquet.writeLegacyFormat true (兼容旧集群)
spark.sql.autoBroadcastJoinThreshold 1048576 (当前仅支持运行了ANALYZE TABLE <tableName> COMPUTE STATISTICS noscan的Hive Metastore表,以及直接在数据文件上计算统计信息的基于文件的数据源表)
spark.sql.adaptive.enabled true (Spark AQE[adaptive query execution]启用,AQE的优势:执行计划可动态调整、调整的依据是中间结果的精确统计信息)
spark.sql.adaptive.forceApply false
spark.sql.adaptive.logLevel info
spark.sql.adaptive.advisoryPartitionSizeInBytes 256m (倾斜数据分区拆分,小数据分区合并优化时,建议的分区大小,与spark.sql.adaptive.shuffle.targetPostShuffleInputSize含义相同)
spark.sql.adaptive.coalescePartitions.enabled true (是否开启合并小数据分区默认开启,调优策略之一)
spark.sql.adaptive.coalescePartitions.minPartitionSize 1m (合并后最小的分区大小)
spark.sql.adaptive.coalescePartitions.initialPartitionNum 1024 (合并前的初始分区数)
spark.sql.adaptive.fetchShuffleBlocksInBatch true (是否批量拉取blocks,而不是一个个的去取,给同一个map任务一次性批量拉取blocks可以减少io 提高性能)
spark.sql.adaptive.localShuffleReader.enabled true (不需要Shuffle操作时,使用LocalShuffleReader,例如将SortMergeJoin转为BrocastJoin)
spark.sql.adaptive.skewJoin.enabled true (Spark会通过拆分的方式自动处理Join过程中有数据倾斜的分区)
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 128m
spark.sql.adaptive.skewJoin.skewedPartitionFactor 5 (判断倾斜的条件:分区大小大于所有分区大小中位数的5倍,且大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes的值)
## 默认应用资源设置
spark.driver.memory 2G
spark.executor.cores 4
spark.executor.memory 4G
spark.executor.memoryOverhead 2G
spark.memory.offHeap.enabled true
spark.memory.offHeap.size 2G
## 动态资源设置 具体逻辑见ExecutorAllocationManager这个类
spark.dynamicAllocation.enabled true
spark.dynamicAllocation.executorIdleTimeout 60 (executor闲置时间,如果某executor空闲超过60s,则remove此executor)
spark.dynamicAllocation.minExecutors 0
spark.dynamicAllocation.schedulerBacklogTimeout 5s (如果有pending task并且等待了5s,则申请增加executor)
spark.dynamicAllocation.cachedExecutorIdleTimeout 600 (cache闲置时间,超过此时间,可释放cache所在的executor)
## 其他设置
spark.driver.extraLibraryPath /opt/cloudera/parcels/CDH/lib/hadoop/lib/native
spark.executor.extraLibraryPath /opt/cloudera/parcels/CDH/lib/hadoop/lib/native
spark.yarn.am.extraLibraryPath /opt/cloudera/parcels/CDH/lib/hadoop/lib/native
spark.ui.enabled true
spark.ui.killEnabled true
spark.master yarn
spark.sql.hive.metastore.version 2.1.1
spark.sql.hive.metastore.jars /opt/cloudera/parcels/CDH/lib/hive/lib/*
# 修改spark-env.sh
vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181
HADOOP_CONF_DIR=/etc/hadoop/conf
export SPARK_DIST_CLASSPATH=$(/opt/cloudera/parcels/CDH/bin/hadoop classpath)
export SPARK_LOCAL_DIRS=/tmp/spark_temp_data
# 软连接hive和hdfs、yarn配置:
ln -s /etc/hadoop/conf/core-site.xml core-site.xml
ln -s /etc/hbase/conf/hbase-site.xml hbase-site.xml
ln -s /etc/hadoop/conf/hdfs-site.xml hdfs-site.xml
ln -s /etc/hive/conf/hive-site.xml hive-site.xml
ln -s /etc/hadoop/conf/mapred-site.xml mapred-site.xml
ln -s /etc/hadoop/conf/yarn-site.xml yarn-site.xml
# 将CRLF转LF以保证运行正常
cd spark-3.2.2-bin-hadoop-3.0.0-cdh6.3.2
sudo yum -y install dos2unix
dos2unix bin/*
dos2unix sbin/*
dos2unix conf/*
dos2unix python/*
# 运行SparkHistoryServer (注意该进程会产生日志,为避免占用系统分区空间,尽量将$SPARK_HOME/logs软连接到数据盘)
sbin/start-history-server.sh
# 运行SparkSQL on Yarn
bin/spark-sql --master yarn 至此Spark3.2.2 On CDH6.3.2编译部署完毕
注意Yarn外部ShuffleService一定确保开启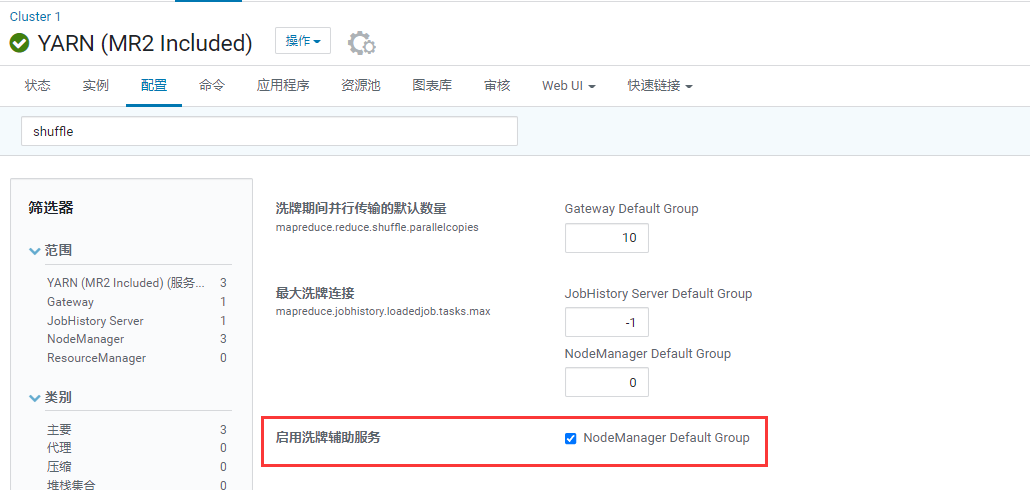
Kyuubi On Spark3基础部署
更多配置参考:Kyuubi-Deployment-Settings
安装与配置Kyuubi
wget https://www.apache.org/dyn/closer.lua/incubator/kyuubi/kyuubi-1.5.1-incubating/apache-kyuubi-1.5.1-incubating-bin.tgz
tar -zxvf apache-kyuubi-1.5.1-incubating-bin.tgz -C /opt/modules/
# 设置环境变量 vim /etc/profile
# KYUUBI_HOME
export KYUUBI_HOME=/opt/modules/apache-kyuubi-1.5.1-incubating-bin
# 配置文件修改
cd apache-kyuubi-1.5.1-incubating-bin
cd conf
cp kyuubi-env.sh.template kyuubi-env.sh;cp kyuubi-defaults.conf.template kyuubi-defaults.conf;cp log4j2.properties.template log4j2.properties
# 修改kyuubi-env.sh
vim kyuubi-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181
export SPARK_HOME=/opt/modules/spark-3.2.2-bin-hadoop-3.0.0-cdh6.3.2
export HADOOP_CONF_DIR=/etc/hive/conf
export KYUUBI_JAVA_OPTS="-Xmx4g -XX:+UnlockDiagnosticVMOptions -XX:ParGCCardsPerStrideChunk=4096 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSConcurrentMTEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+CMSClassUnloadingEnabled -XX:+CMSParallelRemarkEnabled -XX:+UseCondCardMark -XX:MaxDirectMemorySize=1024m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./logs -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -Xloggc:./logs/kyuubi-server-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=5M -XX:NewRatio=3 -XX:MetaspaceSize=512m"
# 修改kyuubi-defaults.conf (由于我之前的Spark安装中已经配置了hive-site等配置,这里不需要指定hive相关配置了,正常这里是可以指定hive配置的,参考https://kyuubi.apache.org/docs/latest/deployment/hive_metastore.html)
vim kyuubi-defaults.conf
spark.master=yarn
kyuubi.ha.zookeeper.acl.enabled=true
kyuubi.ha.zookeeper.quorum=cdh101:2181,cdh102:2181,cdh103:2181
kyuubi.engine.share.level=USER
kyuubi.session.engine.idle.timeout=PT1H
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.minExecutors=1
spark.dynamicAllocation.maxExecutors=10
spark.dynamicAllocation.executorIdleTimeout=120启动与连接Kyuubi
# 启动Kyuubi Server
bin/kyuubi start
# 使用hive用户 连接Kyuubi
beeline -u jdbc:hive2://10.2.5.101:10009 -n hive
show databases # 该命令直接触发Spark引擎初始化至此Kyuubi基础配置完成
Kyuubi申请到Spark引擎后,默认空闲30min后自动回收。
Kyuubi生产环境的高级配置
在上面基础配置的基础上增加生产环境所需的高级配置,包括安全性配置,用户的配置,授权配置等。
Kerberos认证
kyuubi.kinit.keytab=/hadoop/bigdata/kerberos/keytab/hive.keytab
kyuubi.kinit.principal=hive/xxx@XXX.COM采用LDAP认证 使用LDAP认证登陆Kyuubi
kyuubi.authentication=LDAP
kyuubi.authentication.ldap.base.dn=ou=People,dc=xxx,dc=xxx,dc=xxx
kyuubi.authentication.ldap.guidKey=uid
#kyuubi.authentication.ldap.domain=xxx.xxx.com
kyuubi.authentication.ldap.url=ldap://ldap_addr:389使用q00885用户登陆,执行sql查询,后台会以q00885申请一个SparkApplication。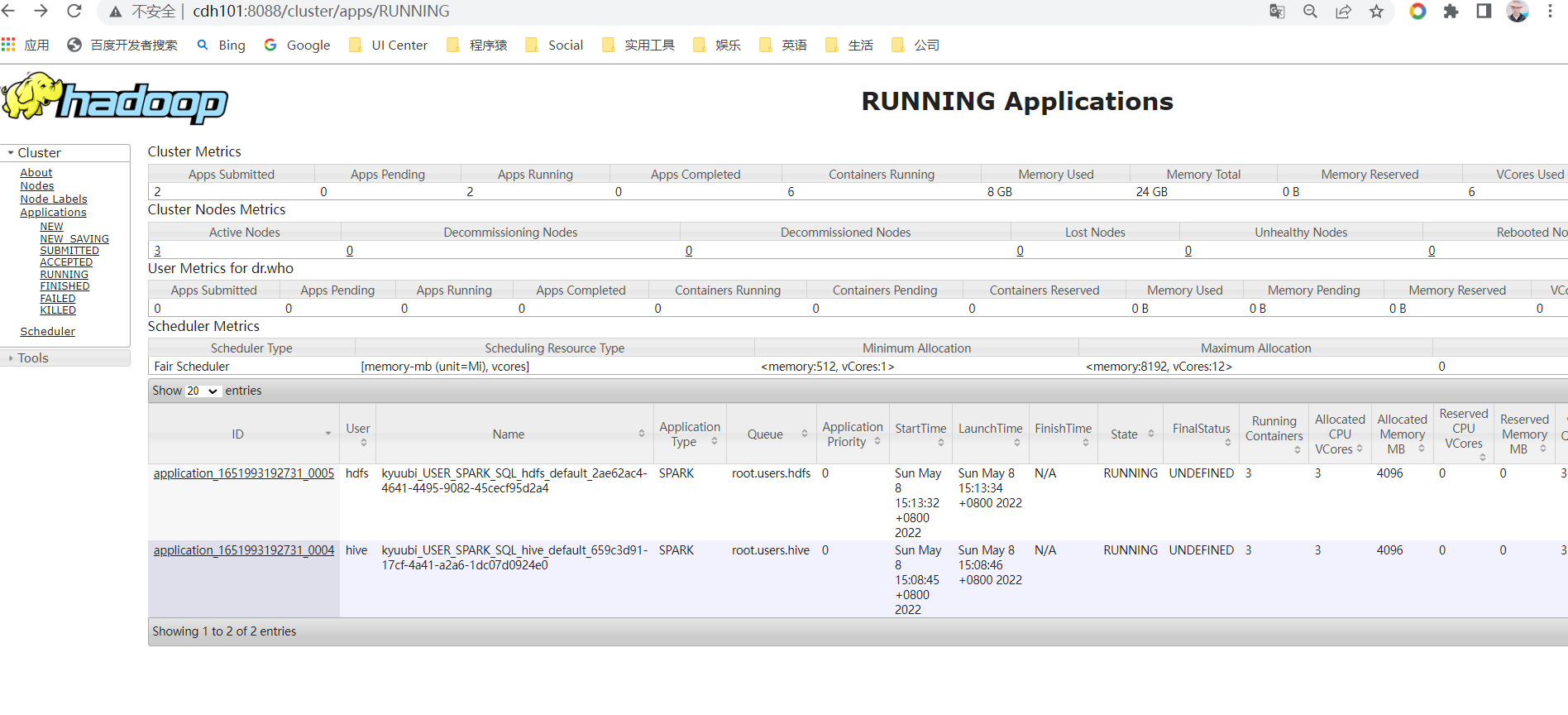
查询时,数据访问、元数据访问都使用这个用户,要确保这个用户有HDFS上ACL权限(hdfs dfs -getfacl查看)。
还要确保Linux上有该用户,否则引擎无法申请成功。
如果没有HDFS上的ACL权限,可以通过setfacl设置ACL,或者通过hive的grant命令针对组批量授权。
Scala+SQL混合使用
beeline -u jdbc:hive2://kyuubi-server-ip:10009/default -n q00885 -p xxx 登陆后默认是SQL模式
CREATE TEMPORARY VIEW qjj_view as select * from qjj_test;
set kyuubi.operation.language=scala;
val df = spark.table("qjj_view").where("id > 2 and id < 5");
df.registerTempTable("qjj_view1")
spark.sql("set kyuubi.operation.language=sql");
select count(1),min(id),max(id) from qjj_view1;集成Kudu
Kyuubi的授权:
Kyuuib当前支持三种授权:
1.基于存储层面的授权(以上我们使用到的授权方式)
2.基于SQL标准的授权类似HiveServer2(基于Submarine:Spark Security外部插件)
3.基于Ranger(官网推荐,也是基于Submarine Spark,只是通过Spark-Ranger来实现更细粒度的访问授权)
问题与异常处理
执行spark sql后一直卡住,后台报错User: root is not allowed to impersonate anonymous
Error: org.apache.kyuubi.KyuubiSQLException: Timeout(180000 ms) to launched SPARK_SQL engine with /opt/modules/spark-3.2.2-bin-hadoop-3.0.0-cdh6.3.2/bin/spark-submit \ --class org.apache.kyuubi.engine.spark.SparkSQLEngine \ --conf spark.kyuubi.ha.zookeeper.quorum=cdh101:2181,cdh102:2181,cdh103:2181 \ --conf spark.kyuubi.client.ip=10.2.5.101 \ --conf spark.hive.query.redaction.rules=/etc/alternatives/hive-conf/redaction-rules.json \ --conf spark.kyuubi.engine.submit.time=1651991699800 \ --conf spark.app.name=kyuubi_USER_SPARK_SQL_anonymous_default_a0c93d16-2718-4791-8205-97fbc35e652a \ --conf spark.kyuubi.ha.zookeeper.acl.enabled=true \ --conf spark.kyuubi.ha.engine.ref.id=a0c93d16-2718-4791-8205-97fbc35e652a \ --conf spark.kyuubi.ha.zookeeper.auth.type=NONE \ --conf spark.master=yarn \ --conf spark.yarn.tags=KYUUBI \ --conf spark.kyuubi.ha.zookeeper.namespace=/kyuubi_1.5.1-incubating_USER_SPARK_SQL/anonymous/default \ --conf spark.hive.exec.query.redactor.hooks=org.cloudera.hadoop.hive.ql.hooks.QueryRedactor \ --proxy-user anonymous /opt/modules/apache-kyuubi-1.5.1-incubating-bin/externals/engines/spark/kyuubi-spark-sql-engine_2.12-1.5.1-incubating.jar. (state=,code=0) ...... 22/05/08 14:37:17 INFO retry.RetryInvocationHandler: org.apache.hadoop.security.authorize.AuthorizationException: User: root is not allowed to impersonate anonymous, while invoking ApplicationClientProtocolPBClientImpl.getClusterMetrics over null after 5 failover attempts. Trying to failover after sleeping for 37639ms.解决:避免使用root用户启动Kyuubi Server。可使用hive、hdfs用户启动,或单独建立一个kyuubi用户启动KyuubiServer。
用户无目录以及NM节点没用户导致引擎无法运行
Caused by: org.apache.kyuubi.KyuubiSQLException: Timeout(180000 ms) to launched SPARK_SQL engine with /data3/bigdata/spark/spark-3.2.2-bin-hadoop-3.0.0-cdh6.3.2/bin/spark-submit \ --class org.apache.kyuubi.engine.spark.SparkSQLEngine \ --conf spark.kyuubi.authentication.ldap.url=ldap://xxx.xx.xxx.xx \ --conf spark.kyuubi.ha.zookeeper.quorum=zk1:2181,zk2:2181,zk3:2181 \ --conf spark.kyuubi.client.ip=xxx.xx.xxx.xx \ --conf spark.kyuubi.kinit.principal=hive/hive02.c6.com@XXX.COM \ --conf spark.kyuubi.engine.submit.time=1652671391562 \ --conf spark.app.name=kyuubi_USER_SPARK_SQL_k00877_default_ff13fda9-1a01-4322-8d40-d3bc098d78e4 \ --conf spark.kyuubi.ha.zookeeper.acl.enabled=true \ --conf spark.kyuubi.ha.engine.ref.id=ff13fda9-1a01-4322-8d40-d3bc098d78e4 \ --conf spark.master=yarn \ --conf spark.yarn.tags=KYUUBI \ --conf spark.kyuubi.ha.zookeeper.namespace=/kyuubi_1.5.1-incubating_USER_SPARK_SQL/k00877/default \ --conf spark.kyuubi.kinit.keytab=/hadoop/bigdata/kerberos/keytab/hiveserver2_hive02_c6.keytab \ --conf spark.kyuubi.authentication.ldap.domain=smyoa.com \ --proxy-user k00877 /data3/bigdata/spark/apache-kyuubi-1.5.1-incubating-bin/externals/engines/spark/kyuubi-spark-sql-engine_2.12-1.5.1-incubating.jar. at org.apache.kyuubi.KyuubiSQLException$.apply(KyuubiSQLException.scala:69) ~[kyuubi-common_2.12-1.5.1-incubating.jar:1.5.1-incubating] ...... Caused by: org.apache.kyuubi.KyuubiSQLException: org.apache.hadoop.security.AccessControlException: Permission denied: user=k00877, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:400) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:256) at org.apache.sentry.hdfs.SentryINodeAttributesProvider$SentryPermissionEnforcer.checkPermission(SentryINodeAttributesProvider.java:86) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:194)尝试在HDFS上创建对应用户目录 (这里也可以修改Spark在文件系统中当前用户的主目录-提交应用的缓存目录:spark.yarn.stagingDir)
hdfs dfs -mkdir /user/k00877/ hdfs dfs -chown k00877:k00877 /user/k00877/再次尝试创建引擎,报错如下
# Kyuubi Server error: Caused by: org.apache.kyuubi.KyuubiSQLException: org.apache.spark.SparkException: Application application_1637826239096_34377 failed 2 times due to AM Container for appattempt_1637826239096_34377_000002 exited with exitCode: -1000 See more: /hadoop/bigdata/spark/apache-kyuubi-1.5.1-incubating-bin/work/k00877/kyuubi-spark-sql-engine.log.4 at org.apache.kyuubi.KyuubiSQLException$.apply(KyuubiSQLException.scala:69) ~[kyuubi-common_2.12-1.5.1-incubating.jar:1.5.1-incubating] at org.apache.kyuubi.engine.ProcBuilder.$anonfun$start$1(ProcBuilder.scala:165) ~[kyuubi-server_2.12-1.5.1-incubating.jar:1.5.1-incubating] Engine log: /hadoop/bigdata/spark/apache-kyuubi-1.5.1-incubating-bin/work/k00877/kyuubi-spark-sql-engine.log.4 For more detailed output, check the application tracking page: http://xxxxx:8088/cluster/app/application_1637826239096_34377 Then click on links to logs of each attempt. . Failing the application. org.apache.spark.SparkException: Application application_1637826239096_34377 failed 2 times due to AM Container for appattempt_1637826239096_34377_000002 exited with exitCode: -1000 Failing this attempt.Diagnostics: [2022-05-16 13:00:12.276]Application application_1637826239096_34377 initialization failed (exitCode=255) with output: main : command provided 0 main : run as user is k00877 main : requested yarn user is k00877 User k00877 not found ......在一个没有开启Kerberos安全的集群里,启动container进程可以使用DefaultContainerExecutor或LinuxContainerExecutor;但是启用了Kerberos安全的集群里,启动container进程只能使用LinuxContainerExecutor,在底层会使用setuid切换到业务用户以启动container进程,所以要求所有nodemanager节点必须有业务用户。
可选方案: Ldap是支持管理Linux用户的,可以作为Linux自带用户的扩展,实现不用手动useradd就能在各节点以ldap中的用户模拟Linux用户启动Container.
临时解决:首先保证用户主目录有权限的前提下,在各个NodeManager节点创建k00877用户,创建后可以看到引擎正常启动
使用LDAP登录的用户无HDFS上表数据的访问权限
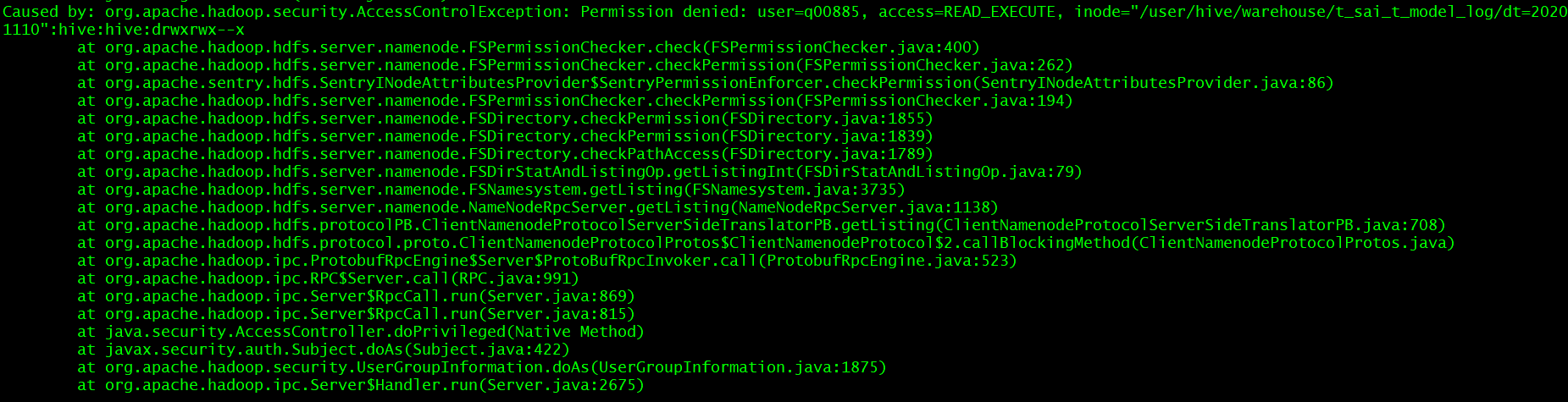
分析:需要确保当前用户的权限或者ACL权限是READ_EXECUTE
当前用户q00885没有该目录的任何读权限。解决方式:
使用hive用户登录HiveServer2:beeline -u "jdbc:hive2://kyuubi-server-ip:10000/default" -nhive -pxxxxx
查看q00885所属角色
SHOW ROLE GRANT GROUP group q00885;
+--------+---------------+-------------+----------+--+
| role | grant_option | grant_time | grantor |
+--------+---------------+-------------+----------+--+
| admin | false | 0 | -- |
| d_bd | false | 0 | -- |
+--------+---------------+-------------+----------+--+
授权权限给d_bd角色
grant select on table t_sai_t_model_log to role d_bd;
查看d_bd角色有哪些权限
SHOW GRANT ROLE d_bd;
+-------------------------------------+----------------------------------------+------------+---------+-----------------+-----------------+------------+---------------+----------------+----------+--+
| database | table | partition | column | principal_name | principal_type | privilege | grant_option | grant_time | grantor |
+-------------------------------------+----------------------------------------+------------+---------+-----------------+-----------------+------------+---------------+----------------+----------+--+
| default | xxxxxxxxxx | | | d_bd | ROLE | SELECT | false | 1629844007000 | -- |
| default | t_sai_t_model_log | | | d_bd | ROLE | SELECT | false | 1652777345000 | -- |
| default | xxxxxxxxxx | | | d_bd | ROLE | SELECT | false | 1634268085000 | -- |
+-------------------------------------+----------------------------------------+------------+---------+-----------------+-----------------+------------+---------------+----------------+----------+--+
先回收权限,测试另一种方法:设置acl
revoke select on table t_sai_t_model_log from role d_bd;
给表数据路径增加ACL权限
hdfs dfs -setfacl -R -m group:q00885:r-x /user/hive/warehouse/t_sai_t_model_log
设置ACL后再用getfacl查看ACL列表,设置没生效,是因为我们集群用了Sentry管理ACL,直接对目录设置ACL不会生效,所以还需使用hive的grant+revoke方式授权。再次使用q00885即可查询。
权限列表:
ALL SERVER, TABLE, DB, URI, COLLECTION, CONFIG
INSERT DB, TABLE
SELECT DB, TABLE, COLUMN
授权与回收:
GRANT ROLE <role name> [, <role name>] TO GROUP <group name> [,GROUP <group name>]
GRANT <privilege> [, <privilege> ] ON <object type> <object name> TO ROLE <role name> [,ROLE <role name>]
GRANT SELECT <column name> ON TABLE <table name> TO ROLE <role name>;
REVOKE ROLE <role name> [, <role name>] FROM GROUP <group name> [,GROUP <group name>]
REVOKE <privilege> [, <privilege> ] ON <object type> <object name> FROM ROLE <role name> [,ROLE <role name>]
REVOKE SELECT <column name> ON TABLE <table name> FROM ROLE <role name>;参考
Apache Kyuubi Documents
Apache Kyuubi Deployment Settings
Apache Spark Configuration
spark-history-server-configuration-options
SparkSQL的自适应执行
Migration Guide: SQL, Datasets and DataFrame



